Um Data Lakehouse representa uma arquitetura inovadora no gerenciamento de dados, que integra os melhores aspectos de um data lake e um data warehouse. Ao adotar um data lakehouse, você centraliza o armazenamento de diversos tipos de dados em uma única plataforma, beneficiando-se de consultas e análises que respeitam as propriedades ACID.
Mas por que escolher um data lakehouse? Como engenheiro de software experiente, compreendo os desafios de manter dois sistemas distintos e de gerenciar o fluxo de grandes volumes de dados entre eles.
Para análises de negócios e geração de relatórios, o data warehouse é tradicionalmente usado para dados estruturados. Por outro lado, um data lake é necessário para armazenar dados brutos e diversificados, mantendo seu formato original. O data lakehouse elimina essa necessidade de sistemas separados, oferecendo o melhor dos dois mundos.
A Importância do Data Lakehouse

Para o crescimento de qualquer organização, é crucial ter a capacidade de armazenar e analisar dados de qualquer formato ou estrutura. Os data lakehouses são vitais para o gerenciamento de dados moderno, pois eles superam as limitações dos data lakes e data warehouses.
Data lakes podem se tornar verdadeiros “pântanos de dados” se não houver uma estrutura ou governança. Isso dificulta a localização e o uso dos dados, e pode causar problemas de qualidade. Data warehouses, por outro lado, podem ser muito rígidos e caros.
Um data lakehouse possui um conjunto específico de características. Vamos explorá-las.
Características de um Data Lakehouse
Antes de mergulharmos na arquitetura de um data lakehouse, vamos conhecer seus principais recursos:
- Suporte a Transações: Em um data lakehouse de porte médio ou grande, múltiplas operações de leitura e escrita ocorrem simultaneamente. A conformidade com ACID garante a integridade dos dados durante estas operações concorrentes.
- Business Intelligence Facilitado: Ferramentas de BI podem ser conectadas diretamente aos dados indexados, eliminando a necessidade de cópia e acelerando a obtenção de insights com custos reduzidos.
- Separação de Camadas: A separação entre as camadas de armazenamento e computação permite escalar cada uma delas independentemente, sem afetar a outra.
- Suporte a Diversos Tipos de Dados: Construído sobre um data lake, o data lakehouse suporta uma variedade de tipos e formatos de dados, incluindo áudio, vídeo, imagens e texto.
- Abertura em Formatos de Armazenamento: O uso de formatos abertos e padronizados, como o Apache Parquet, facilita a conexão de diversas ferramentas e bibliotecas.
- Flexibilidade para Cargas de Trabalho: Um data lakehouse suporta várias cargas de trabalho, incluindo consultas SQL, BI, análises e aprendizado de máquina.
- Streaming em Tempo Real: Elimina a necessidade de armazenamento e pipeline separados para análises em tempo real.
- Governança de Esquema: Promove uma governança de dados robusta e facilidade de auditoria.
Arquitetura do Data Lakehouse
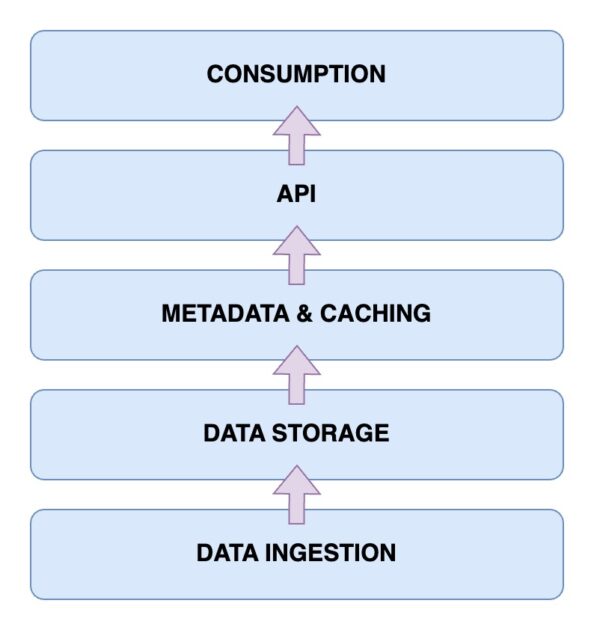
Entender a arquitetura de um data lakehouse é fundamental para saber como ele opera. Esta arquitetura é composta principalmente por cinco camadas principais:
Camada de Ingestão de Dados
Esta camada é responsável pela captura de dados em seus diversos formatos, seja de bancos de dados primários, sensores IoT ou fluxos de dados de usuários em tempo real.
Camada de Armazenamento de Dados
Após a ingestão, os dados são armazenados em seus formatos adequados em diversos meios, como AWS S3. Esta camada é, efetivamente, o seu data lake.
Camada de Metadados e Cache
Esta camada fornece uma visão unificada dos dados presentes no data lake e adiciona as propriedades ACID necessárias para transformar um data lake em um data lakehouse.
Camada API
A camada API permite acessar os dados indexados através de drivers de banco de dados ou endpoints, facilitando a consulta e o acesso pelos clientes.
Camada de Consumo de Dados
Esta camada inclui as ferramentas de análise e Business Intelligence que utilizam os dados do data lakehouse para gerar insights valiosos.
Agora que temos uma visão clara da arquitetura, como construímos um data lakehouse?
