O utilitário uniq no Linux é uma ferramenta poderosa para analisar arquivos de texto, identificando e manipulando linhas duplicadas ou exclusivas. Este guia explora a versatilidade e os recursos do uniq, mostrando como você pode otimizar seu uso.
Localizando Linhas de Texto Correspondentes no Linux
O comando uniq é uma ferramenta eficiente e flexível para trabalhar com linhas de texto, especialmente quando se trata de identificar dados repetidos. No entanto, é importante entender algumas peculiaridades desse comando para evitar confusões nos resultados. É fundamental ter algum conhecimento prévio antes de começar a utilizá-lo. Abordaremos essas peculiaridades ao longo deste artigo.
O uniq é ideal para quem busca realizar tarefas específicas de forma eficiente, sendo uma ferramenta valiosa para trabalhar em conjunto com outros comandos através de pipes. Um de seus colaboradores mais comuns é o comando sort, pois o uniq requer que a entrada esteja ordenada para funcionar corretamente.
Vamos começar a explorar!
Utilizando uniq Sem Opções
Para demonstrar, usaremos um arquivo de texto contendo a letra da música “Eu acredito que vou espanar minha vassoura” de Robert Johnson, disponível no YouTube. Vamos verificar como o uniq processa essa música.
Para visualizar a saída, vamos direcioná-la para o comando less:
uniq dust-my-broom.txt | lessA saída no less exibirá todo o conteúdo da música, incluindo as linhas duplicadas:
Contrariamente ao que se poderia esperar, as linhas não foram filtradas para exibir apenas as únicas ou duplicadas. Isso ocorre devido à primeira peculiaridade do uniq: quando executado sem opções, ele se comporta como se a opção -u (linhas exclusivas) fosse usada. Ou seja, ele imprime apenas as linhas únicas do arquivo. As linhas duplicadas são exibidas porque, para o uniq considerar uma linha como duplicada, ela precisa estar adjacente à sua repetição. É aí que entra o comando sort.
Ao ordenar o arquivo, as linhas duplicadas são agrupadas, e o uniq consegue tratá-las como duplicatas. Para isso, vamos ordenar o arquivo usando o sort, direcionar a saída para o uniq e, em seguida, para o less.
Executamos o seguinte comando:
sort dust-my-broom.txt | uniq | less
Uma lista ordenada das linhas é exibida em less.

A frase “Eu acredito que vou tirar o pó da minha vassoura” aparece várias vezes na música. Na verdade, ela se repete duas vezes nas primeiras quatro linhas.
Mas por que essa linha aparece em uma lista de linhas únicas? Porque, quando uma linha aparece pela primeira vez no arquivo, ela é considerada única. Somente as entradas subsequentes são consideradas duplicadas. Ou seja, o resultado mostra a primeira ocorrência de cada linha exclusiva.
Vamos usar o comando sort novamente e redirecionar a saída para um novo arquivo, eliminando a necessidade de ordenar o arquivo em comandos futuros.
O comando usado para isso é:
sort dust-my-broom.txt > sorted.txt
Agora temos um arquivo pré-ordenado para trabalharmos.
Contando Duplicados
A opção -c (contagem) exibe quantas vezes cada linha aparece em um arquivo.
O comando utilizado para isso é:
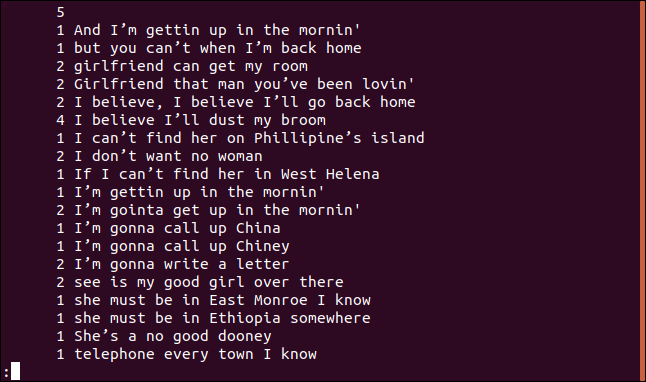
uniq -c sorted.txt | less
Cada linha começa com o número de vezes que ela aparece no arquivo. Note que a primeira linha está em branco, indicando que há cinco linhas em branco no arquivo.
