O comando Linux `curl` oferece uma vasta gama de funcionalidades que vão muito além do simples download de arquivos. Vamos explorar as capacidades do `curl` e entender quando ele se torna a ferramenta ideal em comparação com o `wget`.
`curl` vs. `wget`: Quais são as diferenças?
É comum haver confusão sobre as vantagens de cada comando, `wget` e `curl`. Embora haja uma sobreposição em suas funcionalidades – ambos podem buscar arquivos de servidores remotos – as semelhanças terminam aí.
O `wget` é uma ferramenta poderosa para realizar downloads de conteúdo e arquivos. Ele pode baixar desde arquivos isolados e páginas web até diretórios inteiros. Sua capacidade de percorrer links em páginas web e baixar conteúdo de forma recursiva faz dele um gestor de downloads de linha de comando imbatível.
O `curl`, por sua vez, atende a uma necessidade distinta. Embora também possa obter arquivos, ele não possui a habilidade de navegar recursivamente em um site em busca de conteúdo. Sua verdadeira força está na interação com sistemas remotos, enviando requisições e recebendo respostas. Essas respostas podem ser arquivos, conteúdo de páginas web, ou até mesmo dados de serviços web e APIs.
Além disso, o `curl` não se limita apenas a sites. Ele suporta mais de 20 protocolos, incluindo HTTP, HTTPS, SCP, SFTP e FTP. Sua capacidade de lidar com canais do Linux o torna facilmente integrável com outros comandos e scripts.
O criador do `curl` oferece uma página web onde detalha as diferenças entre `curl` e `wget`, do seu ponto de vista.
Instalação do `curl`
Em alguns sistemas, como Fedora 31 e Manjaro 18.1.0, o `curl` já vem instalado. No entanto, no Ubuntu 18.04 LTS, por exemplo, ele precisa ser instalado manualmente. Use o seguinte comando para instalá-lo no Ubuntu:
sudo apt-get install curl
Verificando a versão do `curl`
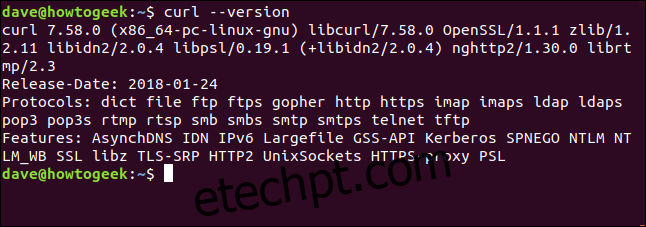
O comando `–version` exibe a versão do `curl`, juntamente com todos os protocolos que ele suporta.
curl --version
Obtendo uma página web
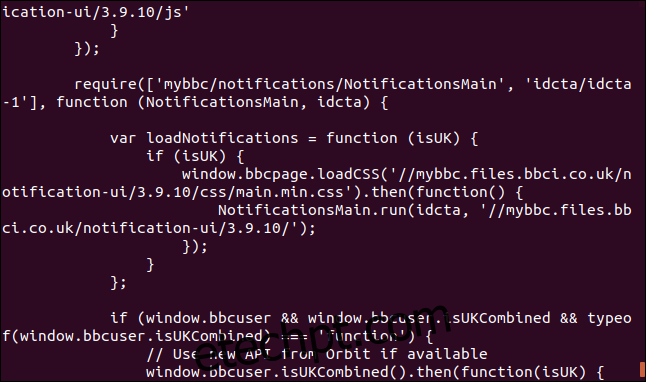
Ao direcionar o `curl` para uma página web, ele a recupera.
curl https://www.bbc.com

No entanto, por padrão, o `curl` exibe o código-fonte da página diretamente na janela do terminal.
É importante ter cuidado: se não especificarmos que desejamos salvar o conteúdo em um arquivo, o `curl` sempre o exibirá no terminal. Se o arquivo recuperado for binário, o resultado pode ser imprevisível, com o shell interpretando alguns bytes como caracteres de controle ou sequências de escape.
Salvando dados em um arquivo
Podemos direcionar o `curl` para salvar a saída em um arquivo, usando o operador `>`:
curl https://www.bbc.com > bbc.html

