

Apache Kafka e RabbitMQ são dois agentes de mensagens amplamente utilizados que permitem o desacoplamento da troca de mensagens entre aplicativos. Quais são suas características mais importantes e o que os torna diferentes uns dos outros? Vamos aos conceitos.
últimas postagens
RabbitMQGenericName
RabbitMQ é um aplicativo de troca de mensagens de código aberto para comunicação e troca de mensagens entre as partes. Por ter sido desenvolvido em Erlang, é muito leve e eficiente. A linguagem Erlang foi desenvolvida pela Ericson com foco em sistemas distribuídos.
É considerado um corretor de mensagens mais tradicional. É baseado no padrão publicador-assinante, embora possa tratar a comunicação de forma síncrona ou assíncrona, dependendo do que for definido na configuração. Também garante a entrega e ordenação de mensagens entre produtores e consumidores.
Ele suporta os protocolos AMQP, STOMP, MQTT, HTTP e web socket. Três modelos de troca de mensagens: tópico, fanout e direto:
- Intercâmbio direto e individual por tópico ou tema [topic]
- Todos os consumidores conectados à fila recebem o [fanout] mensagem
- Cada consumidor recebe uma mensagem enviada [direct]
A seguir estão os componentes do RabbitMQ:
produtores
Os produtores são aplicativos que criam e enviam mensagens para o RabbitMQ. Eles podem ser qualquer aplicativo que possa se conectar ao RabbitMQ e publicar mensagens.
consumidores
Os consumidores são aplicativos que recebem e processam mensagens do RabbitMQ. Eles podem ser qualquer aplicativo que possa se conectar ao RabbitMQ e assinar mensagens.
Trocas
As trocas são responsáveis por receber mensagens dos produtores e encaminhá-las para as filas apropriadas. Existem vários tipos de trocas, incluindo trocas diretas, fanout, de tópicos e de cabeçalhos, cada uma com suas próprias regras de roteamento.
Filas
As filas são onde as mensagens são armazenadas até serem consumidas pelos consumidores. Eles são criados por aplicativos ou automaticamente pelo RabbitMQ quando uma mensagem é publicada em uma troca.
Ligações
As ligações definem o relacionamento entre trocas e filas. Eles especificam as regras de roteamento para mensagens, que são usadas pelas trocas para rotear mensagens para as filas apropriadas.
Arquitetura do RabbitMQ
RabbitMQ usa um modelo pull para entrega de mensagens. Nesse modelo, os consumidores solicitam ativamente as mensagens do corretor. As mensagens são publicadas nas trocas responsáveis pelo roteamento de mensagens para as filas apropriadas com base nas chaves de roteamento.
A arquitetura do RabbitMQ é baseada em uma arquitetura cliente-servidor e consiste em vários componentes que trabalham juntos para fornecer uma plataforma de mensagens confiável e escalável. O conceito AMQP prevê os componentes Exchanges, Queues, Bindings, bem como Publishers e Subscribers. Os editores publicam mensagens para trocas.
As trocas pegam essas mensagens e as distribuem para 0 a n filas com base em certas regras (vinculações). As mensagens armazenadas nas filas podem então ser recuperadas pelos consumidores. De forma simplificada, o gerenciamento de mensagens é feito no RabbitMQ da seguinte forma:
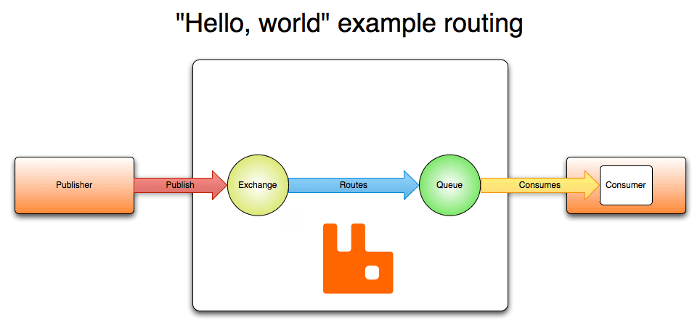 Fonte da imagem: VMware
Fonte da imagem: VMware
- Os editores enviam mensagens para troca;
- O Exchange envia mensagens para filas e outras trocas;
- Quando uma mensagem é recebida, o RabbitMQ envia confirmações aos remetentes;
- Os consumidores mantêm conexões TCP persistentes com o RabbitMQ e declaram qual fila estão recebendo;
- RabbitMQ roteia mensagens para consumidores;
- Os consumidores enviam confirmações de sucesso ou erro ao receber a mensagem;
- Após o recebimento bem-sucedido, a mensagem é removida da fila.
