Os dados são cruciais para o funcionamento de empresas e organizações, mas seu valor é plenamente realizado quando são estruturados e gerenciados de maneira eficaz.
Estatísticas indicam que 95% das empresas consideram a gestão e organização de dados não estruturados um desafio significativo atualmente.
É nesse contexto que a mineração de dados se torna essencial. Este processo envolve descobrir, analisar e extrair padrões relevantes e informações úteis de grandes volumes de dados não estruturados.
As empresas utilizam softwares para identificar padrões em extensos conjuntos de dados, a fim de obter um entendimento mais profundo de seus clientes e público-alvo, e assim desenvolver estratégias de negócios e marketing que visam aumentar as vendas e reduzir os custos.
Além desse benefício, a detecção de fraudes e anomalias destaca-se como uma das aplicações mais relevantes da mineração de dados.
Este artigo detalha o conceito de detecção de anomalias e explora como essa técnica pode ser utilizada para evitar vazamentos de dados e invasões de rede, garantindo a segurança das informações.
O que é Detecção de Anomalias e Quais Seus Tipos?
A mineração de dados, embora focada em identificar padrões, correlações e tendências, também é uma ferramenta eficaz para encontrar anomalias ou pontos de dados atípicos dentro de uma rede.
No contexto da mineração de dados, anomalias referem-se a pontos de dados que se distinguem dos demais em um conjunto de dados, desviando-se do comportamento padrão desse conjunto.
As anomalias podem ser categorizadas em diferentes tipos, incluindo:
- Mudanças em Eventos: Referem-se a alterações abruptas ou sistemáticas em relação a um comportamento normal anterior.
- Outliers: Pequenos padrões anômalos que surgem de forma não sistemática na coleta de dados, subdivididos em outliers globais, contextuais e coletivos.
- Desvios: Mudanças graduais, não direcionais e de longo prazo em um conjunto de dados.
Assim, a detecção de anomalias é uma técnica de processamento de dados de grande utilidade para identificar transações fraudulentas, lidar com estudos de caso que apresentam desequilíbrio de classes e detectar doenças, o que é essencial para construir modelos robustos de ciência de dados.
Por exemplo, uma empresa pode analisar seu fluxo de caixa para detectar transações incomuns ou recorrentes em contas bancárias desconhecidas, a fim de identificar possíveis fraudes e iniciar investigações adicionais.
Benefícios da Detecção de Anomalias
A detecção de anomalias no comportamento do usuário contribui para fortalecer os sistemas de segurança, tornando-os mais precisos e eficientes.
Essa técnica analisa e interpreta diversas informações fornecidas pelos sistemas de segurança, identificando potenciais ameaças e riscos dentro de uma rede.
As vantagens da detecção de anomalias para as empresas incluem:
- Detecção em tempo real de ameaças de segurança cibernética e vazamentos de dados, utilizando algoritmos de inteligência artificial (IA) que monitoram continuamente os dados em busca de comportamentos incomuns.
- Agilização e facilitação do rastreamento de atividades e padrões anômalos, em comparação com a detecção manual, reduzindo o tempo e o esforço necessários para lidar com ameaças.
- Minimização de riscos operacionais pela identificação de erros, como quedas repentinas de desempenho, antes que se tornem problemas graves.
- Prevenção de grandes prejuízos financeiros através da rápida detecção de anomalias, considerando que, sem um sistema de detecção, as empresas podem levar semanas ou meses para identificar possíveis ameaças.
Em resumo, a detecção de anomalias é um recurso valioso para empresas que armazenam grandes volumes de dados de clientes e negócios, pois ajuda a identificar oportunidades de crescimento, além de eliminar ameaças à segurança e gargalos operacionais.
Técnicas de Detecção de Anomalias
A detecção de anomalias utiliza uma variedade de procedimentos e algoritmos de aprendizado de máquina (ML) para monitorar dados e identificar ameaças.
