Se você precisa consolidar dados de dois arquivos de texto, utilizando um campo comum para uní-los, o comando `join` do Linux é uma ferramenta valiosa. Ele oferece uma forma dinâmica de lidar com seus arquivos de dados. Vamos explorar como você pode utilizá-lo.
Unindo Dados de Diferentes Fontes
Dados são cruciais. Empresas, negócios e até mesmo famílias dependem deles. No entanto, informações armazenadas em arquivos distintos, compiladas por pessoas diferentes, podem gerar dificuldades. Além de identificar quais arquivos contêm as informações desejadas, a formatação e o layout desses arquivos podem variar significativamente.
Também surge o desafio de gerenciar quais arquivos precisam ser atualizados, copiados, arquivados ou considerados legados. Além disso, se você precisar consolidar esses dados ou realizar análises abrangentes, surge um problema adicional: como harmonizar os dados de diferentes arquivos antes de realizar as tarefas necessárias? Como você aborda a fase de preparação desses dados?
A boa notícia é que, se os arquivos compartilham pelo menos um elemento comum, o comando `join` do Linux pode ser a solução. Ele permite combinar dados com base em campos compartilhados, facilitando a análise e o gerenciamento de informações.
Arquivos de Exemplo
Para ilustrar o uso do comando `join`, utilizaremos dois arquivos fictícios. Eles servem como demonstração prática do processo.
O primeiro arquivo, `file-1.txt`, contém informações como:
1 Adore Varian [email protected] Female 192.57.150.231 2 Nancee Merrell [email protected] Female 22.198.121.181 3 Herta Friett [email protected] Female 33.167.32.89 4 Torie Venmore [email protected] Female 251.9.204.115 5 Deni Sealeaf [email protected] Female 210.53.81.212 6 Fidel Bezley [email protected] Male 72.173.218.75 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
Cada linha inclui:
Um número, um primeiro nome, um sobrenome, um endereço de e-mail, o gênero e um endereço IP.
O segundo arquivo, `file-2.txt`, possui os seguintes dados:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
Neste arquivo, cada linha contém: Um número, um sobrenome, um endereço de e-mail, o gênero, uma região de Nova York e um valor monetário.
O comando `join` opera com “campos”, que são seções de texto delimitadas por espaços, o início ou o fim de uma linha. Para que a união seja eficaz, cada linha dos arquivos deve conter pelo menos um campo comum.
Portanto, o campo usado para unir deve aparecer em ambos os arquivos. O endereço IP está presente apenas em um arquivo, o que o torna inadequado. O mesmo se aplica ao primeiro nome. Embora o sobrenome apareça em ambos, ele pode não ser uma boa escolha, pois diferentes pessoas podem ter o mesmo sobrenome. Gênero, regiões de Nova York e valores em dólares também não são adequados, pois aparecem apenas em um dos arquivos.
O endereço de e-mail, por outro lado, é ideal, pois está presente em ambos os arquivos e é exclusivo para cada indivíduo. Além disso, uma inspeção rápida dos arquivos confirma que as linhas correspondem às mesmas pessoas, e podemos usar os números das linhas como nosso campo de correspondência inicial.
Note que os arquivos possuem um número diferente de campos, o que não é um problema. É necessário identificar qual campo usar em cada arquivo. Cuidado com campos como os nomes das regiões, pois em um arquivo delimitado por espaços, cada palavra pode ser considerada um campo separado, o que pode levar a um número inconsistente de campos em diferentes linhas. No entanto, isso não é um problema, desde que você use os campos apropriados antes dessas regiões.
Usando o Comando `join`
O campo que você usa para unir os dados deve estar classificado em ordem crescente. Nossos arquivos de exemplo já estão numerados, o que atende a esse requisito. Por padrão, o `join` usa o primeiro campo de cada arquivo e espera que os separadores sejam espaços em branco. Como nossos arquivos também atendem a isso, podemos usar o comando diretamente:
join file-1.txt file-2.txt
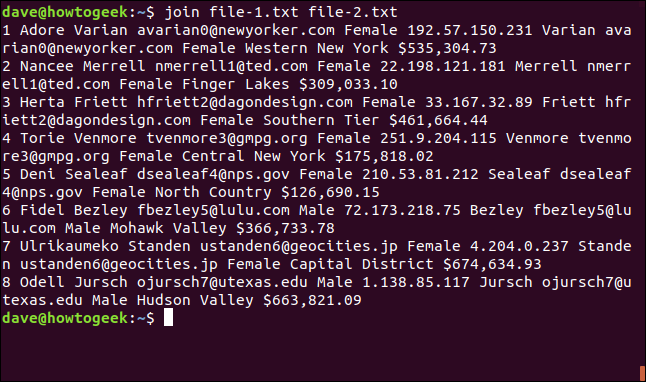
O `join` considera os arquivos “arquivo um” e “arquivo dois” com base na ordem em que eles são listados no comando.
