O tratamento de grandes volumes de dados representa um dos desafios mais complexos para as organizações. Essa complexidade aumenta exponencialmente quando lidamos com um fluxo massivo de dados em tempo real.
Neste artigo, vamos mergulhar no universo do processamento de big data, explorando como ele é realizado e analisando o Apache Kafka e o Spark, duas das ferramentas mais renomadas neste campo.
O que é o Processamento de Dados e Como Funciona?
O processamento de dados pode ser definido como qualquer operação ou conjunto de operações, sejam elas executadas por meios automatizados ou não, que visam coletar, ordenar e organizar informações de maneira lógica e apropriada para sua interpretação.
Quando um usuário interage com um banco de dados e obtém resultados para sua consulta, é o processamento de dados que está trabalhando nos bastidores para fornecer essas informações. Os resultados da pesquisa são, na verdade, o produto final desse processamento. É por isso que o processamento de dados é o coração da tecnologia da informação.
Tradicionalmente, o processamento de dados era realizado com softwares mais simples. No entanto, o surgimento do Big Data trouxe consigo uma nova realidade. Big Data se refere a volumes de informação que podem exceder centenas de terabytes e até petabytes.
Além disso, essas informações são constantemente atualizadas, como os dados provenientes de centrais de atendimento, redes sociais ou transações do mercado de ações. Esse fluxo de informações contínuo é também chamado de fluxo de dados, um fluxo constante e sem limites definidos, o que dificulta determinar seu início e fim.
O processamento de dados pode ocorrer no momento em que os dados chegam ao sistema, uma abordagem conhecida como processamento em tempo real ou online. Outra abordagem é o processamento em lote ou offline, onde os dados são processados em blocos, em janelas de tempo que podem variar de horas a dias. O processamento em lote é frequentemente utilizado para consolidar dados do dia, muitas vezes durante a noite. Há também casos de processamento em lote mais espaçados, como relatórios semanais ou mensais, o que pode gerar dados um tanto defasados.
As plataformas mais eficientes para processamento de Big Data via streaming são de código aberto, como o Kafka e o Spark. Por serem open source, essas plataformas se beneficiam de um desenvolvimento mais rápido e da integração com diversas outras ferramentas. Isso permite que os dados sejam recebidos de diversas fontes de forma contínua e com taxas de transferência variáveis.
Agora, vamos explorar duas das ferramentas mais populares de processamento de dados e compará-las:
Apache Kafka
O Apache Kafka é um sistema de mensagens que permite a criação de aplicações de streaming com fluxo de dados contínuo. Criado inicialmente pelo LinkedIn, o Kafka utiliza logs, que são uma forma básica de armazenamento onde cada nova informação é adicionada ao final do arquivo.
O Kafka é uma solução de ponta para big data devido ao seu alto rendimento. Com ele, é possível transformar o processamento em lote em processamento em tempo real.
O Apache Kafka funciona como um sistema de mensagens de publicação-assinatura, onde uma aplicação publica mensagens e outra aplicação inscrita recebe essas mensagens. O tempo entre a publicação e o recebimento da mensagem é mínimo, resultando em uma solução de baixa latência.
Como o Kafka Funciona
A arquitetura do Apache Kafka compreende produtores, consumidores e o cluster. O produtor é qualquer aplicação que publica mensagens no cluster, enquanto o consumidor é qualquer aplicação que recebe mensagens do Kafka. O cluster Kafka é um conjunto de nós que atuam como uma única instância do serviço de mensagens.
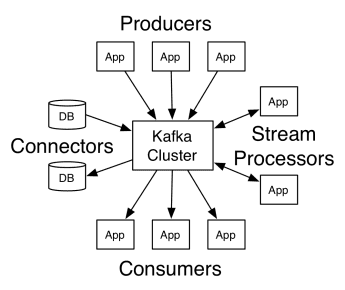
Um cluster Kafka é composto por vários brokers, que são servidores Kafka que recebem mensagens dos produtores e as armazenam em disco. Cada broker gerencia uma lista de tópicos, e cada tópico é dividido em várias partições.