As principais técnicas de detecção de anomalias são:
#1. Técnicas de Aprendizado de Máquina
As técnicas de aprendizado de máquina empregam algoritmos de ML para analisar dados e identificar anomalias. Os algoritmos de aprendizado de máquina para detecção de anomalias incluem:
- Algoritmos de agrupamento
- Algoritmos de classificação
- Algoritmos de aprendizado profundo
As técnicas de ML frequentemente usadas para detecção de anomalias e ameaças englobam máquinas de vetores de suporte (SVMs), agrupamento k-means e codificadores automáticos.
#2. Técnicas Estatísticas
As técnicas estatísticas aplicam modelos estatísticos para detectar padrões incomuns nos dados, como flutuações inesperadas no desempenho de um equipamento, identificando valores que estão fora do intervalo esperado.
As técnicas estatísticas comuns de detecção de anomalias incluem teste de hipóteses, IQR (intervalo interquartil), Z-score, Z-score modificado, estimativa de densidade, boxplot, análise de valores extremos e histograma.
#3. Técnicas de Mineração de Dados

As técnicas de mineração de dados utilizam abordagens de classificação e agrupamento para encontrar anomalias em conjuntos de dados. Algumas técnicas comuns de anomalias de mineração de dados incluem agrupamento espectral, agrupamento baseado em densidade e análise de componentes principais.
Algoritmos de mineração de dados de agrupamento são utilizados para organizar diferentes pontos de dados em grupos com base em suas similaridades, a fim de detectar pontos de dados e anomalias que estão fora desses agrupamentos.
Em contraste, os algoritmos de classificação alocam pontos de dados em classes predefinidas e detectam pontos que não pertencem a essas classes.
#4. Técnicas Baseadas em Regras
Como o nome sugere, as técnicas de detecção de anomalias baseadas em regras utilizam um conjunto de regras predefinidas para encontrar anomalias nos dados.
Essas técnicas são relativamente fáceis e simples de configurar, mas podem ser inflexíveis e menos eficazes em se adaptar a mudanças no comportamento e nos padrões de dados.
Por exemplo, é possível programar um sistema baseado em regras para sinalizar transações que excedam um valor específico em dólares como fraudulentas.
#5. Técnicas Específicas de Domínio
Técnicas específicas de domínio são usadas para detectar anomalias em sistemas de dados particulares. Embora sejam altamente eficazes em domínios específicos, podem ser menos eficientes em outros.
Por exemplo, podem ser criadas técnicas específicas para identificar anomalias em transações financeiras, mas essas mesmas técnicas podem não funcionar para encontrar problemas de desempenho em uma máquina.
A Necessidade do Aprendizado de Máquina para a Detecção de Anomalias
O aprendizado de máquina é fundamental e extremamente útil na detecção de anomalias.
Atualmente, a maioria das empresas e organizações que precisam detectar outliers lida com grandes quantidades de dados, abrangendo desde texto, informações de clientes e transações até arquivos de mídia, como imagens e vídeos.
Analisar manualmente todas as transações bancárias e dados gerados a cada segundo para obter informações relevantes é praticamente inviável. Além disso, muitas empresas enfrentam desafios na estruturação de dados não estruturados para análise.
É neste ponto que ferramentas e técnicas como o aprendizado de máquina (ML) desempenham um papel vital na coleta, limpeza, estruturação, organização, análise e armazenamento de grandes volumes de dados não estruturados.
Técnicas e algoritmos de aprendizado de máquina processam grandes conjuntos de dados e oferecem flexibilidade para combinar diferentes abordagens, proporcionando os melhores resultados.
O aprendizado de máquina também simplifica os processos de detecção de anomalias para aplicações reais, economizando recursos valiosos.
Outros benefícios e a importância do aprendizado de máquina na detecção de anomalias incluem:
- Facilitação da detecção de anomalias, automatizando a identificação de padrões sem exigir programação explícita.
- Alta adaptabilidade dos algoritmos de aprendizado de máquina a mudanças em padrões de dados, tornando-os eficientes e robustos ao longo do tempo.
- Habilidade para lidar com conjuntos de dados grandes e complexos, mantendo a eficiência na detecção de anomalias.
- Garantia da identificação precoce de anomalias, economizando tempo e recursos.
