A Migração de Bancos de Dados Corporativos para a Nuvem: Desafios e Soluções
Observando a evolução do desenvolvimento de software corporativo ao longo de duas décadas, uma tendência se destaca: a migração de bancos de dados para a nuvem. Essa movimentação, embora promissora, apresenta desafios que vão além da simples documentação oferecida pelos provedores de serviços como a Amazon Web Services (AWS).
Minha experiência em projetos de migração de bancos de dados on-premise para a nuvem AWS revelou que a execução desse plano nem sempre é trivial e pode, em certas situações, falhar. Este artigo aborda um caso específico, baseado em experiências reais, que envolve:
- Origem: Apesar da teoria indicar que a fonte do banco de dados não é crucial (uma abordagem similar se aplica a diversos bancos de dados populares), o Oracle, devido a sua predominância em grandes empresas, será o foco principal.
- Destino: Não há restrições quanto ao banco de dados de destino na AWS. A metodologia apresentada é adaptável a qualquer opção.
- Modo: A migração pode ser completa ou incremental, com carregamento em lote (dados de origem e destino defasados) ou quase em tempo real. Ambos os cenários serão explorados.
- Frequência: A migração pode ser única, seguida de uma transição completa para a nuvem, ou envolver um período de transição com atualização simultânea de dados em ambos os ambientes, o que implica no desenvolvimento de uma sincronização diária entre o local e a AWS. Abordaremos ambas as situações.
Análise do Desafio
O objetivo inicial é, geralmente, simples: iniciar o desenvolvimento de serviços na AWS, o que requer a cópia de todos os dados para um banco de dados específico. A ideia é utilizar esses dados imediatamente e definir as alterações necessárias nos projetos de banco de dados posteriormente.
No entanto, é crucial considerar:
- Evite a armadilha de replicar o ambiente local na nuvem sem uma análise criteriosa. Embora seja o caminho mais rápido, essa abordagem pode gerar problemas arquitetônicos de difícil correção, exigindo uma refatoração significativa da nova plataforma. O ecossistema da nuvem é diferente do local e a forma como os dados serão consumidos pode mudar.
- Questionar os requisitos com perguntas como:
- Quem são os usuários da nova plataforma? São usuários transacionais, cientistas de dados, analistas ou serviços?
- Os processos atuais do dia a dia serão mantidos na nuvem? Se não, quais serão as mudanças?
- Há previsão de crescimento substancial dos dados? O modelo de dados deve estar preparado para isso.
- É fundamental ter uma ideia das consultas que o novo banco de dados receberá dos usuários. Isso influenciará as alterações necessárias no modelo de dados para garantir um desempenho adequado.
Preparação para a Migração
Após a definição do banco de dados de destino e a discussão do modelo de dados, a próxima etapa é utilizar o AWS Schema Conversion Tool (SCT). Essa ferramenta auxilia em diversas fases:
- Análise e extração do modelo de dados da origem, gerando um modelo inicial baseado na estrutura do banco de dados local.
- Sugestão de uma estrutura para o modelo de dados de destino, considerando as especificidades do banco de dados escolhido na AWS.
- Geração de scripts de implementação do banco de dados de destino para instalar o modelo de dados. Após a execução desses scripts, o banco de dados na nuvem estará pronto para receber os dados do banco de dados local.
Referência: Documentação da AWS
É importante ressaltar que a saída do SCT deve ser usada como referência para ajustes, levando em consideração o uso dos dados na nuvem. Os índices de banco de dados, por exemplo, podem ser otimizados para o novo contexto analítico, e a partição de dados pode ser ajustada para o ambiente de destino.
Ainda, considere realizar transformações de dados durante a migração, ajustando o modelo de dados de destino para que não seja uma cópia 1:1 do original. Se os bancos de dados de origem e destino forem do mesmo tipo, é recomendável usar ferramentas de migração nativas do banco de dados (como Data Pump do Oracle ou o GoldenGate). Caso contrário, o AWS Database Migration Service (DMS) será a ferramenta mais adequada.
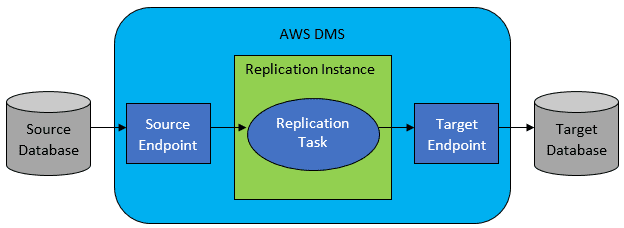
Referência: Documentação da AWS
O AWS DMS permite configurar tarefas no nível da tabela, definindo:
- O banco de dados e a tabela de origem.
- As instruções para obter os dados.
- As transformações de dados.
- O banco de dados e a tabela de destino.
A configuração das tarefas do DMS é feita em formato JSON. Em um cenário simplificado, basta executar os scripts no banco de dados de destino e iniciar a tarefa do DMS.
Migração Completa de Dados (Única)

