
ETL significa Extrair, Transformar e Carregar. As ferramentas ETL extraem dados de várias fontes e os transformam em um formato intermediário adequado para sistemas de destino ou requisitos de modelo de dados. E, finalmente, eles carregam dados em um banco de dados de destino, data warehouse ou até mesmo data lake.
Lembro-me de tempos de 15 a 20 anos atrás, quando o termo ETL era algo que poucos entendiam o que é. Quando vários trabalhos em lote personalizados tiveram seu pico no hardware local.
Muitos projetos fizeram alguma forma de ETL. Mesmo que não soubessem, deveriam chamá-lo de ETL. Naquela época, sempre que eu explicava qualquer projeto que envolvia processos ETL, e os chamava e os descrevia dessa forma, parecia quase uma tecnologia de outro mundo, algo muito raro.
Mas hoje as coisas são diferentes. A migração para a nuvem é a principal prioridade. E as ferramentas ETL são a parte estratégica da arquitetura da maioria dos projetos.
No final das contas, migrar para a nuvem significa pegar os dados do local como fonte e transformá-los em bancos de dados na nuvem de uma forma que seja o mais compatível possível com a arquitetura da nuvem. Exatamente o trabalho da ferramenta ETL.
últimas postagens
História do ETL e como ele se conecta ao presente
Fonte: aws.amazon.com
As principais funções do ETL sempre foram as mesmas.
As ferramentas ETL extraem dados de várias fontes (sendo bancos de dados, arquivos simples, serviços da Web ou, ultimamente, aplicativos baseados em nuvem).
Geralmente significava pegar arquivos no sistema de arquivos Unix como entrada e pré-processamento, processamento e pós-processamento.
Você pode ver o padrão reutilizável de nomes de pastas como:
- Entrada
- Saída
- Erro
- Arquivo
Nessas pastas, também existia outra estrutura de subpastas, baseada principalmente em datas.
Essa era apenas a maneira padrão de processar os dados recebidos e prepará-los para serem carregados em algum tipo de banco de dados.
Hoje, não há sistemas de arquivos Unix (não da mesma forma que antes) – talvez até mesmo nenhum arquivo. Agora existem APIs – interfaces de programação de aplicativos. Você pode, mas não precisa ter um arquivo como formato de entrada.
Tudo pode ser armazenado na memória cache. Ainda pode ser um arquivo. Seja o que for, deve seguir algum formato estruturado. Na maioria dos casos, isso significa formato JSON ou XML. Em alguns casos, o antigo e bom formato de valores separados por vírgula (CSV) também funcionará.
Você define o formato de entrada. Depende exclusivamente de você se o processo envolverá a criação do histórico de arquivos de entrada. Não é mais um passo padrão.
Transformação
As ferramentas ETL transformam os dados extraídos em um formato adequado para análise. Isso inclui limpeza de dados, validação de dados, enriquecimento de dados e agregação de dados.
Como costumava ser o caso, os dados passavam por alguma lógica personalizada complexa de preparação de dados processuais Pro-C ou PL/SQL, transformação de dados e etapas de armazenamento de esquema de destino de dados. Era um processo padrão igualmente obrigatório, como separar os arquivos recebidos em subpastas com base no estágio em que o arquivo foi processado.
Por que era tão natural se também era fundamentalmente errado ao mesmo tempo? Ao transformar diretamente os dados recebidos sem armazenamento permanente, você perdia a maior vantagem dos dados brutos – a imutabilidade. Os projetos simplesmente jogaram isso fora sem nenhuma chance de reconstrução.
Bem, adivinhe. Hoje, quanto menos transformação de dados brutos você executar, melhor. Para o primeiro armazenamento de dados no sistema. Pode ser que o próximo passo seja alguma mudança séria de dados e transformação do modelo de dados, com certeza. Mas você deseja armazenar os dados brutos na estrutura atômica e inalterada possível. Uma grande mudança em relação aos horários locais, se você me perguntar.
Carregar
As ferramentas ETL carregam os dados transformados em um banco de dados de destino ou data warehouse. Isso inclui criar tabelas, definir relacionamentos e carregar dados nos campos apropriados.