Desta vez, as informações recuperadas não são exibidas no terminal, mas diretamente salvas no arquivo. Como não há saída no terminal, o `curl` mostra informações de progresso.
Isso não ocorreu no exemplo anterior porque as informações de progresso se misturariam com o código-fonte da página web, então o `curl` as suprimiu automaticamente.
Neste caso, o `curl` detecta que a saída está sendo redirecionada para um arquivo e mostra as informações de progresso.
As informações exibidas incluem:
% Total: O tamanho total a ser baixado.
% Recebido: A porcentagem e o tamanho real dos dados já baixados.
% Xferd: A porcentagem e o tamanho real dos dados enviados, em caso de upload.
Average Speed Dload: A velocidade média de download.
Velocidade média de upload: A velocidade média de upload.
Tempo total: O tempo estimado total para a transferência.
Tempo gasto: O tempo já decorrido na transferência.
Tempo restante: O tempo estimado restante para concluir a transferência.
Velocidade atual: A velocidade de transferência atual.
Agora, temos um arquivo chamado “bbc.html”, com o conteúdo da página web.

Ao clicar duas vezes neste arquivo, o navegador padrão o abrirá e exibirá a página web.
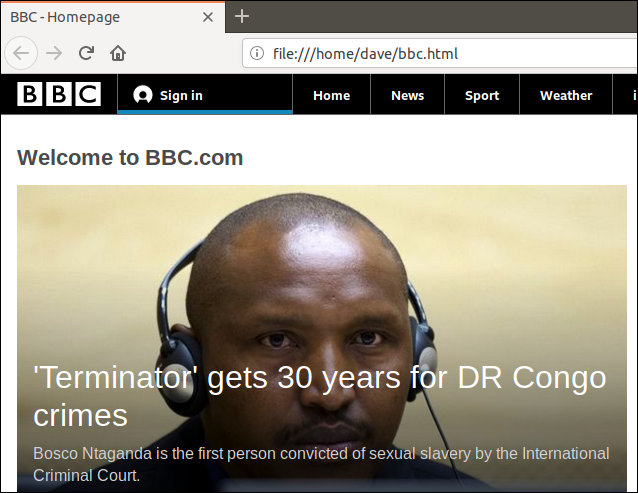
Note que o endereço na barra de endereço do navegador aponta para um arquivo local, e não para um site remoto.
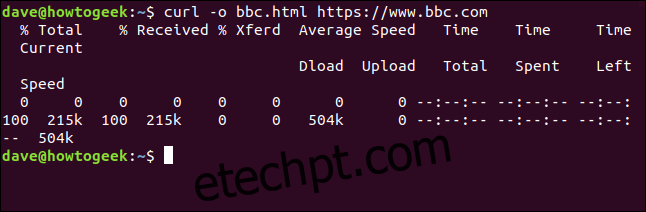
Não é preciso usar o redirecionamento para criar um arquivo. Podemos usar a opção `-o` (saída) e especificar o nome do arquivo que desejamos criar.
curl -o bbc.html https://www.bbc.com
Usando uma barra de progresso
Para substituir as informações de download baseadas em texto por uma barra de progresso, use a opção `–#` (barra de progresso).
curl -# -o bbc.html https://www.bbc.com

Retomando um download interrompido
É fácil retomar um download que foi interrompido. Vamos começar baixando um arquivo maior, como a versão mais recente do Ubuntu 18.04. Usaremos a opção `–output` para especificar o nome do arquivo: “ubuntu180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

O download começa e prossegue até a conclusão.
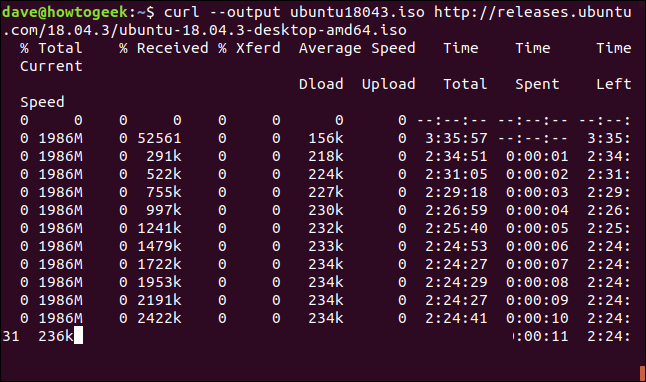
Se interrompermos o download com `Ctrl + C`, o download será cancelado.
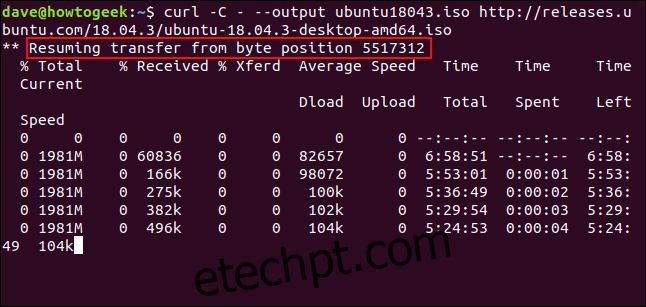
Para retomar o download, usamos a opção `-C` (continuar). Isso faz com que o `curl` reinicie o download no ponto especificado ou no deslocamento dentro do arquivo de destino. Se usarmos um hífen `-` como deslocamento, o `curl` verificará a parte já baixada e determinará o deslocamento correto.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