O cenário mais simples é a migração única de todo o banco de dados. Os passos incluem:
- Definir uma tarefa DMS para cada tabela de origem.
- Configurar os trabalhos DMS com paralelismo, variáveis de cache e dimensionamento adequados. Essa etapa requer testes e otimizações.
- Garantir que todas as tabelas de destino sejam criadas (vazias) na estrutura correta no banco de dados de destino.
- Agendar uma janela de tempo para a migração, certificando-se de que o tempo é suficiente para a conclusão e que não haverá alterações no banco de dados de origem durante a migração.
Com a configuração correta do DMS, cada tabela de origem será copiada para o banco de dados de destino na AWS. A maior preocupação é garantir o desempenho e o dimensionamento correto para evitar falhas.
Sincronização Diária Incremental

A sincronização diária incremental é mais complexa. O DMS opera em dois modos:
- Carga Total: As tarefas do DMS são executadas e finalizadas.
- Captura de Dados de Alteração (CDC): A tarefa do DMS é contínua, monitorando o banco de dados de origem por alterações e replicando-as no banco de dados de destino.
Ao optar pelo CDC, é necessário definir como as alterações serão extraídas do banco de dados de origem.
#1. Leitor de Redo Logs do Oracle
O leitor de redo logs do Oracle é uma opção para obter as alterações e replicá-las no banco de dados de destino. No entanto, ele afeta o cluster Oracle de origem, o que pode aumentar os custos da solução.
#2. Minerador de Logs do AWS DMS
Nessa opção, o DMS copia os redo logs do Oracle para o cluster DMS, sem afetar o banco de dados de origem. Embora economize recursos do Oracle, essa solução é mais lenta. Em alguns casos, pode ser necessário ajustar o paralelismo e o desempenho para atingir um atraso aceitável entre os dados de origem e de destino.
É fundamental observar que nem todas as alterações nas tabelas de origem são suportadas pelo CDC. Em alguns casos, pode ser necessário fazer alterações manualmente na tabela de destino e reiniciar a tarefa do CDC.
Quando as Coisas Dão Errado

Existe um cenário específico em que a replicação diária se torna um desafio. O DMS processa os redo logs em uma velocidade definida, independentemente do número de instâncias ou da escolha do leitor de redo logs. Se o banco de dados de origem gerar uma grande quantidade de alterações diariamente (com redo logs de 500 GB ou mais), o CDC pode não funcionar, deixando dados não processados para o dia seguinte.
Nesse caso, o CDC não era viável. A solução foi:
- Separar tabelas grandes e pouco utilizadas para replicação semanal.
- Dividir tabelas grandes entre várias tarefas do DMS, garantindo uma divisão distinta dos dados entre as tarefas.
- Adicionar mais instâncias do DMS e distribuir as tarefas de forma uniforme.
Basicamente, foi utilizado o modo de carga total do DMS para replicar os dados diariamente, já que essa era a única forma de garantir a conclusão da replicação no mesmo dia. Essa solução, embora não seja ideal, tem se mostrado eficaz ao longo do tempo.