Se você deseja que a saída seja classificada em ordem numérica, pode direcionar a saída do uniq para o sort. Usaremos as opções -r (reverso) e -n (classificação numérica) e direcionaremos os resultados para o less.
O comando a ser executado é:
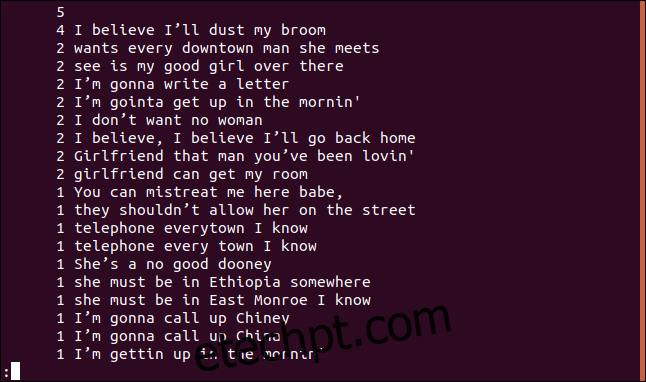
uniq -c sorted.txt | sort -rn | less
A lista será exibida em ordem decrescente, com base na frequência de cada linha.
Listando Apenas Linhas Duplicadas
Para exibir apenas as linhas que se repetem em um arquivo, a opção -d (repetido) é utilizada. Independentemente de quantas vezes uma linha seja duplicada, ela é listada apenas uma vez.
O comando para utilizar essa opção é:
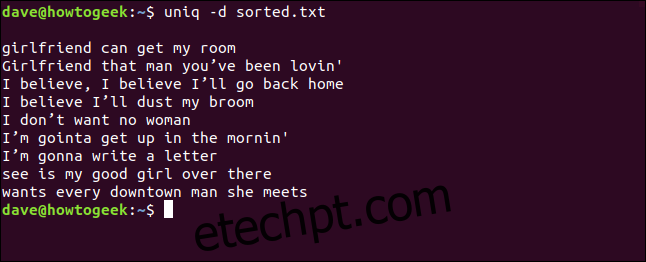
uniq -d sorted.txt
As linhas duplicadas são listadas. Observe que a linha em branco no início indica que o arquivo contém linhas em branco duplicadas e não é um espaço inserido pelo uniq.
Podemos combinar as opções -d (repetido) e -c (contagem) e direcionar a saída para o sort. Isso nos fornece uma lista ordenada de linhas que aparecem pelo menos duas vezes.
O seguinte comando é usado para esta opção:
uniq -d -c sorted.txt | sort -rn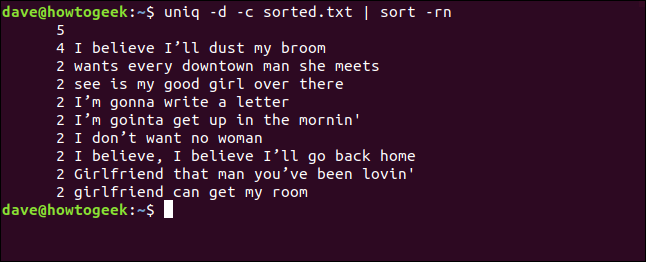
Listando Todas as Linhas Duplicadas
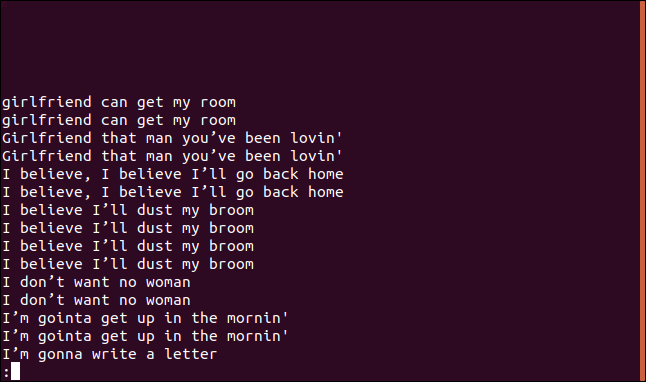
Para exibir uma lista de todas as linhas duplicadas, incluindo uma entrada para cada vez que uma linha aparece no arquivo, utilize a opção -D (todas as linhas duplicadas).