- Maior precisão na detecção de anomalias, comparado com métodos tradicionais.
Dessa forma, a detecção de anomalias combinada com o aprendizado de máquina acelera a identificação de problemas, evitando ameaças à segurança e violações maliciosas.
Algoritmos de Aprendizado de Máquina para Detecção de Anomalias
É possível identificar anomalias e discrepâncias em dados utilizando diferentes algoritmos de mineração de dados para classificação, agrupamento ou aprendizagem de regras de associação.
Esses algoritmos de mineração de dados são tipicamente divididos em duas categorias: algoritmos de aprendizado supervisionado e não supervisionado.
Aprendizado Supervisionado
O aprendizado supervisionado é um tipo comum de algoritmo que inclui técnicas como máquinas de vetores de suporte, regressão logística e linear e classificação multiclasse. Este tipo de algoritmo é treinado em dados rotulados, o que significa que seu conjunto de dados de treinamento contém tanto dados de entrada normais quanto a saída correta correspondente ou exemplos anômalos, usados para construir um modelo preditivo.
Seu objetivo é fazer previsões de saída para dados novos, com base nos padrões encontrados no conjunto de treinamento. Aplicações de algoritmos de aprendizado supervisionado incluem reconhecimento de imagem e fala, modelagem preditiva e processamento de linguagem natural (PNL).
Aprendizado não supervisionado
O aprendizado não supervisionado não é treinado em dados rotulados. Em vez disso, ele descobre processos complicados e estruturas de dados subjacentes sem orientação, ao invés de fazer previsões específicas.
Aplicações de algoritmos de aprendizado não supervisionado incluem detecção de anomalias, estimativa de densidade e compactação de dados.
Agora, vamos explorar alguns algoritmos populares de detecção de anomalias baseados em aprendizado de máquina.
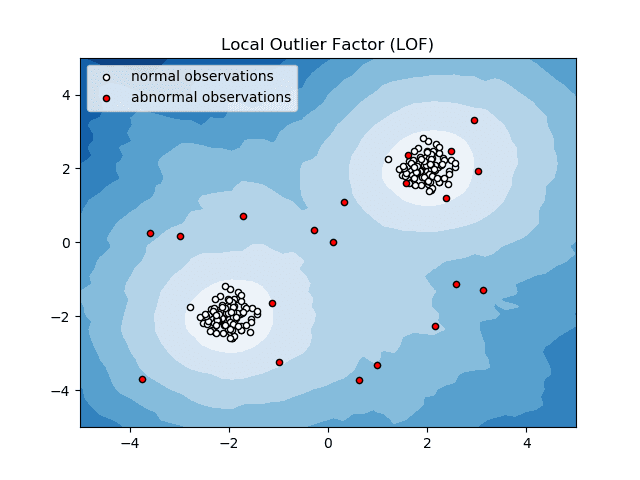
Fator Outlier Local (LOF)
O Fator Outlier Local, ou LOF, é um algoritmo de detecção de anomalias que analisa a densidade local dos dados para determinar se um ponto de dados é uma anomalia.
 Fonte: scikit-learn.org
Fonte: scikit-learn.org
Ele compara a densidade local de um item com as densidades locais de seus vizinhos para analisar áreas de densidades semelhantes, e identificar itens com densidades relativamente menores do que seus vizinhos – o que caracteriza anomalias ou valores discrepantes.
Em outras palavras, a densidade ao redor de um item atípico ou anômalo difere da densidade ao redor de seus vizinhos. Por isso, este algoritmo também é conhecido como algoritmo de detecção de outliers baseado em densidade.
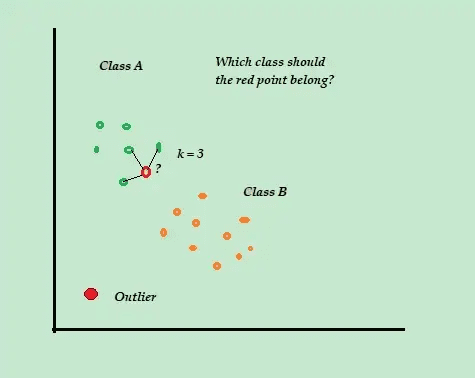
K-vizinho mais próximo (K-NN)
O K-NN é o algoritmo mais simples de classificação e detecção de anomalias supervisionadas, fácil de implementar. Ele armazena todos os exemplos e dados disponíveis e classifica novos exemplos com base em semelhanças nas métricas de distância.