O resultado da junção é:
1 Adore Varian [email protected] Female 192.57.150.231 Varian [email protected] Female Western New York $535,304.73 2 Nancee Merrell [email protected] Female 22.198.121.181 Merrell [email protected] Female Finger Lakes $309,033.10 3 Herta Friett [email protected] Female 33.167.32.89 Friett [email protected] Female Southern Tier $461,664.44 4 Torie Venmore [email protected] Female 251.9.204.115 Venmore [email protected] Female Central New York $175,818.02 5 Deni Sealeaf [email protected] Female 210.53.81.212 Sealeaf [email protected] Female North Country $126,690.15 6 Fidel Bezley [email protected] Male 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 Standen [email protected] Female Capital District $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
A saída é formatada da seguinte maneira: o campo de correspondência é impresso primeiro, seguido pelos campos restantes do primeiro arquivo e, por fim, os campos do segundo arquivo, excluindo o campo de correspondência.
Arquivos Fora de Ordem
Agora, vamos tentar algo que sabemos que não funcionará. Vamos desordenar as linhas de um dos arquivos para ver como o `join` se comporta. O arquivo `file-3.txt` é idêntico ao `file-2.txt`, exceto que a linha oito está entre as linhas cinco e seis:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Vamos tentar unir `file-3.txt` com `file-1.txt`:
join file-1.txt file-3.txt
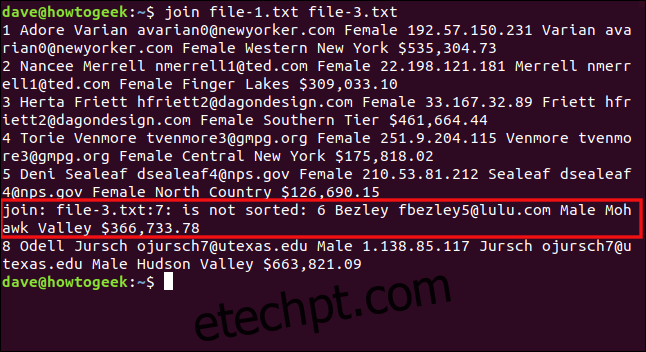
O `join` reporta que a sétima linha de `file-3.txt` está fora de ordem e, portanto, não pode ser processada. Esta é a linha que começa com o número seis, que deveria vir antes do oito em uma lista ordenada. A sexta linha do arquivo (começando com “8 Odell”) foi a última a ser processada, e vemos a saída correspondente.
Você pode usar a opção `–check-order` para verificar se o `join` está satisfeito com a ordem dos arquivos. Ele não tentará realizar a junção, apenas verificará a ordem.
join --check-order file-1.txt file-3.txt
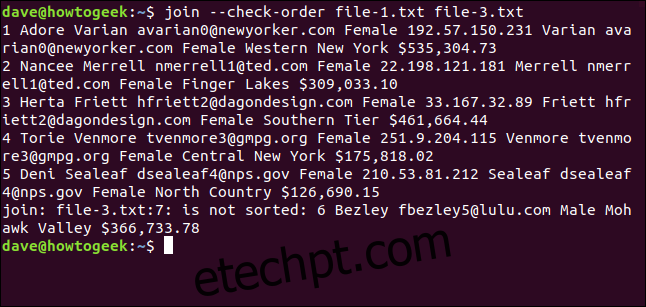
O `join` avisa que há um problema com a linha sete do arquivo `file-3.txt` antes de iniciar qualquer processo.