O comando para usar esta opção é:
uniq -D sorted.txt | less
A lista contém uma entrada para cada linha duplicada.
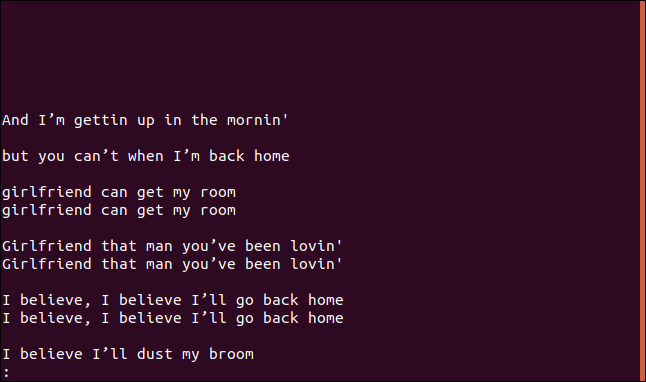
Ao usar a opção --group, é possível imprimir todas as linhas duplicadas com uma linha em branco antes (append), após (prepend) ou antes e depois (both) de cada grupo.
Usando append como modificador, o comando é:
uniq --group=append sorted.txt | less
Os grupos são separados por linhas em branco para facilitar a leitura.
Verificando um Número Específico de Caracteres
Por padrão, o uniq analisa o comprimento total de cada linha. Para restringir as verificações a um número específico de caracteres, use a opção -w (verificar caracteres).
Neste exemplo, repetiremos o último comando, mas limitaremos as comparações aos três primeiros caracteres. Para isso, executamos:
uniq -w 3 --group=append sorted.txt | less
Os resultados e agrupamentos obtidos são diferentes.
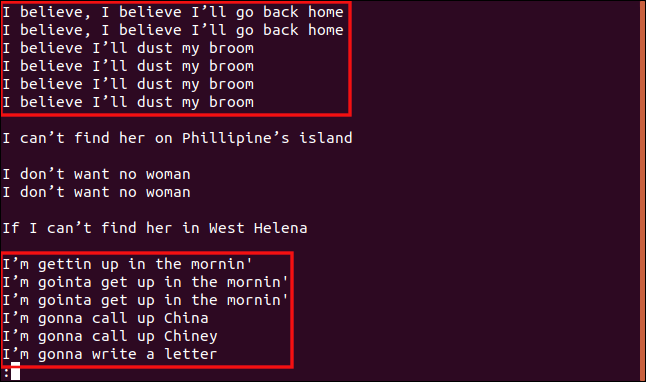
Todas as linhas que começam com “I b” são agrupadas, pois essas partes das linhas são idênticas, sendo consideradas duplicatas.
Da mesma forma, todas as linhas que começam com “I’m” são tratadas como duplicatas, mesmo que o restante do texto seja diferente.
Ignorando um Número Específico de Caracteres
Em algumas situações, é útil ignorar um número específico de caracteres no início de cada linha, por exemplo, quando as linhas de um arquivo são numeradas. Ou, imagine que você precise que o uniq ignore um timestamp e comece a verificar as linhas a partir do sexto caractere.
Abaixo está uma versão do arquivo classificado com linhas numeradas:
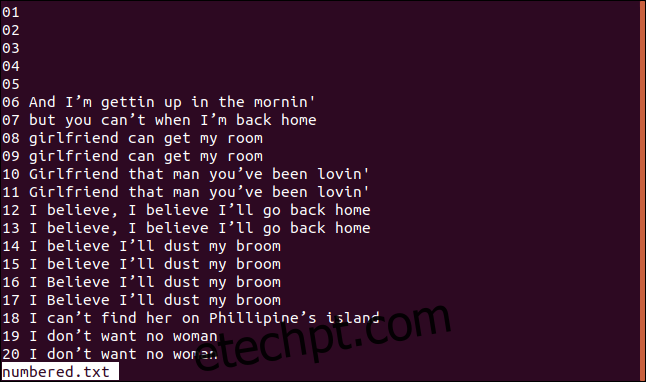
Para que o uniq comece as verificações de comparação no terceiro caractere, use a opção -s (ignorar caracteres), digitando:
uniq -s 3 -d -c numbered.txt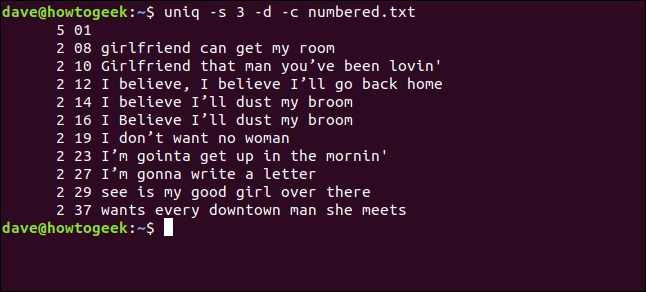
As linhas são detectadas como duplicatas e contadas corretamente. Os números das linhas exibidos são os da primeira ocorrência de cada duplicata.
