Repositório de dados. Lago de dados. Arquitetura Lakehouse. Se nenhuma dessas expressões lhe parece familiar, é provável que sua função não esteja diretamente ligada ao universo dos dados.
Contudo, essa seria uma premissa bastante improvável, visto que, na atualidade, praticamente tudo está conectado aos dados. Ou, como os líderes corporativos costumam expressar:
- Negócios fundamentados e direcionados por dados.
- Dados disponíveis em qualquer lugar, a qualquer momento e de todas as formas.
O Ativo Mais Relevante
Os dados se consolidaram como o ativo mais valioso para um número crescente de empresas. Grandes corporações sempre geraram vastos volumes de dados, lembrando que há cerca de 10-15 anos, falava-se em terabytes de novas informações a cada mês. Hoje em dia, essa quantidade de dados pode ser gerada em apenas alguns dias. Surge, então, a questão da real necessidade desses dados, mesmo que nem todos sejam efetivamente utilizados. E a resposta é: definitivamente, não! 😃
Nem todo o conteúdo gerado será útil, e alguns dados podem nunca ser acessados. Muitas vezes, presenciei situações em que empresas geraram imensas quantidades de dados, apenas para que se tornassem inúteis após uma carga inicial bem-sucedida.
Entretanto, essa preocupação está se tornando obsoleta. O armazenamento de dados, agora na nuvem, tem custos acessíveis, as fontes de dados crescem de forma exponencial e é impossível prever as necessidades futuras, especialmente quando novos serviços são incorporados ao sistema. Nesse cenário, até mesmo dados antigos podem se tornar valiosos.
Portanto, a estratégia predominante é armazenar o máximo possível de dados, mas de maneira otimizada. O objetivo é que os dados sejam não apenas armazenados de forma eficaz, mas também que possam ser consultados, reutilizados, transformados e distribuídos posteriormente.
Vamos explorar três abordagens nativas para realizar essa tarefa na AWS:
- Athena Database: uma solução econômica e eficiente, embora simples, para a criação de um data lake na nuvem.
- Redshift Database: uma versão robusta de data warehouse na nuvem, com potencial para substituir muitas soluções locais incapazes de lidar com o crescimento exponencial dos dados.
- Databricks: uma combinação de data lake e data warehouse em uma única solução, com recursos adicionais.
Data Lake com AWS Athena
Fonte: aws.amazon.com
Um data lake é um local para armazenar dados de forma rápida, independentemente de serem não estruturados, semiestruturados ou estruturados. A ideia é que esses dados não sejam modificados após o armazenamento, mas sim mantidos em sua forma mais original e imutável. Isso garante um maior potencial de reutilização em etapas futuras. A perda dessa característica atômica dos dados logo após o primeiro carregamento em um data lake torna impossível recuperar as informações originais.
O AWS Athena é um banco de dados que armazena diretamente em buckets S3, sem a necessidade de clusters de servidores em segundo plano. Isso o torna um serviço de data lake extremamente econômico. Formatos de arquivos estruturados, como Parquet ou CSV, auxiliam na organização dos dados. O bucket S3 armazena os arquivos, e o Athena os referencia sempre que os processos selecionam dados do banco de dados.
O Athena não suporta diversas funcionalidades consideradas padrão, como declarações de atualização. Por esse motivo, o Athena é uma opção bastante simplificada. Por outro lado, essa limitação impede a modificação de seu data lake atômico, simplesmente porque essa ação não é possível 😐.
Ele oferece suporte a indexação e particionamento, o que facilita a execução eficiente de instruções de seleção e a criação de blocos de dados logicamente separados (por exemplo, por data ou colunas de chave). Além disso, a escalabilidade horizontal é simples, bastando adicionar novos buckets à infraestrutura.

Prós e Contras
Vantagens a serem consideradas:
- O baixo custo do Athena (composto apenas por buckets S3 e custos de uso de SQL por demanda) é a vantagem mais relevante. Se o objetivo é criar um data lake acessível na AWS, essa é a escolha ideal.
- Como um serviço nativo, o Athena se integra facilmente a outros serviços úteis da AWS, como o Amazon QuickSight para visualização de dados ou o AWS Glue Data Catalog para criar metadados estruturados persistentes.
- Ideal para executar consultas ad hoc em grandes volumes de dados estruturados ou não estruturados, sem a necessidade de manter uma infraestrutura complexa.
Desvantagens a serem consideradas:
- O Athena não é particularmente eficiente para retornar rapidamente consultas de seleção complexas, especialmente se as consultas não seguirem as suposições do modelo de dados projetado para solicitar os dados do data lake.