A etapa de carregamento é provavelmente a única que segue o mesmo padrão há anos. A única diferença é um banco de dados de destino. Enquanto antes era Oracle na maioria das vezes, agora pode ser o que estiver disponível na nuvem AWS.
ETL no ambiente de nuvem atual
Se você planeja trazer seus dados do local para a nuvem (AWS), você precisa de uma ferramenta ETL. Não funciona sem ele, e é por isso que essa parte da arquitetura em nuvem se tornou provavelmente a peça mais importante do quebra-cabeça. Se esta etapa estiver errada, qualquer outra coisa seguirá, compartilhando o mesmo cheiro em todos os lugares.
E embora existam muitas competições, eu me concentraria agora nas três com as quais tenho mais experiência pessoal:
- Data Migration Service (DMS) – um serviço nativo da AWS.
- Informatica ETL – provavelmente o principal player comercial no mundo ETL, transformando com sucesso seus negócios de on-premise para cloud.
- Matillion for AWS – um jogador relativamente novo dentro de ambientes de nuvem. Não nativo da AWS, mas nativo da nuvem. Com nada como história comparável com Informatica.
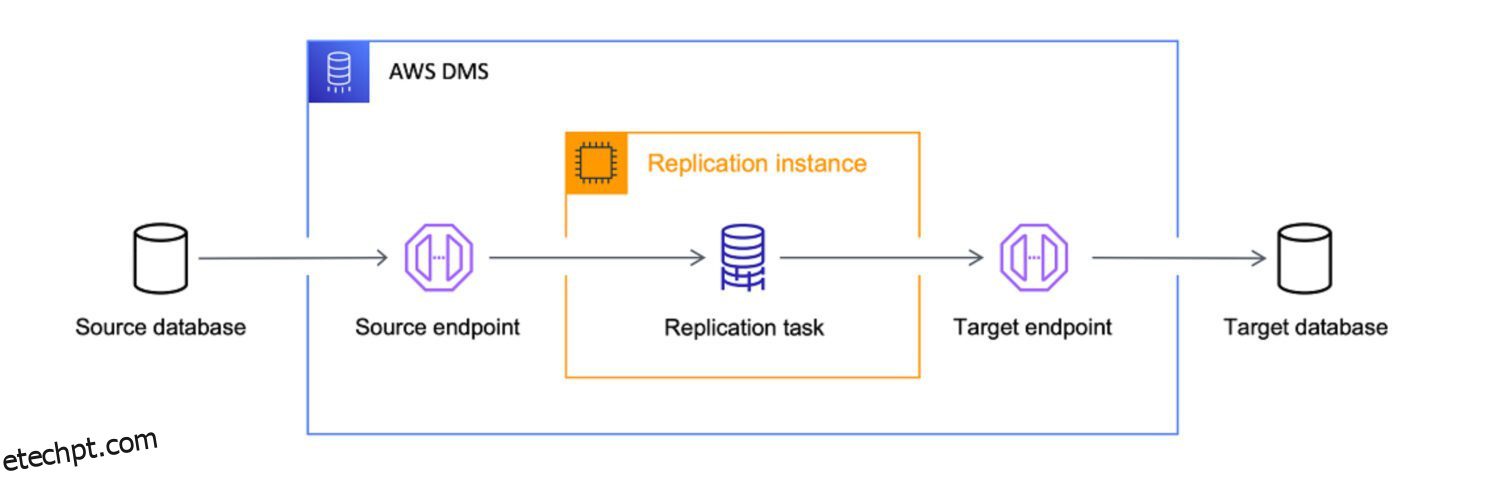
AWS DMS como ETL
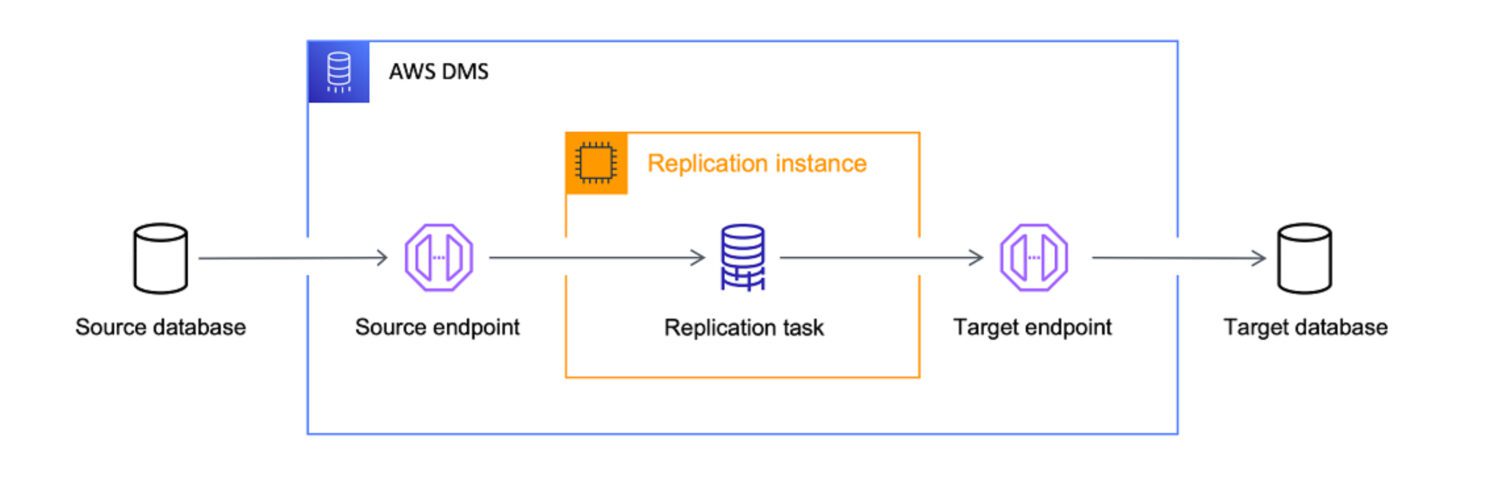 Fonte: aws.amazon.com
Fonte: aws.amazon.com
O AWS Data Migration Services (DMS) é um serviço totalmente gerenciado que permite migrar dados de diferentes fontes para a AWS. Ele oferece suporte a vários cenários de migração.