É possível ignorar campos (uma série de caracteres e espaços em branco) em vez de caracteres. Use a opção -f (campos) para indicar ao uniq quais campos devem ser ignorados.
Para ignorar o primeiro campo, execute:
uniq -f 1 -d -c numbered.txt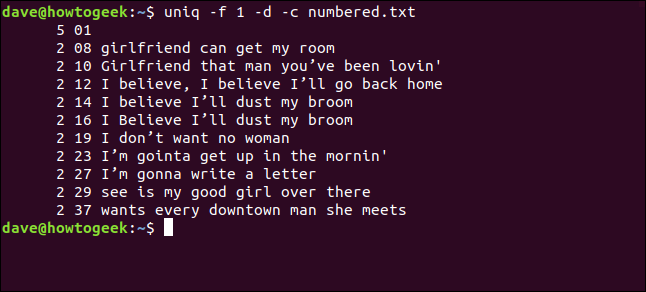
Os resultados são os mesmos de quando o uniq ignora três caracteres no início de cada linha.
Ignorando Diferenças Entre Maiúsculas e Minúsculas
Por padrão, o uniq diferencia maiúsculas de minúsculas. Se a mesma letra aparece em maiúsculas e minúsculas, o uniq considera as linhas como diferentes.
Por exemplo, veja a saída do seguinte comando:
uniq -d -c sorted.txt | sort -rn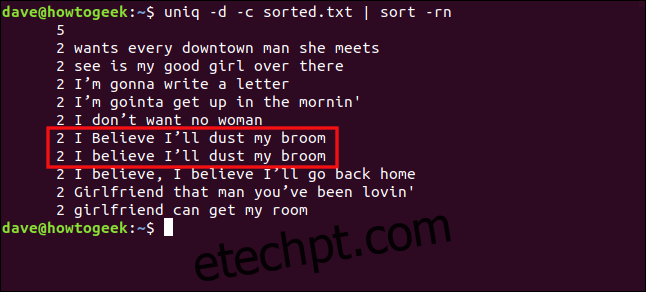
As linhas “Acredito que vou tirar o pó da minha vassoura” e “Acho que vou tirar o pó da minha vassoura” não são tratadas como duplicadas devido à diferença de maiúsculas e minúsculas no “B” em “acreditar”.
Se incluirmos a opção -i (ignorar maiúsculas e minúsculas), essas linhas serão tratadas como duplicadas. O comando é:
uniq -d -c -i sorted.txt | sort -rn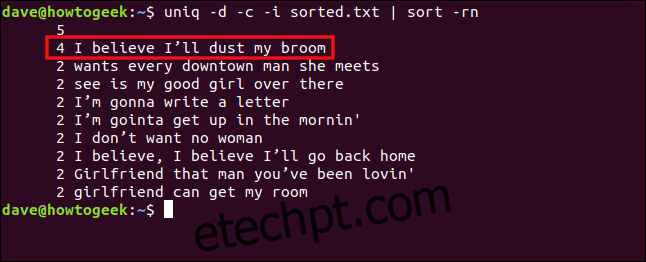
As linhas agora são tratadas como duplicadas e agrupadas.
O Linux oferece diversos utilitários especializados. Assim como muitos deles, o uniq pode não ser uma ferramenta usada diariamente.
Para se tornar proficiente em Linux, é importante lembrar qual ferramenta resolve cada problema e onde encontrá-la. A prática leva à perfeição.
Ou você pode consultar o How-To Geek, pois provavelmente temos um artigo sobre isso!