

Data Lakehouse é uma arquitetura de gerenciamento de dados nova e emergente que combina as melhores partes de um data lake e um data warehouse. Usando um data lakehouse, você consegue armazenar diferentes tipos de dados em uma única plataforma e realizar consultas e análises compatíveis com ACID.
Então, por que usar um data lakehouse? Sendo um engenheiro de software sênior, posso entender como fica difícil quando você precisa gerenciar e manter dois sistemas separados e ter grandes volumes de fluxo de dados de um para outro.
Se quiser usar seus dados para executar análises de negócios e gerar relatórios, você precisará armazenar dados estruturados em um data warehouse. Por outro lado, para armazenar todos os dados provenientes de diversas fontes de dados e em seu formato original, é necessário um data lake. Ter uma única casa no lago elimina a necessidade de manter sistemas diferentes, pois traz o melhor dos dois mundos.
últimas postagens
Significado do Data Lakehouse

Para expandir sua organização e seu negócio, você precisa ser capaz de armazenar e analisar dados, independentemente do formato ou estrutura. Os data lakehouses são importantes para o gerenciamento de dados moderno porque atendem às limitações dos data lakes e dos data warehouses.
Seus data lakes muitas vezes podem se transformar em pântanos de dados, onde os dados são despejados sem qualquer estrutura ou governança. Isto dificulta a localização e utilização dos dados e também pode levar a problemas de qualidade dos dados. Por outro lado, ter um data warehouse muitas vezes leva você a ser muito rígido. Também fica caro.
Um data lakehouse tem seu próprio conjunto de características. Vamos dar uma olhada neles.
Características de um Data Lakehouse
Antes de mergulhar na arquitetura do data lakehouse, vamos ver os recursos ou características mais importantes de um data lakehouse.
Arquitetura do Data Lakehouse
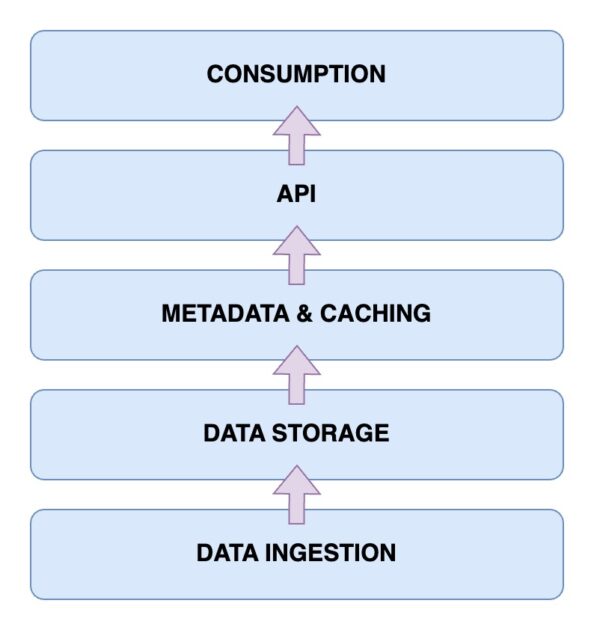
Agora é hora de dar uma olhada na arquitetura de um data lakehouse. Compreender a arquitetura do data lakehouse é fundamental para entender como ela funciona. A arquitetura do data lakehouse tem principalmente cinco componentes principais. Vamos examiná-los um por um.
Camada de ingestão de dados
Esta é a camada onde são capturados todos os diferentes dados nos seus diversos formatos. Podem ser alterações de dados em seu banco de dados primário, dados de vários sensores IoT ou dados do usuário em tempo real fluindo através de fluxos de dados.
Camada de armazenamento de dados
Depois que os dados forem ingeridos de diversas fontes, é hora de armazená-los em seus formatos adequados. É aqui que entra a sua camada de armazenamento. Os dados podem ser armazenados em vários meios, como AWS S3. Efetivamente, este é o seu data lake.
Camada de metadados e cache
Agora que você tem sua camada de armazenamento de dados instalada, você precisa de uma camada de metadados e gerenciamento de dados. Isso fornece uma visão unificada de todos os dados presentes no data lake. Esta também é a camada que adiciona transações ACID ao data lake existente para transformá-lo em um data lakehouse.
Camada API
Você pode acessar os dados indexados da camada de metadados usando a camada API. Eles podem estar na forma de drivers de banco de dados que permitem executar suas consultas por meio de código. Ou estes podem ser expostos na forma de endpoints que podem ser acessados de qualquer cliente.
Camada de consumo de dados
Essa camada compreende suas ferramentas de análise e Business Intelligence, que são os principais usuários dos dados do data lakehouse. Você pode executar seus programas de aprendizado de máquina aqui para obter insights valiosos dos dados armazenados e indexados.
Então, agora você tem uma imagem clara da arquitetura da casa do lago. Mas como você constrói um?
Etapas para construir um Data Lakehouse
Vejamos como você pode construir seu próprio data lakehouse. Quer você tenha um data lake ou warehouse existente ou esteja construindo um lakehouse do zero, as etapas permanecem semelhantes.
A seguir, vamos ver como você pode migrar para um data lakehouse se já tiver uma solução de gerenciamento de dados.
Etapas para migrar para um Data Lakehouse
Ao migrar sua carga de trabalho de dados para uma solução data lakehouse, há certas etapas que você deve ter em mente. Ter um plano de ação permite evitar problemas de última hora.