Apache Kafka
Apache Kafka é uma solução de mensagens de código aberto distribuída desenvolvida pelo LinkedIn em Scala. É capaz de processar mensagens e armazená-las com um modelo editor-assinante com alta escalabilidade e desempenho.

Para armazenar os eventos ou mensagens recebidas, distribua os tópicos entre os nós usando partições. Ele combina os padrões editor-assinante e de fila de mensagens e também é responsável por garantir a ordem das mensagens para cada consumidor.
Kafka é especializado em alta taxa de transferência de dados e baixa latência para lidar com fluxos de dados em tempo real. Isso é conseguido evitando muita lógica no lado do servidor (broker), bem como alguns detalhes especiais de implementação.
Por exemplo, Kafka não usa RAM e grava dados imediatamente no sistema de arquivos do servidor. Como todos os dados são gravados sequencialmente, o desempenho de leitura e gravação é alcançado, o que é comparável ao da RAM.
Estes são os principais conceitos do Kafka que o tornam escalável, de alto desempenho e tolerante a falhas:
Tema
Um tópico é uma forma de rotular ou categorizar uma mensagem; imagine um armário com 10 gavetas; cada gaveta pode ser um tópico, e o armário é a plataforma Apache Kafka, portanto, além de categorizá-lo agrupa mensagens, outra analogia melhor sobre o tópico seria apresentada em bancos de dados relacionais.
Produtor
O produtor ou produtor é aquele que se conecta a uma plataforma de mensagens e envia uma ou mais mensagens sobre um tema específico.
Consumidor
O consumidor é a pessoa que se conecta a uma plataforma de mensagens e consome uma ou mais mensagens sobre um tema específico.
Corretor
O conceito de broker na plataforma Kafka nada mais é do que praticamente o próprio Kafka, e é ele quem gerencia os tópicos e define a forma de armazenamento de mensagens, logs, etc.
Conjunto
O cluster é um conjunto de Brokers que se comunicam entre si ou não para melhor escalabilidade e tolerância a falhas.
Arquivo de log
Cada tópico armazena seus registros em formato de log, ou seja, de forma estruturada e sequencial; o arquivo de log, portanto, é o arquivo que contém as informações de um tópico.
Partições
As partições são a camada de partição de mensagens dentro de um tópico; esse particionamento garante a elasticidade, tolerância a falhas e escalabilidade do Apache Kafka para que cada tópico possa ter várias partições em locais diferentes.
Arquitetura do Apache Kafka
O Kafka é baseado em um modelo push para entrega de mensagens. Usando esse modelo, as mensagens no Kafka são ativamente enviadas aos consumidores. As mensagens são publicadas em tópicos, que são particionados e distribuídos entre diferentes brokers no cluster.
Os consumidores podem então se inscrever em um ou mais tópicos e receber mensagens à medida que são produzidas sobre esses tópicos.
No Kafka, cada tópico é dividido em uma ou mais partições. É na partição que os eventos terminam.
Se houver mais de um broker no cluster, as partições serão distribuídas igualmente entre todos os brokers (na medida do possível), o que permitirá escalar a carga de escrita e leitura em um tópico para vários brokers ao mesmo tempo. Como é um cluster, ele é executado usando o ZooKeeper para sincronização.
Ele recebe lojas e distribui registros. Um registro é um dado gerado por algum nó do sistema, podendo ser um evento ou uma informação. Ele é enviado para o cluster e o cluster o armazena em uma partição de tópico.
Cada registro tem um deslocamento de sequência e o consumidor pode controlar o deslocamento que está consumindo. Assim, caso haja necessidade de reprocessar o tópico, isso pode ser feito com base no offset.