Depois de receber as mensagens, o broker as envia para os consumidores inscritos para cada tópico.
As configurações do Apache Kafka são gerenciadas pelo Apache Zookeeper, que armazena metadados do cluster, como localização da partição, lista de nomes, lista de tópicos e nós disponíveis. O Zookeeper garante a sincronização entre os diferentes elementos do cluster.
O Zookeeper é fundamental porque o Kafka é um sistema distribuído, onde a escrita e leitura são feitas por vários clientes simultaneamente. Em caso de falha, o Zookeeper elege um substituto e retoma a operação.
Aplicações
O Kafka se popularizou, sobretudo, como ferramenta de mensagens, mas sua versatilidade se estende a diversos outros cenários, como os seguintes:
Mensageria
Uma forma assíncrona de comunicação que desvincula as partes envolvidas. Uma das partes envia os dados como uma mensagem para o Kafka, e outra aplicação os consome posteriormente.
Rastreamento de atividades
Permite armazenar e processar dados de rastreamento da interação de um usuário com um site, como visualizações de página, cliques e entrada de dados. Esse tipo de atividade costuma gerar um grande volume de dados.
Métricas
Envolve a agregação de dados e estatísticas de diversas fontes para gerar um relatório centralizado.
Agregação de logs
Agrega e armazena centralmente arquivos de log originados de outros sistemas.
Processamento de fluxo
O processamento de pipelines de dados envolve várias etapas, nas quais os dados brutos são consumidos de tópicos, agregados, enriquecidos ou transformados em outros tópicos.
Para suportar esses recursos, a plataforma fornece essencialmente três APIs:
- API de fluxos: atua como um processador de fluxo que consome dados de um tópico, os transforma e os escreve em outro.
- API de Conectores: permite conectar tópicos a sistemas existentes, como bancos de dados relacionais.
- APIs de produtor e consumidor: permite que aplicações publiquem e consumam dados do Kafka.
Vantagens
Replicado, particionado e ordenado
As mensagens no Kafka são replicadas em partições nos nós do cluster na ordem em que chegam, garantindo segurança e velocidade de entrega.
Transformação de dados
Com o Apache Kafka, é possível transformar o processamento em lote em tempo real, usando a API de fluxos ETL em lote.
Acesso sequencial ao disco
O Apache Kafka armazena as mensagens em disco em vez de na memória, pois isso é mais rápido. Embora o acesso à memória seja geralmente mais rápido, especialmente para dados em locais aleatórios, o Kafka realiza um acesso sequencial ao disco, o que se torna mais eficiente.
Apache Spark
O Apache Spark é um motor de computação de big data e um conjunto de bibliotecas para processamento paralelo de dados em clusters. O Spark é uma evolução do Hadoop e do paradigma de programação Map-Reduce. Ele pode ser até 100 vezes mais rápido devido ao uso eficiente da memória, que não armazena dados em disco durante o processamento.
O Spark está organizado em três camadas:
- APIs de baixo nível: esta camada contém as funcionalidades básicas para executar trabalhos e outras funções necessárias para os outros componentes. Outras funções importantes dessa camada são o gerenciamento de segurança, rede, agendamento e acesso lógico aos sistemas de arquivos HDFS, GlusterFS, Amazon S3 e outros.
- APIs estruturadas: a camada de API estruturada trata da manipulação de dados por meio de DataSets ou DataFrames, que podem ser lidos em formatos como Hive, Parquet, JSON e outros. Usando SparkSQL (API que permite escrever consultas em SQL), podemos manipular os dados da maneira que quisermos.
- Alto nível: no nível mais alto, temos o ecossistema Spark com diversas bibliotecas, incluindo Spark Streaming, Spark MLlib e Spark GraphX. Elas são responsáveis por cuidar da ingestão de streaming e processos como recuperação de falhas, criação e validação de modelos clássicos de aprendizado de máquina e lidar com gráficos e algoritmos.