Arquivos com Linhas Ausentes
No arquivo `file-4.txt`, a última linha foi removida, portanto, não há linha oito. O conteúdo é:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Executamos o comando `join` e, surpreendentemente, ele não reporta nenhum problema e processa todas as linhas que consegue:
join file-1.txt file-4.txt
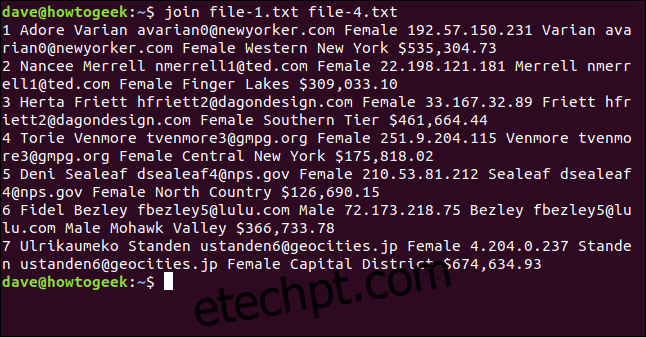
A saída mostra sete linhas unidas. A opção `-a` (imprime não correspondidas) faz com que o `join` imprima também as linhas que não foram correspondidas.
O comando a seguir instrui o `join` a imprimir as linhas do arquivo um que não puderam ser correspondidas com as linhas do arquivo dois:
join -a 1 file-1.txt file-4.txt
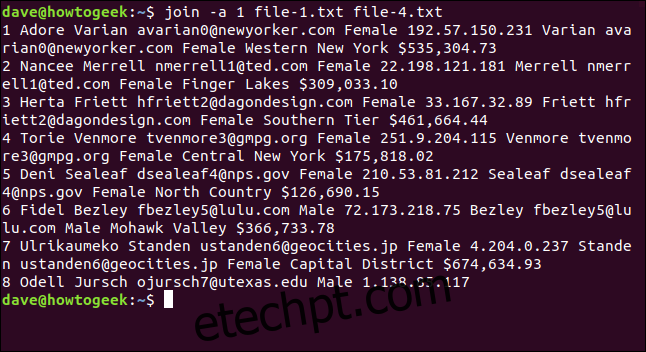
Sete linhas são correspondidas, e a linha oito do arquivo um é impressa sem correspondência. Como `file-4.txt` não tinha uma linha oito, não há nenhuma informação combinada, mas pelo menos sabemos que não houve correspondência no `file-4.txt`.
O comando `-v` (suprimir linhas unidas) revela as linhas que não foram correspondidas:
join -v file-1.txt file-4.txt

A saída mostra que a linha oito é a única sem correspondência no arquivo dois.
Usando Campos de Junção Diferentes
Agora vamos unir dois novos arquivos utilizando um campo diferente do primeiro campo. O arquivo `file-7.txt` contém:
[email protected] Female 192.57.150.231 [email protected] Female 210.53.81.212 [email protected] Male 72.173.218.75 [email protected] Female 33.167.32.89 [email protected] Female 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Female 251.9.204.115 [email protected] Female 4.204.0.237
E o arquivo `file-8.txt` possui o seguinte conteúdo:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
O campo mais adequado para unir é o endereço de e-mail, que é o primeiro campo no primeiro arquivo e o segundo campo no segundo. As opções `-1` (campo do primeiro arquivo) e `-2` (campo do segundo arquivo) nos permitem especificar qual campo usar. O número que segue cada opção indica o campo desejado para a junção.
O comando a seguir instrui o `join` a usar o primeiro campo do arquivo um e o segundo do arquivo dois:
join -1 1 -2 2 file-7.txt file-8.txt
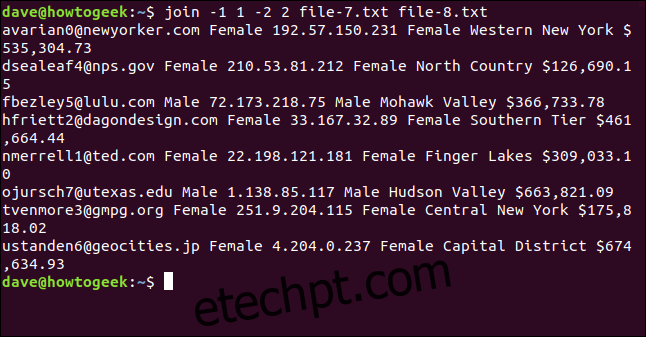
Os arquivos são unidos usando o endereço de e-mail, que aparece como o primeiro campo de cada linha na saída.
Usando Separadores de Campo Personalizados
E se os seus arquivos usarem um delimitador diferente de espaços em branco?