- Isso também o torna menos flexível em relação a possíveis mudanças futuras no modelo de dados.
- O Athena não oferece nenhuma funcionalidade avançada adicional pronta para uso. Se algum recurso específico for necessário, ele precisará ser implementado em uma camada superior.
- Se os dados do data lake forem usados em uma camada de apresentação mais avançada, muitas vezes a única opção é combiná-lo com outro serviço de banco de dados mais adequado para essa finalidade, como AWS Aurora ou AWS Dynamo DB.
Objetivo e Caso de Uso Real
O Athena é a melhor opção quando o objetivo é criar um data lake simples, sem funcionalidades avançadas semelhantes às de um data warehouse. Por exemplo, se não houver a necessidade de executar consultas analíticas de alto desempenho com frequência. Nesse caso, a prioridade é ter um pool de dados imutáveis, com fácil expansão do armazenamento.
A preocupação com a falta de espaço deixa de ser um problema. O custo do armazenamento de buckets S3 pode ser reduzido ainda mais com a implementação de uma política de ciclo de vida dos dados. Isso significa mover dados entre diferentes tipos de depósitos S3, direcionados mais para fins de arquivamento, com tempos de retorno de ingestão mais lentos, porém custos menores.
Uma característica importante do Athena é a criação automática de um arquivo contendo os dados resultantes de uma consulta SQL. Esse arquivo pode ser utilizado para diversos fins, tornando o Athena uma boa opção para ambientes com muitos serviços lambda processando dados em várias etapas. Cada resultado lambda se tornará automaticamente um arquivo estruturado pronto para o processamento seguinte.
O Athena é adequado em situações em que um grande volume de dados brutos chega à sua infraestrutura na nuvem e não há necessidade de processá-los no momento da carga. Nesse cenário, o necessário é um armazenamento rápido na nuvem, com uma estrutura de fácil compreensão.
Outro caso de uso seria criar um espaço dedicado para arquivamento de dados para outro serviço. Nesse caso, o Athena DB se torna um local de backup de baixo custo para dados que não são necessários no momento, mas que podem ser úteis no futuro. Nesse ponto, você apenas ingere os dados e os envia para outros destinos.
Data Warehouse com AWS Redshift
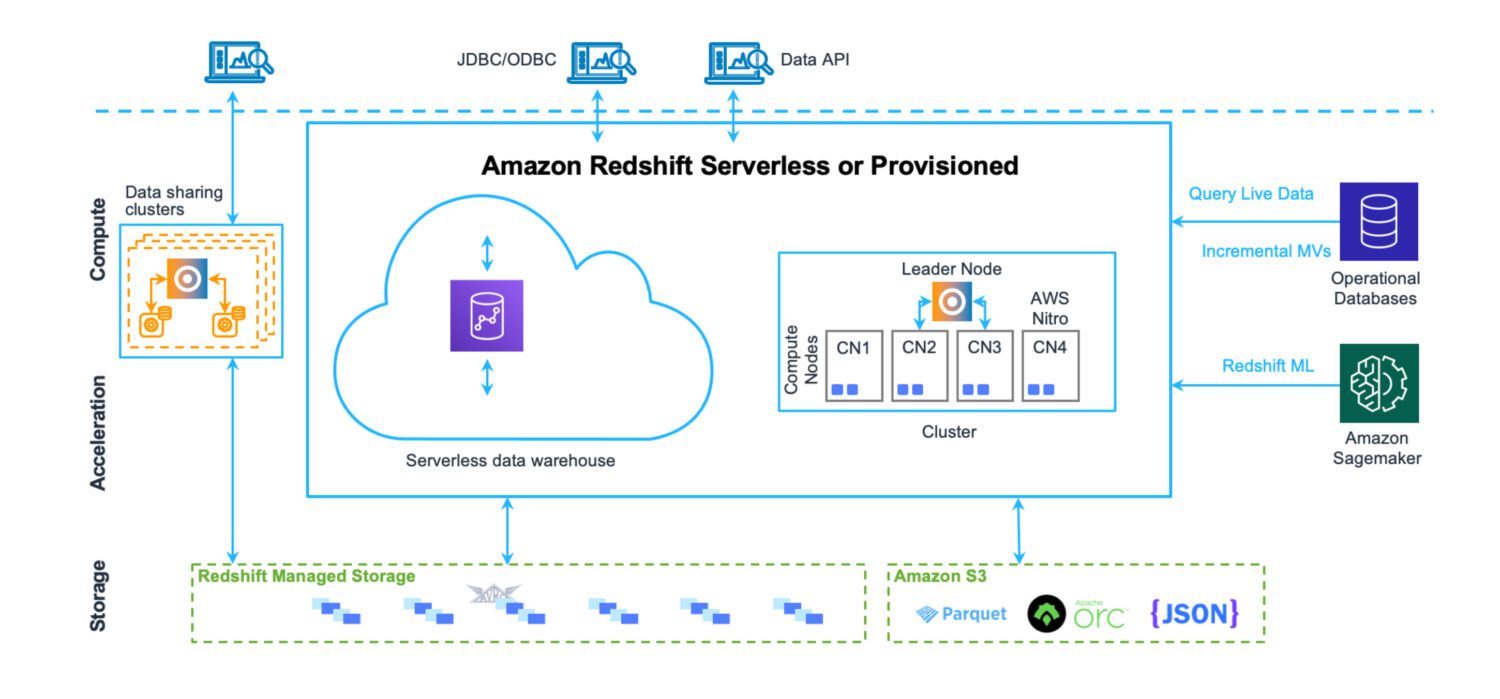 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Um data warehouse é um local onde os dados são armazenados de forma altamente estruturada, facilitando o carregamento e a extração. O objetivo é executar um grande número de consultas complexas, unindo várias tabelas por meio de junções intricadas. Diversas funções analíticas são disponibilizadas para calcular estatísticas sobre os dados existentes. O objetivo final é extrair previsões e insights para embasar decisões de negócios futuras, usando dados históricos.