- Migrações homogêneas (por exemplo, Oracle para Amazon RDS for Oracle).
- Migrações heterogêneas (por exemplo, Oracle para Amazon Aurora).
O DMS pode migrar dados de várias fontes, incluindo bancos de dados, data warehouses e aplicativos SaaS, para vários destinos, incluindo Amazon S3, Amazon Redshift e Amazon RDS.
A AWS trata o serviço DMS como a ferramenta definitiva para trazer dados de qualquer fonte de banco de dados para destinos nativos da nuvem. Embora o objetivo principal do DMS seja apenas a cópia de dados para a nuvem, ele também faz um bom trabalho ao transformar os dados ao longo do caminho.
Você pode definir tarefas DMS no formato JSON para automatizar vários trabalhos de transformação enquanto copia os dados da origem para o destino:
- Mescle várias tabelas ou colunas de origem em um único valor.
- Divida o valor de origem em vários campos de destino.
- Substitua os dados de origem por outro valor de destino.
- Remova todos os dados desnecessários ou crie dados completamente novos com base no contexto de entrada.
Isso significa – sim, você pode definitivamente usar o DMS como uma ferramenta ETL para o seu projeto. Talvez não seja tão sofisticado quanto as outras opções abaixo, mas fará o trabalho se você definir o objetivo claramente de antemão.
