Um plano de contingência para desastres é uma salvaguarda indispensável que qualquer organização deve implementar antes que eventos imprevistos a atinjam.
No âmbito da Tecnologia da Informação, isso implica a criação de um documento formal que detalha os planos, ações e procedimentos a serem seguidos para gerenciar um desastre e suas repercussões.
Um desastre é um evento repentino e inesperado, que pode se manifestar de diversas formas. Quando ocorre, indivíduos e organizações enfrentam desafios complexos, que incluem problemas financeiros e impactos na experiência do usuário.
Em caso de incidente, é fundamental estar preparado para atenuar seus efeitos e restabelecer as operações o mais rápido possível. É nesse contexto que um plano de recuperação de desastres bem elaborado desempenha um papel crucial na proteção e mitigação dos danos. Ele também ajuda a minimizar as consequências em termos de experiência do cliente, custos e tempo de inatividade.
Adicionalmente, é preciso manter seus planos, pessoal, estratégias, equipamentos e sistemas prontos para restabelecer as operações. No entanto, para isso, é crucial compreender a fundo o processo de recuperação de desastres.
Neste artigo, exploraremos este tema em profundidade, juntamente com as principais definições da área, permitindo que você esteja melhor preparado para enfrentar e superar essas adversidades.
Vamos começar!
O que define um desastre?
Um desastre é um evento inesperado, com potencial de ocorrer em qualquer contexto, inclusive no setor de TI. Ele pode ser de origem natural ou humana, capaz de interromper as operações de uma empresa e desestabilizar a infraestrutura.
Como resultado, a organização, seus clientes, fornecedores, colaboradores e parceiros são impactados. O desastre exerce pressão sobre a organização em relação às finanças, reputação no mercado, confiança do cliente e segurança geral.
Portanto, é essencial estar preparado para enfrentar esse cenário. Isso requer a capacidade de recuperar rapidamente todas as operações e dados. Em outras palavras, sua organização deve estar preparada para restabelecer tudo no menor tempo possível para seus clientes.
Os desastres podem ser de variadas naturezas, como ataques cibernéticos, sabotagem, ataques terroristas, ransomware ou ameaças físicas, furacões, terremotos, incêndios, inundações, acidentes industriais, falhas de energia e muitos outros.
O que significa recuperação de desastres?
A recuperação de desastres é o procedimento de restaurar as operações normais após um desastre. Isso inclui restabelecer o acesso a hardware, software, equipamentos, conectividade, redes, energia e dados. É fundamental estabelecer regras e procedimentos claros em um documento para preparar a organização antes de um evento adverso.
Caso as instalações da organização sejam afetadas, pode ser necessário expandir o processo de recuperação, abordando comunicação, transporte, suprimentos, locais de trabalho e outros fatores.
Por que um plano de recuperação de desastres é tão importante?
Desenvolver um plano sólido para recuperação de desastres, sejam eles de origem natural ou humana, é essencial em todos os setores de TI. Certifique-se de ter as pessoas e as ferramentas corretas, no local certo, para garantir uma execução tranquila do plano.
Vamos detalhar as razões pelas quais a recuperação de desastres é fundamental:
Minimização de Danos
A natureza de um desastre é imprevisível. Ninguém pode prever com exatidão seu momento ou duração. No entanto, é possível preparar-se com antecedência para controlar os danos à infraestrutura.
Por exemplo, em regiões suscetíveis a inundações, é possível elevar documentos e equipamentos essenciais a andares superiores para evitar perdas.
Da mesma forma, é crucial realizar backups dos dados críticos antes que ataques cibernéticos causem danos ou roubos.
Retomada de Serviços
Um plano robusto de recuperação de desastres garante uma restauração rápida e eficiente dos serviços às suas condições normais. Isso significa que, em um curto espaço de tempo, será possível restabelecer os principais ativos e serviços.
Redução de Interrupções
Não é possível prever o que pode acontecer no futuro imediato. No entanto, com um plano de recuperação eficaz, as consequências são menos preocupantes. A infraestrutura pode manter as operações com o mínimo de interrupção.
Treinamento e Preparação

Uma infraestrutura de TI envolve diversos profissionais. É essencial que todos tenham conhecimento sobre os procedimentos de recuperação, para agirem de maneira imediata e adequada em caso de emergência.
O preparo adequado também diminui o nível de estresse dos colaboradores da organização. Além disso, é possível capacitar os funcionários para tomarem as medidas necessárias em caso de um evento inesperado.
Terminologia de Recuperação de Desastres
Vamos explorar as definições para aprofundar o entendimento sobre recuperação de desastres.
RTO
O Objetivo de Tempo de Recuperação (RTO) é o período que uma organização estabelece, com base na natureza de suas atividades, para tolerar uma interrupção sem comprometer seu crescimento financeiro.