O Redshift é um sistema completo de data warehouse, com servidores de cluster para ajuste e dimensionamento horizontal e vertical, e um sistema de armazenamento de banco de dados otimizado para retornos rápidos de consultas complexas. Atualmente, o Redshift também pode ser executado no modo serverless. Não há arquivos no S3 ou similares. Trata-se de um servidor de cluster de banco de dados padrão, com seu próprio formato de armazenamento.
O Redshift oferece ferramentas de monitoramento de desempenho e painéis personalizáveis para acompanhar e ajustar o desempenho para seu caso de uso. A administração também é acessível por meio de painéis específicos. Embora seja necessário algum esforço para compreender todos os recursos e configurações e como eles afetam o cluster, o processo não é tão complexo como a administração de servidores Oracle, no caso de soluções locais.
Embora existam algumas limitações impostas pela AWS ao Redshift, que definem como usá-lo no dia a dia (como limites na quantidade de usuários ativos simultâneos ou sessões em um cluster de banco de dados), a velocidade com que as operações são executadas ajuda a contornar esses limites até certo ponto.

Prós e Contras
Vantagens a serem consideradas:
- Serviço de armazenamento de dados nativo da AWS, fácil de integrar com outros serviços.
- Um local centralizado para armazenar, monitorar e ingerir diversos tipos de fontes de dados de sistemas de origem distintos.
- Disponibilidade de um data warehouse serverless, eliminando a necessidade de manter uma infraestrutura.
- Otimizado para análises e relatórios de alto desempenho. Ao contrário de uma solução de data lake, existe um modelo de dados relacional para armazenar todos os dados recebidos.
- O mecanismo de banco de dados Redshift é baseado no PostgreSQL, garantindo alta compatibilidade com outros sistemas de banco de dados.
- Instruções COPY e UNLOAD para carregar e descarregar dados de e para buckets S3.
Desvantagens a serem consideradas:
- O Redshift não suporta um grande número de sessões ativas simultâneas. As sessões são colocadas em espera e processadas sequencialmente. Embora isso não seja um problema na maioria dos casos, devido à velocidade das operações, é um fator limitante em sistemas com muitos usuários ativos.
- Embora o Redshift ofereça muitos recursos de sistemas Oracle, ele ainda não está no mesmo nível. Alguns recursos esperados podem não estar disponíveis (como gatilhos de banco de dados) ou podem ser suportados de forma limitada (como visualizações materializadas).
- Sempre que um trabalho de processamento de dados personalizado mais avançado for necessário, ele precisará ser criado do zero, utilizando principalmente as linguagens Python ou Javascript. O processo não é tão natural como com PL/SQL no caso do sistema Oracle, onde até mesmo funções e procedimentos utilizam uma linguagem muito similar às consultas SQL.
Objetivo e Caso de Uso Real
O Redshift pode ser o armazenamento central para diversas fontes de dados anteriormente localizadas fora da nuvem. É um substituto válido para as soluções anteriores de data warehouse da Oracle. Como também é um banco de dados relacional, a migração do Oracle é uma operação relativamente simples.