Fator de Adequação
Embora o DMS forneça alguns recursos de ETL, trata-se principalmente de cenários de migração de dados. Existem alguns cenários em que pode ser melhor usar DMS em vez de ferramentas ETL como Informatica ou Matillion:
Matillion ETL
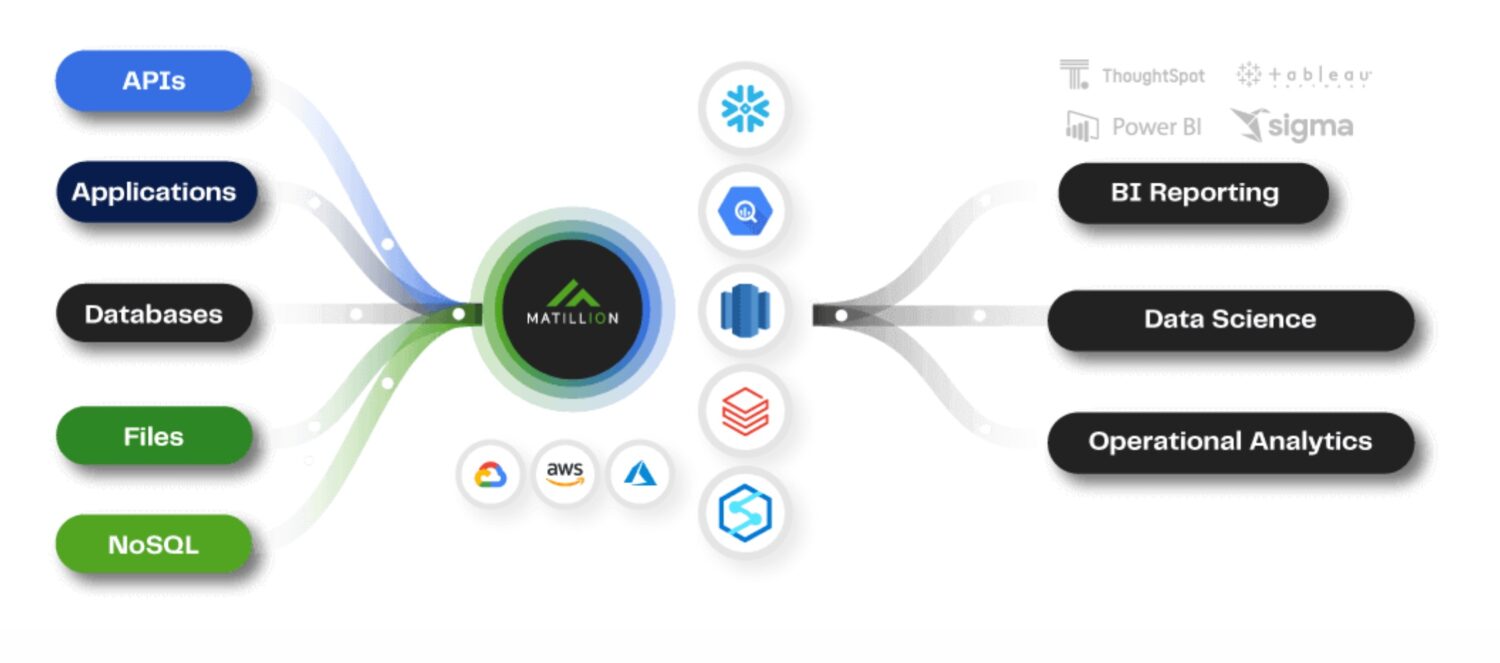 Fonte: matillion.com
Fonte: matillion.com
é uma solução nativa da nuvem e você pode usá-la para integrar dados de várias fontes, incluindo bancos de dados, aplicativos SaaS e sistemas de arquivos. Ele oferece uma interface visual para criar pipelines ETL e oferece suporte a vários serviços da AWS, incluindo Amazon S3, Amazon Redshift e Amazon RDS.
Matillion é fácil de usar e pode ser uma boa escolha para organizações novas em ferramentas ETL ou com necessidades de integração de dados menos complexas.
Por outro lado, Matillion é uma espécie de tabula rasa. Ele tem algumas funcionalidades potenciais predefinidas, mas você deve codificá-lo para trazê-lo à vida. Você não pode esperar que o Matillion faça o trabalho para você imediatamente, mesmo que a capacidade esteja lá por definição.
O Matillion também costuma se descrever como ELT em vez de uma ferramenta ETL. Isso significa que é mais natural para Matillion fazer uma carga antes da transformação.