Como o Spark Funciona
A arquitetura de uma aplicação Spark consiste em três partes principais:
Programa Driver: é responsável por orquestrar a execução do processamento de dados.
Cluster Manager: é o componente responsável por gerenciar as diferentes máquinas de um cluster. Ele só é necessário se o Spark for executado de forma distribuída.
Nodos Trabalhadores: são as máquinas que executam as tarefas de um programa. Se o Spark for executado localmente em sua máquina, ele desempenhará as funções de programa driver e nó trabalhador. Essa forma de executar o Spark é chamada de Standalone.
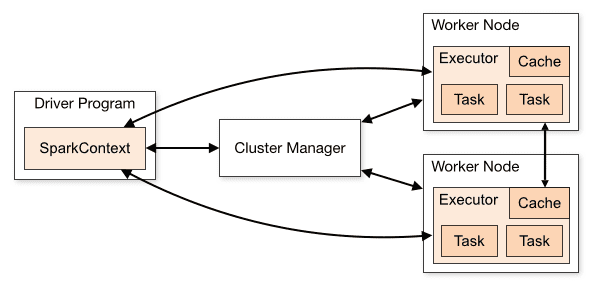 Visão geral do cluster
Visão geral do cluster
O código Spark pode ser escrito em diversas linguagens diferentes. O console Spark, chamado Spark Shell, é interativo para aprender e explorar dados.
O chamado aplicativo Spark é composto por um ou mais Jobs, possibilitando o suporte ao processamento de dados em grande escala.
Quando falamos de execução, o Spark possui dois modos:
- Cliente: o driver é executado diretamente no cliente, sem passar pelo Resource Manager.
- Cluster: o driver é executado no Application Master através do Resource Manager. No modo Cluster, se o cliente se desconectar, o aplicativo continuará rodando.
É preciso usar o Spark corretamente para que os serviços vinculados, como o Resource Manager, possam identificar a necessidade de cada execução, proporcionando o melhor desempenho. Cabe ao desenvolvedor determinar a melhor forma de executar seus jobs do Spark, estruturando a chamada realizada e configurando os executores do Spark conforme necessário.
Os trabalhos do Spark utilizam principalmente memória. Por isso, é comum ajustar as configurações de memória dos executores nos nós de trabalho. Dependendo da carga de trabalho do Spark, pode ser que uma configuração não padrão forneça resultados mais otimizados. Para isso, é possível realizar testes comparativos entre as diversas opções de configuração disponíveis e a configuração padrão do Spark.
Aplicações
O Apache Spark ajuda no processamento de grandes volumes de dados, tanto em tempo real quanto arquivados, estruturados ou não estruturados. A seguir estão alguns de seus casos de uso mais populares.
Enriquecimento de dados
Muitas empresas combinam dados históricos de clientes com dados comportamentais em tempo real. O Spark pode ajudar a construir um pipeline ETL contínuo para converter dados de eventos não estruturados em dados estruturados.
Detecção de eventos de gatilho
O Spark Streaming permite a detecção e resposta rápida a comportamentos raros ou suspeitos que podem indicar um possível problema ou fraude.
Análise de dados de sessão complexa
Usando o Spark Streaming, eventos relacionados à sessão do usuário, como suas atividades após o login no aplicativo, podem ser agrupados e analisados. Essas informações também podem ser usadas continuamente para atualizar modelos de aprendizado de máquina.
Vantagens
Processamento iterativo
Se a tarefa envolver o processamento repetido de dados, os conjuntos de dados distribuídos resilientes (RDDs) do Spark permitem realizar várias operações de mapa na memória sem ter que gravar resultados provisórios em disco.
Processamento gráfico
O modelo computacional do Spark com a API GraphX é excelente para cálculos iterativos típicos do processamento gráfico.