O Redshift é uma excelente opção quando existem soluções de data warehouse espalhadas em vários lugares, sem uma abordagem, estrutura ou conjunto predefinido de processos comuns para execução sobre os dados.
O Redshift possibilita a consolidação de sistemas de armazenamento de dados de diferentes locais sob o mesmo teto. É possível separá-los por país, garantindo que os dados estejam seguros e acessíveis somente para quem precisa. Ao mesmo tempo, o Redshift permite criar uma solução de warehouse unificada que abrange todos os dados corporativos.
Outro caso de uso é a construção de uma plataforma de data warehouse com amplo suporte para autoatendimento. Os usuários podem criar seus próprios conjuntos de processamento sem que eles façam parte da solução comum da plataforma. Esses serviços permanecem acessíveis apenas para seus criadores ou para grupos definidos por eles, sem afetar os demais usuários.
Confira nossa comparação entre Datalake e Datawarehouse.
Lakehouse com Databricks na AWS
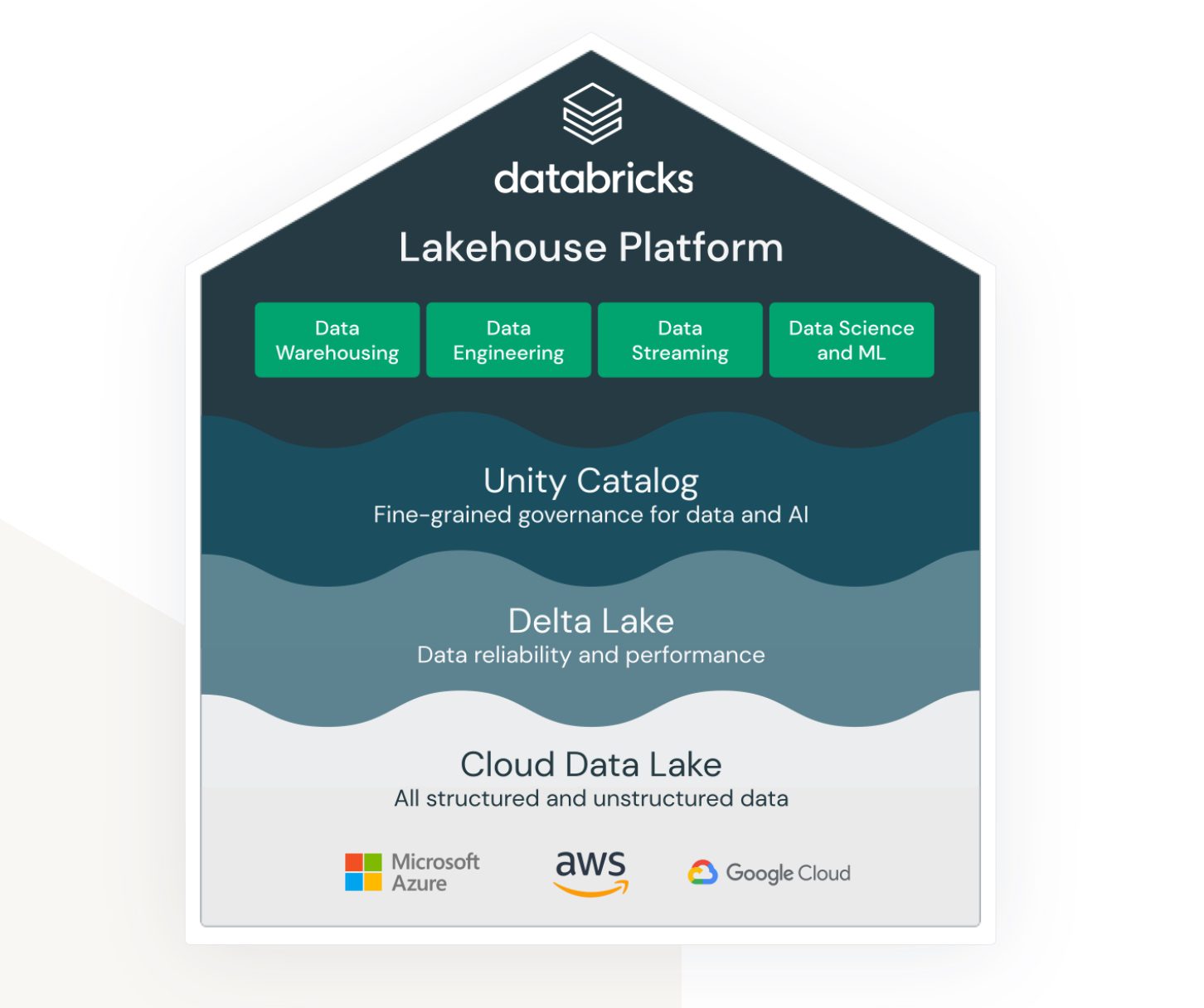 Fonte: databricks.com
Fonte: databricks.com
O termo Lakehouse está intimamente ligado ao serviço Databricks. Embora não seja um serviço nativo da AWS, ele opera dentro do ecossistema AWS de forma eficiente, oferecendo diversas opções de conexão e integração com outros serviços da AWS.