O download é retomado e o `curl` exibe o deslocamento em que está reiniciando.
Obtendo cabeçalhos HTTP
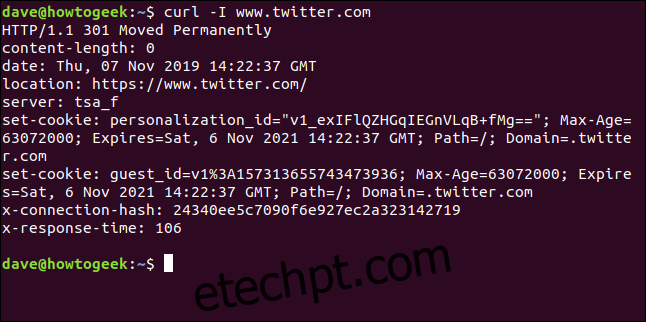
Com a opção `-I` (head), podemos obter apenas os cabeçalhos HTTP. Isso equivale a enviar o comando HTTP HEAD para um servidor web.
curl -I www.twitter.com

Este comando recupera apenas os cabeçalhos; ele não baixa nenhuma página web ou arquivo.
Baixando vários URLs
Usando o `xargs`, podemos baixar vários URLs de uma vez. Imagine que queremos baixar várias páginas web que fazem parte de um único artigo ou tutorial.
Copie os URLs para um editor e salve-os em um arquivo chamado “urls-to-download.txt”. Podemos usar o `xargs` para tratar cada linha do arquivo de texto como um parâmetro a ser passado para o `curl`.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Este é o comando que precisamos para que o `xargs` passe os URLs para o `curl`, um de cada vez:
xargs -n 1 curl -O < urls-to-download.txt
Este comando usa a opção `-O` (arquivo remoto), que faz com que o `curl` salve o arquivo baixado com o mesmo nome que ele possui no servidor remoto.
A opção `-n 1` diz ao `xargs` para tratar cada linha do arquivo de texto como um parâmetro único.
Ao executar o comando, veremos vários downloads começando e terminando, um após o outro.
Ao verificar no navegador de arquivos, vemos que os arquivos foram baixados, cada um com o nome que tinha no servidor remoto.
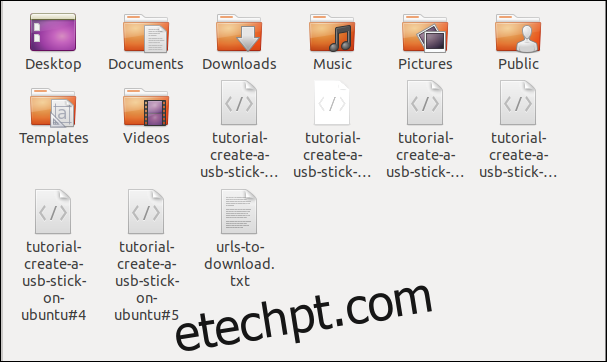
Baixando arquivos de um servidor FTP
Usar o `curl` com um servidor File Transfer Protocol (FTP) é fácil, mesmo que você precise se autenticar com nome de usuário e senha. Para isso, use a opção `-u` (user) e digite o nome de usuário, dois pontos “:” e a senha. Não deixe espaço antes ou depois dos dois pontos.
Este é um servidor FTP de teste hospedado pela Rebex. Ele possui um nome de usuário “demo” e senha “password”. Não use senhas e nomes de usuário fracos em servidores FTP “reais”.
curl -u demo:password ftp://test.rebex.net

O `curl` detecta que estamos apontando para um servidor FTP e retorna uma lista dos arquivos presentes no servidor.