Ao definir o RTO, uma empresa precisa analisar o tempo de inatividade que pode afetar suas operações. Isso é usado para desenvolver estratégias viáveis que permitam a continuidade dos negócios, mesmo após um desastre. Quando os clientes enfrentam problemas com um aplicativo, eles perguntam quanto tempo levará para que ele volte a funcionar. A resposta é o RTO de cada organização.
Exemplo: Em uma empresa de transações online, como PayPal ou Pioneer, que enfrenta eventos imprevistos, o RTO precisa ser o mais rápido possível para restabelecer as operações.
Ou seja, uma empresa define um RTO de uma ou duas horas para evitar consequências negativas em termos financeiros e de dados.
RPO
O Objetivo de Ponto de Recuperação (RPO) é a quantidade de perda de dados que uma infraestrutura de TI pode suportar em termos de tempo e volume de informações.
Confuso?
Considere um banco de dados que registra as transações de um banco, como transferências, agendamentos e pagamentos. Em caso de desastre, o banco de dados deve ser recuperado quase em tempo real. Idealmente, a diferença entre o banco de dados no momento do desastre e o recuperado deve ser mínima.
Para algumas empresas, pode ser aceitável levar cerca de 24 horas para recuperar as informações a partir de backups, enquanto para outras isso pode ser catastrófico. É essencial definir a infraestrutura de acordo com os requisitos de RPO. Isso inclui aumentar a frequência dos backups, adicionar um banco de dados de espera à arquitetura, entre outras medidas.
Failover
Imagine uma situação em que você está dirigindo por uma longa distância e, de repente, um pneu fura. Felizmente, você tem um pneu reserva e as ferramentas para substituí-lo.
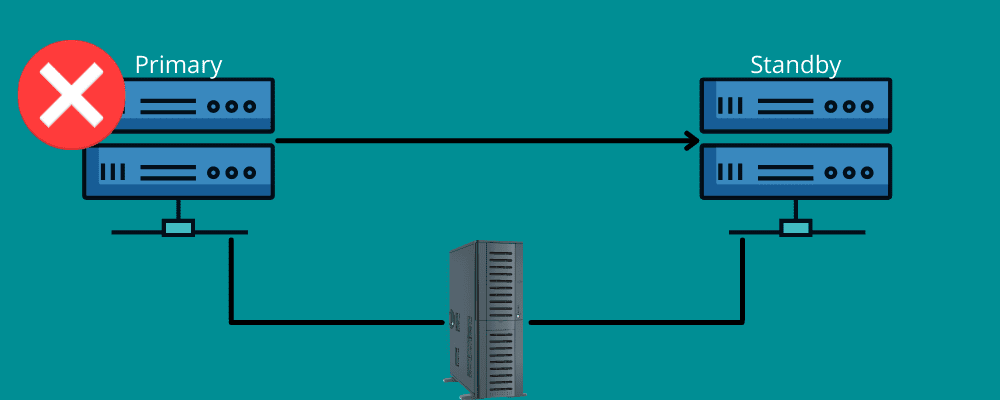
O failover funciona de forma semelhante.
Isso significa que você precisa de uma conexão de backup durante um desastre. Em resumo, failover significa ter redes e sistemas de reserva que podem ser usados para transferir informações para o sistema de recuperação em caso de emergência.
O failover garante que todos os serviços operem sem interrupções, mesmo em casos de falhas de infraestrutura ou hardware. Dessa forma, a organização pode evitar perdas de dados e receita, e garantir a continuidade do serviço para seus usuários.
O failover pode ser configurado manualmente ou automaticamente para transferir os dados para um servidor de espera.
Failback
O failback é o processo de restaurar as operações para o local ou sistema original, após a ocorrência de um desastre. Durante um ataque, as empresas utilizam o failover, que transfere as cargas de trabalho para uma réplica de VM ou sistema de backup.
Entretanto, o processo de retorno é fundamental. Após a resolução do problema, é preciso transferir as cargas de trabalho de volta para suas VMs ou sistemas originais. Esse processo, conhecido como failback, significa o retorno à operação normal.
O failback também é usado para manutenções programadas. Geralmente, o failback ocorre após o failover. Ou seja, o failover é o primeiro passo e o failback, o segundo, na recuperação de dados essenciais. O failback pode ser configurado entre nuvem para nuvem, local para local, local para nuvem ou qualquer combinação dessas opções.
RD
A Recuperação de Desastres (RD) é o processo que envolve o planejamento e execução de medidas para recuperar os ativos da organização dentro de um prazo determinado.