O Databricks visa unificar áreas distintas:
- Uma solução para armazenamento de data lake de dados não estruturados, semiestruturados e estruturados.
- Uma solução para armazenamento de dados estruturados e dados de consulta de acesso rápido (também conhecido como Delta Lake).
- Uma solução que suporta análise e computação de aprendizado de máquina no data lake.
- Governança de dados para todas as áreas acima, com administração centralizada e ferramentas prontas para uso para aumentar a produtividade de diferentes tipos de desenvolvedores e usuários.
O Databricks é uma plataforma comum que engenheiros de dados, desenvolvedores SQL e cientistas de dados de aprendizado de máquina podem usar simultaneamente. Cada grupo dispõe de um conjunto de ferramentas específico para realizar suas tarefas.
Portanto, o Databricks propõe uma solução abrangente, combinando os benefícios do data lake e do data warehouse em um único ambiente. Além disso, ele oferece ferramentas para testar e executar modelos de aprendizado de máquina diretamente em armazenamentos de dados já criados.

Prós e Contras
Vantagens a serem consideradas:
- O Databricks é uma plataforma de dados altamente escalável. Ele se adapta ao tamanho da carga de trabalho de forma automática.
- Um ambiente colaborativo para cientistas de dados, engenheiros de dados e analistas de negócios. A possibilidade de realizar todas essas funções no mesmo espaço é um grande benefício, não apenas do ponto de vista organizacional, mas também por evitar a necessidade de ambientes separados.
- O AWS Databricks se integra perfeitamente a outros serviços da AWS, como Amazon S3, Amazon Redshift e Amazon EMR. Isso permite que os usuários transfiram dados facilmente entre os serviços e aproveitem todos os recursos da nuvem AWS.
Desvantagens a serem consideradas:
- A configuração e o gerenciamento do Databricks podem ser complexos, especialmente para usuários iniciantes no processamento de big data. É necessário um alto nível de conhecimento técnico para aproveitar ao máximo a plataforma.
- Embora o Databricks seja econômico em termos de seu modelo de preços de pagamento por uso, ele pode se tornar caro para projetos de processamento de dados em larga escala. O custo de uso da plataforma pode aumentar rapidamente, principalmente quando há necessidade de aumentar os recursos.
- O Databricks fornece uma variedade de ferramentas e modelos pré-criados, o que também pode limitar os usuários que precisam de mais opções de personalização. A plataforma pode não ser adequada para usuários que necessitam de mais flexibilidade e controle sobre seus fluxos de trabalho de processamento de big data.
Objetivo e Caso de Uso Real
O AWS Databricks é mais adequado para grandes corporações com grande volume de dados. Ele pode atender aos requisitos de carregamento e contextualização de várias fontes de dados de diferentes sistemas externos.
Muitas vezes, o requisito é fornecer dados em tempo real. Isso significa que, no momento em que os dados surgem no sistema de origem, os processos devem coletá-los, processá-los e armazená-los no Databricks de forma imediata ou com um atraso mínimo. Se o atraso for superior a um minuto, considera-se um processamento quase em tempo real. Ambos os cenários são geralmente alcançáveis com a plataforma Databricks, principalmente devido à grande quantidade de adaptadores e interfaces em tempo real que se conectam a outros serviços nativos da AWS.
O Databricks também se integra facilmente aos sistemas Informatica ETL. Quando a organização já utiliza extensivamente o ecossistema Informatica, o Databricks é uma adição compatível à plataforma.
Considerações Finais
À medida que o volume de dados continua crescendo de forma exponencial, é importante saber que existem soluções capazes de lidar com essa situação de maneira eficaz. O que antes era um pesadelo em termos de administração e manutenção agora exige muito pouco esforço administrativo. As equipes podem se concentrar na geração de valor a partir dos dados.
A escolha do serviço ideal depende das necessidades específicas. Embora o AWS Databricks seja uma alternativa a ser considerada em um segundo momento, as demais opções são mais flexíveis, mesmo que com menos recursos, especialmente seus modos serverless. A migração para outra solução posteriormente é um processo simples.