Etapas para Construir um Data Lakehouse
As etapas para construir um data lakehouse são similares, quer você esteja começando do zero ou a partir de um data lake ou warehouse já existente:
- Identificação de Requisitos: Defina os tipos de dados que serão armazenados e os casos de uso pretendidos, como modelos de aprendizado de máquina, relatórios de negócios ou análises.
- Criação de um Pipeline de Ingestão: Implemente o pipeline que irá trazer os dados para o sistema, usando barramentos de mensagens como Apache Kafka ou expondo endpoints de API.
- Construção da Camada de Armazenamento: Se você já tem um data lake, use-o como camada de armazenamento. Caso contrário, escolha entre opções como AWS S3, HDFS ou Delta Lake.
- Aplicação de Processamento de Dados: Extraia e transforme os dados com base nas necessidades do negócio usando ferramentas como o Apache Spark.
- Criação de Gerenciamento de Metadados: Rastreie e armazene os tipos de dados e suas propriedades para facilitar sua catalogação e busca. Adicione uma camada de cache, se necessário.
- Fornecimento de Opções de Integração: Habilite a conexão de ferramentas externas para acessar os dados, como consultas SQL, ferramentas de aprendizado de máquina ou soluções de Business Intelligence.
- Implementação de Governança de Dados: Estabeleça políticas de governança de dados, incluindo controle de acesso, criptografia e auditoria para garantir qualidade, consistência e conformidade regulatória.
A seguir, vamos analisar a migração para um data lakehouse.
Etapas para Migrar para um Data Lakehouse
A migração para um data lakehouse requer planejamento para evitar problemas. Um plano de ação estruturado é fundamental.
Etapa 1: Análise dos Dados
A análise detalhada dos dados é o ponto de partida. Ela ajuda a definir o escopo da migração, identificar dependências e priorizar tarefas, fornecendo uma visão geral do ambiente e do que será migrado.
Etapa 2: Preparação dos Dados para a Migração
Prepare os dados e estruturas necessárias, evitando migrar tudo indiscriminadamente. Conhecer os conjuntos de dados e colunas necessários economiza tempo e recursos.
Etapa 3: Conversão de Dados para o Formato Necessário
Use ferramentas de conversão automática sempre que possível para facilitar as conversões de dados. Ferramentas como Alchemist auxiliam neste processo.
Etapa 4: Validação dos Dados Após a Migração
Automatize a validação dos dados o máximo possível para evitar um processo manual demorado. Verifique se os processos de negócios e os trabalhos de dados funcionam corretamente após a migração.
Principais Características do Data Lakehouse
🔷 Gerenciamento Completo de Dados: Inclui recursos como limpeza de dados, ETL e aplicação de esquemas para preparar os dados para análise e BI.
🔷 Formatos de Armazenamento Abertos: O uso de formatos padronizados como AVRO, ORC ou Parquet garante a compatibilidade entre diferentes fontes de dados.
🔷 Separação de Armazenamento: A dissociação entre armazenamento e computação permite escalar cada recurso separadamente.
🔷 Suporte a Streaming de Dados: Permite a ingestão de dados em tempo real, facilitando decisões baseadas em informações atualizadas.
🔷 Governança de Dados: Oferece mecanismos robustos de governança e auditoria para manter a integridade dos dados.
🔷 Custos Reduzidos: O custo operacional de um data lakehouse é geralmente menor do que o de um data warehouse, aproveitando armazenamento de objetos em nuvem e uma arquitetura híbrida.
Data Lake x Data Warehouse x Data Lakehouse
| Característica | Data Lake | Data Warehouse | Data Lakehouse |
| Armazenamento de Dados | Dados brutos ou não estruturados | Dados processados e estruturados | Dados brutos e estruturados |
| Esquema de Dados | Sem esquema fixo | Esquema fixo | Esquema de código aberto para integrações |
| Transformação de Dados | Dados não transformados | ETL extensivo necessário | ETL feito conforme necessário |
| Conformidade com ACID | Sem conformidade com ACID | ACID – compatível | Compatível com ACID |
| Desempenho de Consulta | Lento devido à falta de estrutura | Rápido devido aos dados estruturados | Rápido devido aos dados semiestruturados |
| Custo | Armazenamento econômico | Maiores custos de armazenamento e consulta | Custo de armazenamento e consulta equilibrado |
| Governança de Dados | Requer governança cuidadosa | Governança forte necessária | Suporta medidas de governança |
| Análise em Tempo Real | Análise limitada em tempo real | Limitação em análise em tempo real | Suporta análises em tempo real |
| Casos de Uso | Armazenamento, exploração, ML e AI | Relatórios e análises usando BI | Aprendizado de máquina e análise |
Conclusão
O data lakehouse combina o melhor de data lakes e data warehouses, solucionando desafios de gerenciamento e análise de dados. Ele oferece uma plataforma unificada para trabalhar com dados estruturados e não estruturados, além de garantir a conformidade com ACID.
Com as etapas descritas neste artigo, você pode construir ou migrar para um data lakehouse, aproveitando os benefícios de uma plataforma de gerenciamento de dados unificada e econômica. Mantenha-se atualizado no cenário moderno de gerenciamento de dados e impulsione decisões, análises e crescimento dos negócios com base em dados.
Para mais informações, confira nosso artigo detalhado sobre replicação de dados.