A RD permite que uma organização responda rapidamente e retome todos os serviços após um evento imprevisto. Ela fornece uma documentação formal com instruções detalhadas sobre como agir imediatamente em casos de emergência.
PCN
O Plano de Continuidade de Negócios (PCN) é um dos planos de recuperação de desastres mais comuns, que auxilia a infraestrutura de TI na criação de estratégias para lidar com interrupções em servidores, dispositivos móveis, computadores pessoais e redes.
O PCN difere um pouco da recuperação de desastres, pois ajuda a organização a planejar o restabelecimento do software corporativo e da produtividade, atendendo às principais necessidades do negócio.
Nesse contexto, a empresa cria um sistema de recuperação para lidar com ameaças potenciais, como ataques cibernéticos ou desastres naturais. O objetivo é proteger os ativos e garantir que todos os serviços voltem a funcionar rapidamente após a ocorrência de um evento adverso.
BCM

O Gerenciamento da Continuidade dos Negócios (BCM) é um processo de gestão de riscos desenvolvido para proteger os processos de negócios. O BCM é um passo além do PCN, pois valida os planos de recuperação para garantir que todos na empresa respondam prontamente ao plano e recuperem tudo o que é essencial.
O BCM atua como uma estrutura de gerenciamento para identificar riscos na infraestrutura ao enfrentar ameaças internas ou externas. Ele também garante que a estrutura funcione de forma eficaz por meio de testes regulares, visando aumentar a previsibilidade, reduzir os riscos e otimizar o plano para futuros incidentes.
BIA
A Análise de Impacto nos Negócios (BIA) é o processo de avaliar a taxa de sobrevivência de uma empresa, identificando os sistemas, operações e processos críticos. Ela avalia o impacto de um desastre na organização devido à interrupção de suas operações.
A BIA prevê as consequências antes de um ataque real, reunindo informações relevantes que podem ajudar no desenvolvimento de estratégias de recuperação eficazes. Também identifica os custos envolvidos em falhas, como custos de reposição de equipamentos, perda de fluxo de caixa, lucros, salários, entre outros.
Ao criar um relatório de BIA, é preciso considerar os processos críticos envolvidos no negócio, o impacto das interrupções em diferentes áreas, a duração aceitável das interrupções, áreas toleráveis, custos financeiros, entre outros aspectos.
Árvore de Chamadas
Uma árvore de chamadas é um sistema de comunicação hierárquico usado para notificar os funcionários em caso de emergência. O processo segue uma estrutura em forma de árvore.
Por exemplo, em caso de desastre, um indivíduo entra em contato com um pequeno grupo de pessoas, que, por sua vez, contatam outros grupos, e assim por diante. Desta forma, todos os funcionários são informados sobre a emergência e podem iniciar as ações necessárias para a recuperação. Apesar de simples, a implementação pode gerar dificuldades.
É fundamental realizar exercícios regulares para preparar todos os membros da equipe de emergência. Testes frequentes também podem identificar números de telefone incorretos ou desatualizados que podem dificultar a comunicação.
Uma árvore de chamadas contém informações e instruções a serem usadas durante uma emergência. Embora possa ser feita manualmente, a automação é preferida hoje em dia para acelerar o processo de notificação.
Centro de Comando/Centro de Controle
É uma instalação física ou virtual preparada para gerenciar os planos de recuperação durante uma crise. Ela se comunica com a equipe para coordenar os sistemas e funções afetadas pelo desastre.
Tradicionalmente, as infraestruturas dependem de centros de comando que lidam com crises de forma pouco organizada. Atualmente, as organizações projetam seus centros de controle para garantir uma resposta imediata e eficiente.
Assim que detecta um desastre, o centro de comando inicia a fase de recuperação. Ele também serve como ponto de comunicação para serviços, imprensa, entregas e outras necessidades. Além disso, reúne profissionais de diferentes áreas durante esses cenários.
Resposta a Incidentes

A resposta a incidentes é o conjunto de ações tomadas para lidar com um ataque. Ela é realizada por meio de procedimentos e pessoal qualificado para proteger a segurança da rede e dos dados de forma eficaz.
Caso a organização possua um plano de resposta a incidentes bem definido, os dados podem ser protegidos de ameaças em tempo real. Os especialistas em resposta a incidentes estão sempre alertas para possíveis problemas e atuam de forma rápida durante um incidente. Eles tomam medidas para evitar violações de segurança, garantindo a execução de todos os passos durante a recuperação de desastres.
Inicialmente, é preciso determinar os dados críticos e armazená-los na nuvem ou em outro local seguro. É fundamental atender às necessidades da infraestrutura e às ameaças cibernéticas atuais, atualizando regularmente os planos de resposta a incidentes.