 Fonte:warddatascience.com
Fonte:warddatascience.com
Este algoritmo de classificação também é conhecido como aprendizado preguiçoso, pois apenas armazena os dados de treinamento rotulados – sem realizar processamento adicional durante o treinamento.
Quando um novo ponto de dados não rotulado é recebido, o algoritmo analisa os K-vizinhos mais próximos para usá-los na classificação e na determinação da classe do novo ponto não rotulado.
O algoritmo K-NN utiliza os seguintes métodos para determinar os pontos de dados mais próximos:
- Distância euclidiana para medir a distância entre dados contínuos.
- Distância de Hamming para medir a proximidade entre duas strings de texto para dados discretos.
Por exemplo, suponha que seu conjunto de treinamento contenha dois rótulos de classe, A e B. Se um novo ponto de dados for recebido, o algoritmo calculará a distância entre esse ponto e cada ponto do conjunto de dados, e selecionará os pontos mais próximos do novo ponto.
Se K = 3 e 2 dos 3 pontos forem da classe A, então o novo ponto será classificado como classe A.
O algoritmo K-NN é mais eficaz em ambientes dinâmicos com frequentes necessidades de atualização de dados.
É um algoritmo popular na detecção de anomalias e mineração de texto, com aplicações em finanças e negócios para detectar transações fraudulentas e aumentar a taxa de detecção de fraudes.
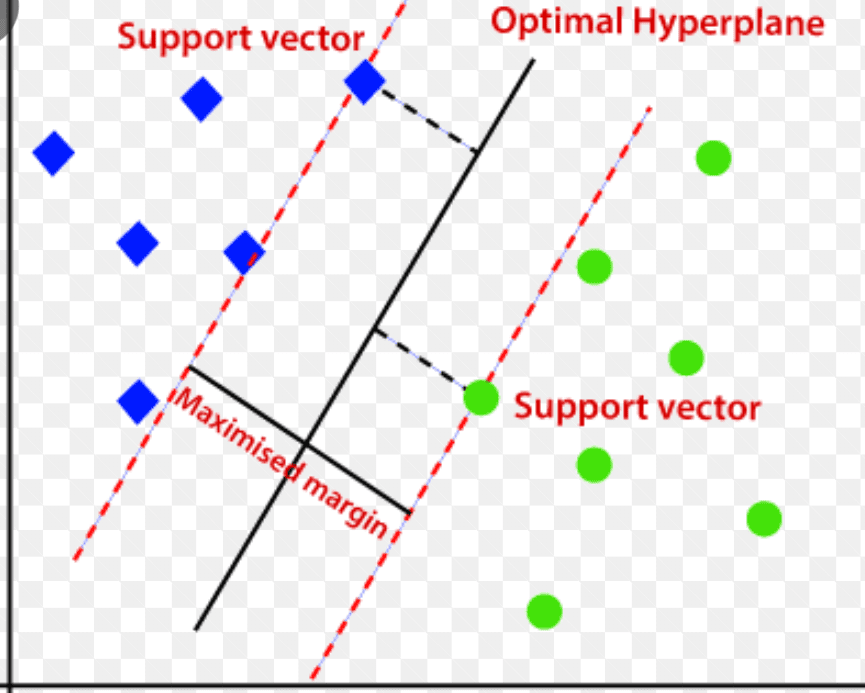
Máquina de vetores de suporte (SVM)
A máquina de vetores de suporte é um algoritmo de detecção de anomalias baseado em aprendizado de máquina supervisionado, utilizado principalmente em problemas de regressão e classificação.
Ele emprega um hiperplano multidimensional para separar os dados em dois grupos (novos e normais). O hiperplano serve como um limite de decisão que separa as observações de dados normais dos novos dados.