Aprendizado de máquina
O Spark possui o MLlib, uma biblioteca de aprendizado de máquina integrada que oferece algoritmos prontos para uso e que também são executados na memória.
Kafka vs Spark
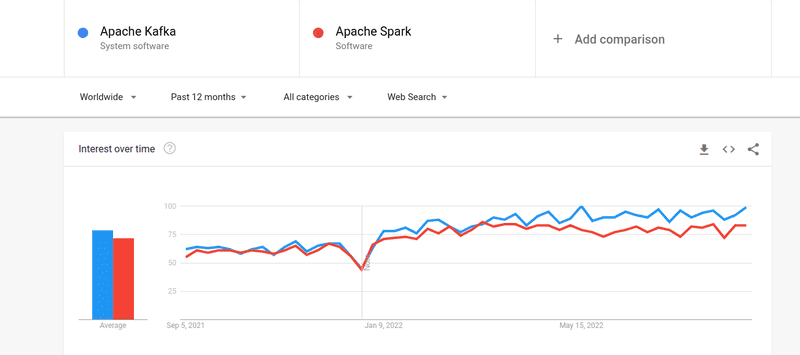
Embora o interesse em Kafka e Spark seja semelhante, existem diferenças importantes entre eles. Vamos analisar algumas dessas diferenças:
#1. Processamento de dados
O Kafka é uma ferramenta para streaming e armazenamento de dados em tempo real, responsável por transferir dados entre aplicativos, mas não é suficiente para construir uma solução completa. É preciso de ferramentas adicionais para tarefas que o Kafka não realiza, como o Spark. O Spark, por outro lado, é uma plataforma de processamento de dados em lote que extrai dados de tópicos Kafka e os transforma em esquemas combinados.
#2. Gerenciamento de memória
O Spark utiliza Robust Distributed Datasets (RDD) para gerenciamento de memória. Em vez de tentar processar grandes conjuntos de dados, ele os distribui entre diversos nós em um cluster. Já o Kafka usa acesso sequencial, semelhante ao HDFS, e armazena os dados em uma memória buffer.
#3. Transformação ETL
Tanto o Spark quanto o Kafka oferecem suporte ao processo de transformação ETL, que copia registros de um banco de dados para outro, geralmente de uma base transacional (OLTP) para uma base analítica (OLAP). No entanto, enquanto o Spark tem capacidade integrada para o processo ETL, o Kafka utiliza a API do Streams para apoiá-lo.
#4. Persistência de dados

O uso de RDD do Spark permite armazenar dados em vários locais para uso futuro, enquanto no Kafka é necessário definir objetos de conjunto de dados na configuração para persistir os dados.
#5. Dificuldade
O Spark é uma solução completa e fácil de aprender devido ao seu suporte para diversas linguagens de programação de alto nível. O Kafka depende de diversas APIs e módulos de terceiros, o que pode tornar seu uso mais complexo.
#6. Recuperação
Tanto o Spark quanto o Kafka oferecem opções de recuperação. O Spark utiliza RDD, que permite salvar dados continuamente e, em caso de falha no cluster, eles podem ser recuperados.

O Kafka replica continuamente os dados dentro do cluster e entre os brokers, o que permite migrar para outros brokers em caso de falha.
Semelhanças entre Spark e Kafka
| Apache Spark | Apache Kafka | |
| OpenSource | Sim | Sim |
| Aplicações de Streaming de Dados | Sim | Sim |
| Suporte a Processamento com Estado | Sim | Sim |
| Suporte a SQL | Sim | Sim |
Considerações Finais
Kafka e Spark são ferramentas de código aberto escritas em Scala e Java, que permitem criar aplicações de streaming de dados em tempo real. Elas têm várias coisas em comum, incluindo processamento com estado, suporte para SQL e ETL. Kafka e Spark podem ser usados também como ferramentas complementares para resolver o problema da complexidade da transferência de dados entre aplicações.