Fator de Adequação
Em outras palavras, o Matillion é mais eficaz na transformação dos dados apenas quando eles já estão armazenados no banco de dados do que antes. A principal razão para isso é a obrigação de script personalizado já mencionada. Como todas as funcionalidades especiais devem ser codificadas primeiro, a eficácia dependerá fortemente da eficácia do código personalizado.
É natural esperar que isso seja melhor tratado no sistema de banco de dados de destino e deixar no Matillion apenas uma tarefa de carregamento 1:1 simples – muito menos oportunidades para destruí-lo com código personalizado aqui.
Embora o Matillion forneça uma variedade de recursos para integração de dados, ele pode não oferecer o mesmo nível de qualidade de dados e recursos de governança que algumas outras ferramentas ETL.
O Matillion pode aumentar ou diminuir com base nas necessidades da organização, mas pode não ser tão eficaz para lidar com grandes volumes de dados. O processamento paralelo é bastante limitado. A esse respeito, a Informatica é certamente uma escolha melhor porque é mais avançada e rica em recursos ao mesmo tempo.
No entanto, para muitas organizações, o Matillion for AWS pode fornecer escalabilidade suficiente e recursos de processamento paralelo para atender às suas necessidades.
Informatica ETL
 Fonte: informatica.com
Fonte: informatica.com
Informatica for AWS é uma ferramenta ETL baseada em nuvem projetada para ajudar a integrar e gerenciar dados em várias fontes e destinos na AWS. É um serviço totalmente gerenciado que fornece uma variedade de recursos e capacidades para integração de dados, incluindo criação de perfil de dados, qualidade de dados e governança de dados.
Algumas das principais características do Informatica for AWS incluem:
Fator de Adequação
Claramente, a Informatica é a ferramenta ETL mais rica em recursos da lista. No entanto, pode ser mais caro e complexo de usar do que algumas das outras ferramentas ETL disponíveis na AWS.
A Informatica pode ser cara, especialmente para organizações de pequeno e médio porte. O modelo de preços é baseado no uso, o que significa que as organizações podem precisar pagar mais à medida que o uso aumenta.
Também pode ser complexo de instalar e configurar, especialmente para aqueles que são novos nas ferramentas ETL. Isso pode exigir um investimento significativo em tempo e recursos.
Isso também nos leva a algo que podemos chamar de “curva de aprendizado complexa”. Isso pode ser uma desvantagem para aqueles que precisam integrar dados rapidamente ou têm recursos limitados para se dedicar ao treinamento e à integração.
Além disso, a Informatica pode não ser tão eficaz para integrar dados de fontes não AWS. Nesse sentido, DMS ou Matillion podem ser uma opção melhor.
Por fim, a Informatica é um sistema muito fechado. Há apenas uma capacidade limitada de personalizá-lo para as necessidades específicas do projeto. Você apenas tem que viver com a configuração que ele fornece fora da caixa. Assim, isso limita de alguma forma a flexibilidade das soluções.
Palavras Finais
Como acontece em muitos outros casos, não existe uma solução única para todos, mesmo algo como a ferramenta ETL na AWS.
Você pode escolher a solução mais complexa, rica em recursos e cara com a Informatica. Mas faz sentido fazer mais se:
- O projeto é bastante grande e você tem certeza de que toda a solução futura e as fontes de dados também se conectam à Informatica.
- Você pode se dar ao luxo de trazer uma equipe de desenvolvedores e configuradores qualificados da Informatica.
- Você pode apreciar a robusta equipe de suporte atrás de você e pagar por isso.
Se algo de cima estiver errado, você pode tentar Matillion:
- Se as necessidades do projeto não são tão complexas em geral.
- Se você precisar incluir algumas etapas muito personalizadas no processamento, a flexibilidade é um requisito fundamental.
- Se você não se importa em criar a maioria dos recursos do zero com a equipe.
Para algo ainda menos complicado, a escolha óbvia é o DMS para AWS como um serviço nativo, que provavelmente pode servir bem ao seu propósito.
A seguir, confira as ferramentas de transformação de dados para gerenciar melhor seus dados.