Etapa 1: analisar os dados
A etapa inicial e uma das mais cruciais para qualquer migração bem-sucedida é a análise de dados. Com uma análise adequada, você pode definir o escopo da sua migração. Além disso, permite identificar todas as dependências adicionais que você possa ter. Agora você tem uma visão geral mais ampla do seu ambiente e do que está prestes a migrar. Isso permite que você priorize melhor suas tarefas.
Etapa 2: preparar os dados para migrações
A próxima etapa para uma migração bem-sucedida é a preparação dos dados. Isso inclui os dados que você migrará, bem como as estruturas de dados de suporte necessárias. Em vez de esperar cegamente que todos os seus dados estejam disponíveis em seu lago, saber quais conjuntos de dados e colunas você realmente precisa pode economizar tempo e recursos valiosos.
Etapa 3: converta os dados para o formato necessário
Você pode aproveitar a conversão automática. Na verdade, você deve preferir ferramentas de conversão automática tanto quanto possível. As conversões de dados ao migrar para o data lakehouse podem ser complicadas. Felizmente, a maioria das ferramentas vem com código SQL de fácil leitura ou soluções de baixo código. Ferramentas como Alquimista ajude com isso.
Etapa 4: validar os dados após a migração
Assim que a migração for concluída, é hora de validar os dados. Aqui, você deve tentar automatizar o processo de validação tanto quanto possível. Caso contrário, a migração manual se tornará tediosa e retardará você. Deve ser usado apenas como último recurso. É importante verificar se os seus processos empresariais e trabalhos de dados permanecem inalterados após a migração.
Principais recursos do Data Lakehouse
🔷 Gerenciamento completo de dados – você obtém recursos de gerenciamento de dados que ajudam você a aproveitar ao máximo seus dados. Isso inclui limpeza de dados, processo ETL ou Extract-Transform-Load e aplicação de esquema. Assim, você pode higienizar e preparar prontamente seus dados para análises adicionais e ferramentas de BI (Business Intelligence).
🔷 Formatos de armazenamento abertos – O formato de armazenamento em que seus dados são salvos é aberto e padronizado. Isso significa que os dados que você coleta de diferentes fontes são todos armazenados de forma semelhante e você pode trabalhar com eles desde o início. Suporta formatos como AVRO, ORC ou Parquet. Além disso, eles também suportam formatos de dados tabulares.
🔷 Separação de armazenamento – você pode dissociar seu armazenamento dos recursos de computação. Isto é conseguido usando clusters separados para ambos. Portanto, você pode aumentar seu armazenamento separadamente conforme necessário, sem precisar fazer alterações desnecessárias em seus recursos de computação.
🔷 Suporte para streaming de dados – Tomar decisões baseadas em dados geralmente envolve o consumo de fluxos de dados em tempo real. Comparado a um data warehouse padrão, um data lakehouse oferece suporte para ingestão de dados em tempo real.
🔷 Governança de Dados – Apoia uma governança forte. Além disso, você também obtém recursos de auditoria. Estes são especialmente importantes para manter a integridade dos dados.
🔷 Custos de dados reduzidos – O custo operacional de operação de um data lakehouse é comparativamente menor do que um data warehouse. Você pode obter armazenamento de objetos em nuvem para suas crescentes necessidades de dados por um preço menor. Além disso, você obtém uma arquitetura híbrida. Assim, você pode eliminar a necessidade de manter vários sistemas de armazenamento de dados.
Data Lake x Data Warehouse x Data Lakehouse
FeatureData LakeData WarehouseData LakehouseData StorageArmazena dados brutos ou não estruturadosArmazena dados processados e estruturadosArmazena dados brutos e estruturadosEsquema de dadosNão tem um esquema fixoTem um esquema fixoUsa esquema de código aberto para integraçõesTransformação de dadosOs dados não são transformadosETL extensivo é necessárioETL é feito conforme necessárioConformidade com ACIDSem conformidade com ACIDACID – compatívelCompatível com ACIDDesempenho de consultaNormalmente mais lento, pois os dados não são estruturadosMuito rápido por causa dos dados estruturadosRápido por causa dos dados semiestruturadosCustoO armazenamento é econômicoMaiores custos de armazenamento e consultaO custo de armazenamento e consulta é equilibradoGovernança de dadosRequer governança cuidadosaGovernança forte necessáriaSuporta medidas de governançaAnálise em tempo realAnálise limitada em tempo realLimitação real- análise de tempoSuporta análises em tempo realCasos de usoArmazenamento de dados, exploração, ML e AIRelatórios e análises usando BIAprendizado de máquina e análise
Conclusão
Ao combinar perfeitamente os pontos fortes dos data lakes e dos data warehouses, um data lakehouse aborda desafios importantes que você pode enfrentar no gerenciamento e na análise de seus dados.
Agora você conhece as características e a arquitetura de uma casa no lago. A importância de um data lakehouse é evidente em sua capacidade de trabalhar com dados estruturados e não estruturados, oferecendo uma plataforma unificada para armazenamento, consulta e análise. Além disso, você também obtém conformidade com ACID.
Com as etapas mencionadas neste artigo sobre como criar e migrar para um data lakehouse, você pode aproveitar os benefícios de uma plataforma de gerenciamento de dados unificada e econômica. Fique por dentro do cenário moderno de gerenciamento de dados e impulsione a tomada de decisões, análises e crescimento dos negócios baseados em dados.
A seguir, confira nosso artigo detalhado sobre replicação de dados.