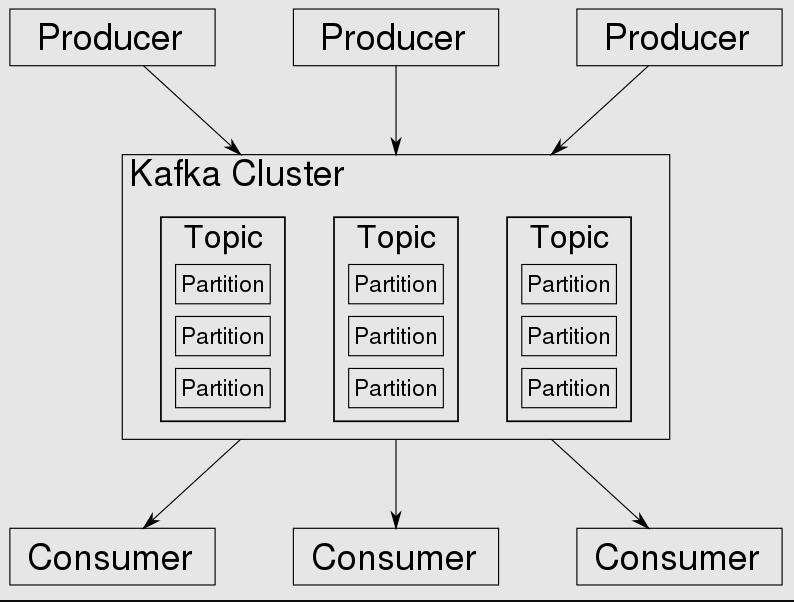 Fonte da imagem: Wikipédia
Fonte da imagem: Wikipédia
A lógica, como o gerenciamento do ID da última mensagem lida de um consumidor ou a decisão sobre em qual partição os dados recém-chegados são gravados, é completamente transferida para o cliente (produtor ou consumidor).
Além dos conceitos de produtor e consumidor, existem também os conceitos de tópico, partição e replicação.
Um tópico descreve uma categoria de mensagens. O Kafka atinge a tolerância a falhas replicando os dados em um tópico e escalando particionando o tópico em vários servidores.
RabbitMQ x Kafka
As principais diferenças entre o Apache Kafka e o RabbitMQ se devem aos modelos de entrega de mensagens fundamentalmente diferentes implementados nesses sistemas.
Em particular, o Apache Kafka opera com base no princípio de puxar (puxar) quando os próprios consumidores recebem as mensagens de que precisam do tópico.
O RabbitMQ, por outro lado, implementa o modelo push enviando as mensagens necessárias aos destinatários. Como tal, o Kafka difere do RabbitMQ das seguintes maneiras:
#1. Arquitetura
Uma das maiores diferenças entre RabbitMQ e Kafka é a diferença na arquitetura. O RabbitMQ usa uma arquitetura tradicional de fila de mensagens baseada em corretor, enquanto o Kafka usa uma arquitetura de plataforma de streaming distribuída.
Além disso, o RabbitMQ usa um modelo de entrega de mensagens baseado em pull, enquanto o Kafka usa um modelo baseado em push.
#2. Salvando mensagens
O RabbitMQ coloca a mensagem na fila FIFO (First Input – First Output) e monitora o status dessa mensagem na fila, e o Kafka adiciona a mensagem ao log (grava no disco), deixando o destinatário para obter o necessário informações do tópico.
O RabbitMQ exclui a mensagem depois que ela foi entregue ao destinatário, enquanto o Kafka armazena a mensagem até que seja agendado para limpar o log.
Assim, o Kafka salva o estado atual e todos os estados anteriores do sistema e pode ser usado como uma fonte confiável de dados históricos, ao contrário do RabbitMQ.
#3. Balanceamento de carga
Graças ao modelo pull de entrega de mensagens, o RabbitMQ reduz a latência. No entanto, é possível que os destinatários transbordem se as mensagens chegarem à fila mais rapidamente do que eles podem processá-las.
Como no RabbitMQ cada receptor solicita/carrega um número diferente de mensagens, a distribuição do trabalho pode se tornar desigual, o que causará atrasos e perda de ordem das mensagens durante o processamento.
Para evitar isso, cada receptor RabbitMQ configura um limite de pré-busca, um limite no número de mensagens não confirmadas acumuladas. No Kafka, o balanceamento de carga é realizado automaticamente redistribuindo os destinatários entre as seções (partição) do tópico.
#4. Roteamento
O RabbitMQ inclui quatro maneiras de rotear para diferentes exchanges para enfileiramento, permitindo um conjunto poderoso e flexível de padrões de mensagens. O Kafka implementa apenas uma maneira de gravar mensagens no disco sem roteamento.
#5. Ordenação de mensagens
O RabbitMQ permite manter a ordem relativa em conjuntos arbitrários (grupos) de eventos, e o Apache Kafka fornece uma maneira fácil de manter a ordem com escalabilidade, gravando mensagens sequencialmente em um log replicado (tópico).