 Fonte: www.analyticsvidhya.com
Fonte: www.analyticsvidhya.com
A distância entre esses dois pontos de dados é chamada de margens.
O SVM busca aumentar a distância entre os dois pontos, determinando o melhor hiperplano com a margem máxima para garantir que a distância entre as duas classes seja a maior possível.
Na detecção de anomalias, o SVM calcula a margem da nova observação do ponto de dados em relação ao hiperplano para classificá-la.
Se a margem exceder o limite definido, a observação será classificada como anomalia. Caso contrário, será classificada como normal.
Os algoritmos SVM são altamente eficazes no tratamento de conjuntos de dados complexos e de alta dimensão.
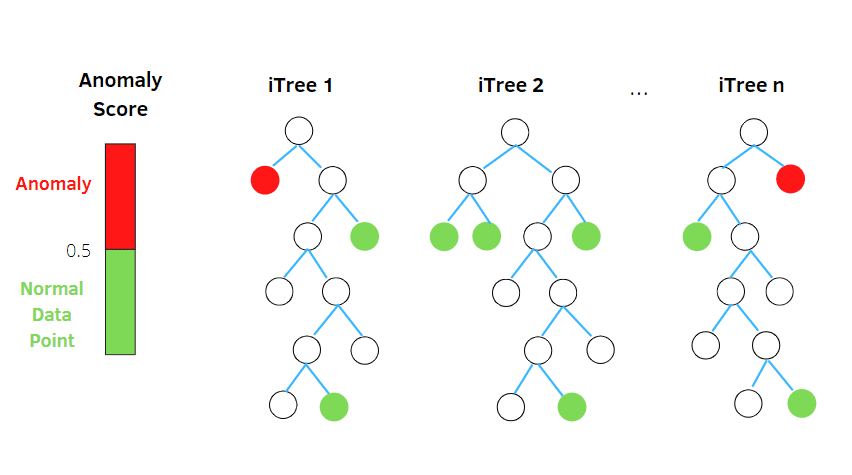
Floresta de Isolamento
A Floresta de Isolamento é um algoritmo de detecção de anomalias de aprendizado de máquina não supervisionado, baseado no conceito de classificador de floresta aleatória.
 Fonte: betterprogramming.pub
Fonte: betterprogramming.pub
Este algoritmo processa dados subamostrados aleatoriamente no conjunto de dados em uma estrutura de árvore baseada em atributos aleatórios. Ele constrói várias árvores de decisão para isolar observações, e considera uma observação como anomalia se ela for isolada em menos árvores, com base em sua taxa de contaminação.
Em termos mais simples, o algoritmo da floresta de isolamento divide os pontos de dados em árvores de decisão, garantindo que cada observação seja isolada da outra.
As anomalias geralmente estão distantes do agrupamento de pontos de dados, tornando-as mais fáceis de identificar em comparação com pontos de dados normais.
Algoritmos de floresta de isolamento são capazes de lidar com dados categóricos e numéricos, são mais rápidos de treinar e altamente eficazes na detecção de anomalias em conjuntos de dados de alta dimensão e grandes volumes.
Intervalo Interquartil
O intervalo interquartil (IQR) é usado para medir a variabilidade ou dispersão estatística para encontrar pontos anômalos nos conjuntos de dados, dividindo-os em quartis.