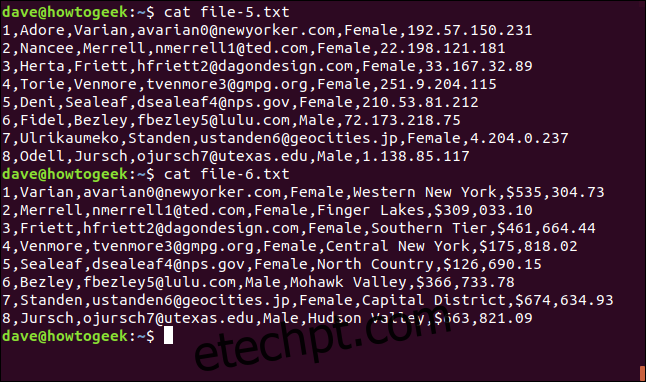
Os dois arquivos a seguir são delimitados por vírgulas, com o único espaço em branco estando entre os nomes de locais com várias palavras:
cat file-5.txt
cat file-6.txt
Podemos usar a opção `-t` (caractere separador) para indicar ao `join` qual caractere usar como separador de campo. Nesse caso, é a vírgula:
join -t, file-5.txt file-6.txt
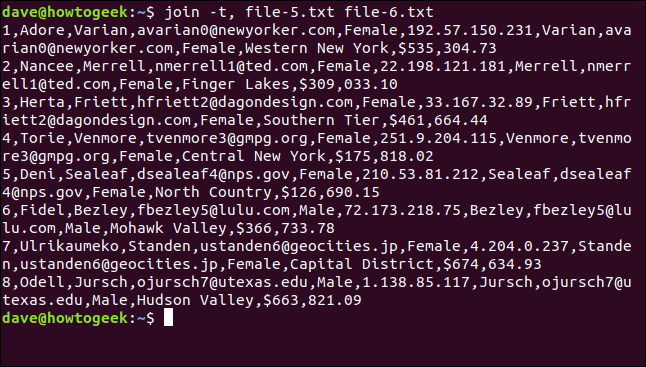
Todas as linhas são combinadas, e os espaços nos nomes dos lugares são preservados.
Ignorando Diferenças de Maiúsculas e Minúsculas
O arquivo `file-9.txt` é quase idêntico ao `file-8.txt`. A única diferença é que alguns dos endereços de e-mail têm letras maiúsculas, conforme mostrado:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female u[email protected] Capital District $674,634.93
Quando juntamos `file-7.txt` e `file-8.txt`, tudo funcionou corretamente. Vamos ver o que acontece com `file-7.txt` e `file-9.txt`:
join -1 1 -2 2 file-7.txt file-9.txt
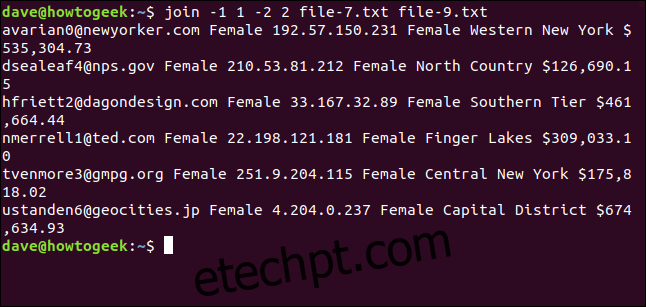
Apenas seis linhas foram encontradas. As diferenças de maiúsculas e minúsculas impediram que dois endereços de e-mail fossem unidos.
No entanto, podemos usar a opção `-i` (ignorar maiúsculas e minúsculas) para forçar o `join` a ignorar essas diferenças e corresponder aos campos que contêm o mesmo texto, independentemente das letras.
join -1 1 -2 2 -i file-7.txt file-9.txt
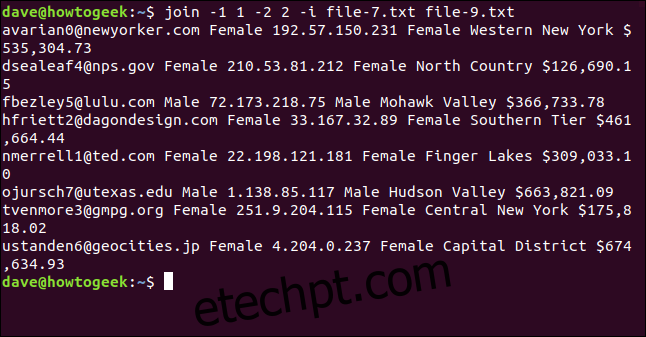
Todas as oito linhas são combinadas e unidas com sucesso.
Combinando e Conquistando
O comando `join` é um aliado poderoso na preparação de dados. Seja para analisar dados, modificá-los ou importá-los para um novo sistema, o `join` pode ser uma solução valiosa. Independentemente do cenário, você vai agradecer por ter conhecido essa funcionalidade!