Backup
As soluções de backup auxiliam a infraestrutura de TI na manutenção de cópias de dados, armazenando-as em segurança. Em caso de corrupção de dados, exclusão acidental ou qualquer outro problema, é possível usar o backup para restaurar os dados e retomar os serviços.

Isso envolve a replicação de arquivos e o armazenamento em um local seguro para facilitar o acesso aos dados após um evento imprevisto. É recomendado fazer backups em vários locais, para garantir que os dados possam ser recuperados mesmo em caso de falha de um local específico.
Resiliência
A capacidade de indivíduos, organizações, comunidades e estados de suportar ou resistir a um desastre sem comprometer seus serviços e sistemas é conhecida como resiliência a desastres.
É essencial que uma organização esteja preparada para suportar altos níveis de estresse devido a perigos. Certifique-se de ter os recursos para minimizar as perdas por meio de um planejamento adequado, ao invés de depender de ajuda externa. Isso ajudará a adaptar-se a desastres e recuperar a infraestrutura de TI de forma eficiente.
Nesse contexto, o objetivo é preservar e restaurar as funções e estruturas essenciais. Para se tornar uma organização resiliente, é fundamental preparar-se antecipadamente, antecipar riscos, ajustar-se às mudanças, compartilhar conhecimento, integrar diferentes setores e gerenciar os níveis de risco.
SLA

Um Acordo de Nível de Serviço (SLA) é um plano que informa aos usuários finais o tempo necessário para restaurar os serviços em caso de emergência.
O SLA garante aos clientes que seus dados estão protegidos e não serão compartilhados com terceiros. É o principal ponto de comunicação em caso de problemas para o usuário final.
Toda infraestrutura de TI deve oferecer garantias de SLA aos seus clientes. É importante comunicar os prazos de recuperação aos usuários com antecedência.
SPOF
Um Ponto Único de Falha (SPOF) é um equipamento, pessoa, recurso ou aplicação à qual outros sistemas ou aplicações estão conectados.
Se esse equipamento ou recurso ficar inativo, todos os componentes conectados também serão afetados. Isso terá um impacto negativo nos processos e operações do negócio.
Portanto, é essencial ter uma estratégia para lidar com esse problema e manter a organização em funcionamento. O primeiro passo é identificar o equipamento ou sistema que pode ter maior impacto. Em seguida, realize uma análise de impacto nos negócios e avalie os riscos, a fim de estar ciente dos possíveis cenários.
Após listar todos os SPOFs, classifique-os de acordo com o processo de recuperação. Divida-os em três categorias:
- Recuperação fácil e direta, com baixo custo e tempo.
- Recuperação difícil, mas possível com um processo confiável.
- Recuperação impossível.
As ações a serem tomadas dependerão da categoria.
Recuperação do Sistema
Em caso de falha de hardware, é necessário executar um processo de recuperação para restabelecer o sistema ou servidor específico à sua condição original. Para recuperar todo o sistema, é preciso dispor dos requisitos de recuperação, backups, compatibilidade de firmware e hardware.
A recuperação do sistema é o processo que redefine a máquina para suas configurações originais ou para a condição em que estava quando era nova. Isso eliminará infecções por vírus causadas por softwares ou aplicativos instalados no sistema.
Este processo inclui o planejamento da recuperação da infraestrutura de TI, que define procedimentos para garantir a disponibilidade dos dados diante de interrupções de origem natural ou humana.
Restauração do Sistema
A restauração do sistema é uma ferramenta de recuperação que permite restabelecer determinados arquivos e informações para uma condição anterior.
Com a restauração do sistema, é possível recuperar chaves de registro, programas instalados, drivers, arquivos de sistema e outros, para versões anteriores. Essa ferramenta é uma importante defesa em muitos tipos de desastres.
Plano de Testes
Um plano de testes é um documento que armazena informações sobre estratégias, estimativas, recursos, prazos, objetivos e cronogramas de testes. Ele funciona como um guia para a execução de testes que garantem a segurança do hardware e software.
Ele inclui vários testes, de acordo com os procedimentos e etapas planejados, para gerenciar os efeitos posteriores de um desastre. Realize testes regularmente para garantir que sua organização esteja preparada para todos os cenários. Desta forma, a infraestrutura de TI pode identificar deficiências e se preparar para as situações adversas.
Conclusão
Ninguém sabe quando um desastre pode ocorrer. Portanto, medidas de segurança e proteção adequadas são essenciais para todas as empresas.
Compreender a terminologia de recuperação de desastres o ajudará a saber como reagir a ataques e desastres. Isso também ajudará você a se preparar para proteger sua infraestrutura durante eventos inesperados. Com um plano de recuperação de desastres eficaz, você pode economizar recursos financeiros e manter a confiança dos clientes.