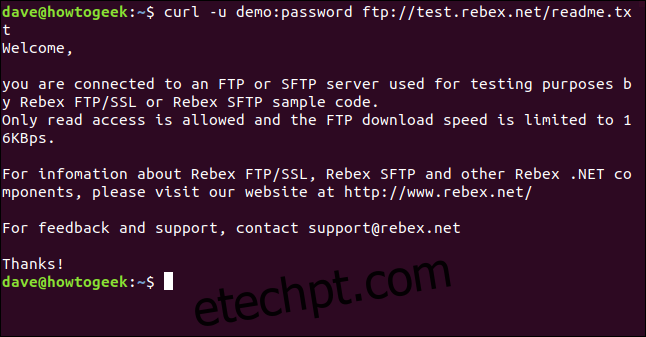
O único arquivo neste servidor é o “readme.txt”, com 403 bytes. Vamos baixá-lo. Use o mesmo comando, adicionando o nome do arquivo:
curl -u demo:password ftp://test.rebex.net/readme.txt

O arquivo é recuperado e o `curl` exibe seu conteúdo no terminal.
Na maioria dos casos, é mais conveniente salvar o arquivo no disco do que exibi-lo no terminal. Usamos o comando de saída `-O` (arquivo remoto) para que o arquivo seja salvo com o mesmo nome do servidor remoto.
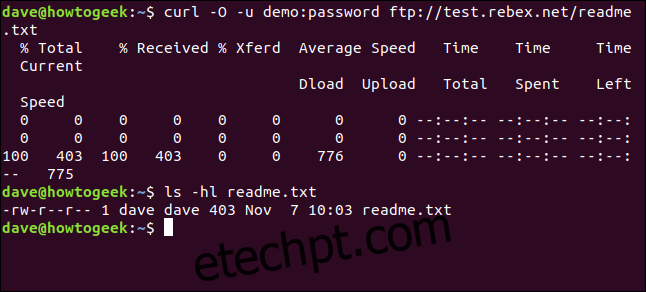
curl -O -u demo:password ftp://test.rebex.net/readme.txt

O arquivo é recuperado e salvo no disco. Podemos usar `ls` para verificar os detalhes do arquivo. Ele tem o mesmo nome e tamanho (403 bytes) do arquivo no servidor FTP.
ls -hl readme.txt
Enviando parâmetros para servidores remotos
Alguns servidores remotos aceitam parâmetros em suas requisições. Os parâmetros podem formatar os dados retornados ou selecionar os dados que o usuário deseja obter. É comum usar o `curl` para interagir com interfaces de programação de aplicações (APIs).
Um exemplo simples é o site ipify, que oferece uma API para verificar seu endereço IP externo.
curl https://api.ipify.org
Ao adicionar o parâmetro `format` com o valor “json”, podemos requisitar novamente nosso endereço IP, mas os dados serão retornados em formato JSON.
curl https://api.ipify.org?format=json

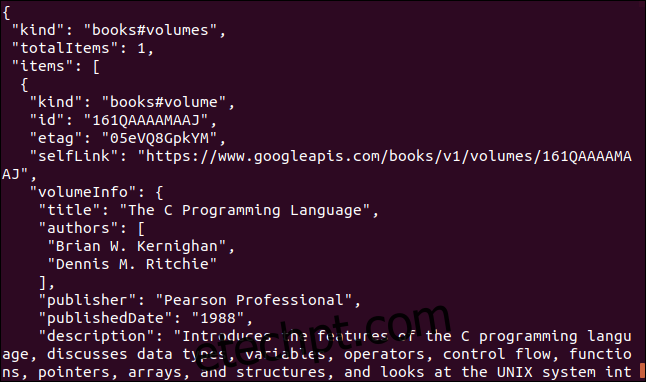
Outro exemplo é uma API do Google que retorna um objeto JSON descrevendo um livro. O parâmetro é o International Standard Book Number (ISBN) de um livro. Geralmente, ele está na contracapa, abaixo de um código de barras. Usaremos o parâmetro “0131103628”.
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Os dados retornados são extensos:
`curl` ou `wget`?
Se eu quisesse baixar conteúdo de um site e navegar recursivamente em toda sua estrutura, o `wget` seria minha escolha.
Se eu precisasse interagir com um servidor remoto ou API, e possivelmente baixar arquivos ou páginas web, usaria o `curl`. Principalmente se o protocolo desejado não fosse suportado pelo `wget`.