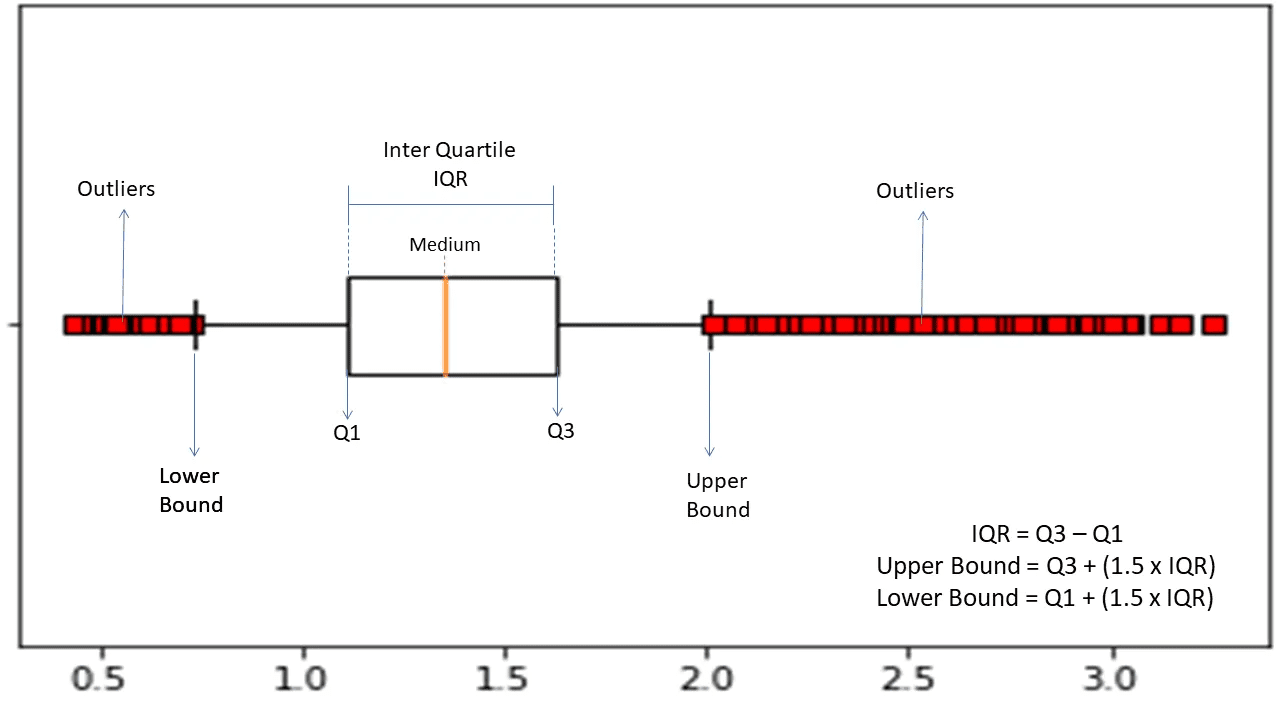 Fonte: morioh.com
Fonte: morioh.com
O algoritmo classifica os dados em ordem crescente e divide o conjunto em quatro partes iguais. Os valores que separam essas partes são Q1, Q2 e Q3 – primeiro, segundo e terceiro quartis.
A distribuição percentual desses quartis é:
- Q1 representa o percentil 25 dos dados.
- Q2 representa o percentil 50 dos dados.
- Q3 representa o percentil 75 dos dados.
O IQR é a diferença entre o terceiro (75º) e o primeiro (25º) conjuntos de dados percentis, representando 50% dos dados.
Para usar o IQR na detecção de anomalias, é necessário calcular o IQR do seu conjunto de dados e definir os limites inferior e superior dos dados para encontrar anomalias.
- Limite inferior: Q1 – 1,5 * IQR
- Limite superior: Q3 + 1,5 * IQR
Geralmente, as observações fora desses limites são consideradas anomalias.
O algoritmo IQR é eficaz para conjuntos de dados com distribuição desigual e onde a distribuição não é bem compreendida.
Considerações Finais
Os riscos de segurança cibernética e vazamentos de dados não mostram sinais de diminuição nos próximos anos, e espera-se que esse setor arriscado continue crescendo em 2023, com ataques cibernéticos de IoT previstos para dobrar até 2025.
Estima-se que os crimes cibernéticos custarão a empresas e organizações globais cerca de US$ 10,3 trilhões por ano até 2025.
A necessidade de técnicas de detecção de anomalias está se tornando cada vez mais essencial para a detecção de fraudes e prevenção de invasões de rede.
Este artigo tem como objetivo ajudar a compreender o que são anomalias na mineração de dados, os diferentes tipos de anomalias e como evitar invasões de rede utilizando técnicas de detecção de anomalias baseadas em ML.
Para aprofundar, pode-se explorar o conceito da matriz de confusão no aprendizado de máquina.