FeatureRabbitMQKafka ArchitectureSalva mensagens em um disco anexado ao brokerArquitetura de plataforma de streaming distribuídaModelo de entregaBaseado em pullBaseado em pushSalvar mensagensNão pode salvar mensagensMantém pedidos gravando em um tópicoBalanceamento de cargaConfigura um limite de pré-buscaExecutado automaticamente RoteamentoInclui 4 maneiras de rotearTem apenas 1 maneira de rotear mensagensOrdenação de mensagensPermite manter a ordem em gruposMantém pedidos por gravação para o tópicoProcessos externosNão requer Exige a execução da instância do ZookeeperPluginsVários plug-insTem suporte de plug-in limitado
RabbitMQ e Kafka são sistemas de mensagens amplamente usados, cada um com seus próprios pontos fortes e casos de uso. O RabbitMQ é um sistema de mensagens flexível, confiável e escalável que se destaca no enfileiramento de mensagens, tornando-o uma escolha ideal para aplicativos que exigem entrega de mensagens confiável e flexível.
Por outro lado, o Kafka é uma plataforma de streaming distribuída projetada para processamento em tempo real e de alto rendimento de grandes volumes de dados, tornando-o uma ótima opção para aplicativos que exigem processamento e análise de dados em tempo real.
Principais casos de uso do RabbitMQ:
Comércio eletrônico

O RabbitMQ é usado em aplicativos de comércio eletrônico para gerenciar o fluxo de dados entre diferentes sistemas, como gerenciamento de estoque, processamento de pedidos e processamento de pagamentos. Ele pode lidar com grandes volumes de mensagens e garantir que sejam entregues de forma confiável e na ordem correta.
Assistência médica
No setor de saúde, o RabbitMQ é usado para trocar dados entre diferentes sistemas, como registros eletrônicos de saúde (EHRs), dispositivos médicos e sistemas de suporte à decisão clínica. Ele pode ajudar a melhorar o atendimento ao paciente e reduzir erros, garantindo que as informações certas estejam disponíveis no momento certo.
Serviços financeiros
O RabbitMQ permite mensagens em tempo real entre sistemas, como plataformas de negociação, sistemas de gerenciamento de risco e gateways de pagamento. Ele pode ajudar a garantir que as transações sejam processadas de forma rápida e segura.
sistemas IoT
O RabbitMQ é usado em sistemas IoT para gerenciar o fluxo de dados entre diferentes dispositivos e sensores. Ele pode ajudar a garantir que os dados sejam entregues com segurança e eficiência, mesmo em ambientes com largura de banda limitada e conectividade intermitente.
Kafka é uma plataforma de streaming distribuída projetada para lidar com grandes volumes de dados em tempo real.
Principais casos de uso do Kafka
Análise em tempo real

O Kafka é usado em aplicativos analíticos em tempo real para processar e analisar dados à medida que são gerados, permitindo que as empresas tomem decisões com base em informações atualizadas. Ele pode lidar com grandes volumes de dados e dimensionar para atender às necessidades até mesmo dos aplicativos mais exigentes.
Agregação de registros
O Kafka pode agregar logs de diferentes sistemas e aplicativos, permitindo que as empresas monitorem e solucionem problemas em tempo real. Ele também pode ser usado para armazenar logs para análises e relatórios de longo prazo.
Aprendizado de máquina
O Kafka é usado em aplicativos de aprendizado de máquina para transmitir dados para modelos em tempo real, permitindo que as empresas façam previsões e tomem medidas com base em informações atualizadas. Ele pode ajudar a melhorar a precisão e a eficácia dos modelos de aprendizado de máquina.
Minha opinião sobre RabbitMQ e Kafka
A desvantagem dos amplos e variados recursos do RabbitMQ para gerenciamento flexível de filas de mensagens é o aumento do consumo de recursos e, consequentemente, a degradação do desempenho sob cargas maiores. Como esse é o modo de operação de sistemas complexos, na maioria dos casos, o Apache Kafka é a melhor ferramenta para gerenciar mensagens.
Por exemplo, no caso de coletar e agregar muitos eventos de dezenas de sistemas e serviços, levando em consideração sua georeserva, métricas de clientes, arquivos de log e análises, com a perspectiva de aumentar as fontes de informação, preferirei usar Kafka, no entanto, se você estiver em uma situação em que só precisa de mensagens rápidas, o RabbitMQ fará o trabalho muito bem!
Você também pode ler como instalar o Apache Kafka no Windows e no Linux.