Com o aumento exponencial na geração de dados pelas empresas, as abordagens tradicionais de armazenamento de dados estão se tornando cada vez mais complexas e dispendiosas. O Data Vault, uma metodologia inovadora em data warehousing, surge como uma solução promissora, oferecendo um caminho escalável, flexível e economicamente viável para a gestão de grandes volumes de dados.
Neste artigo, vamos explorar como o Data Vault está moldando o futuro do armazenamento de dados e porque um número crescente de organizações está a adotar esta metodologia. Além disso, forneceremos recursos de aprendizagem para aqueles que desejam aprofundar-se neste tema.
O que é um Data Vault?
Data Vault é uma técnica de modelagem de data warehouse particularmente eficaz para ambientes de data warehousing ágeis. Oferece alta adaptabilidade para expansões, histórico completo e unificado dos dados e permite uma forte paralelização nos processos de carregamento de dados. A modelagem Data Vault foi desenvolvida por Dan Linstedt na década de 1990.
Após a sua primeira publicação em 2000, ganhou maior atenção em 2002 através de uma série de artigos. Em 2007, Linstedt obteve o apoio de Bill Inmon, que o descreveu como a “escolha ideal” para sua arquitetura Data Vault 2.0.
Qualquer profissional que trabalhe com data warehouses ágeis rapidamente se deparará com o Data Vault. O diferencial desta tecnologia reside na sua capacidade de se adequar às necessidades das empresas, permitindo ajustes flexíveis e simples num data warehouse.
O Data Vault 2.0 considera todo o processo de desenvolvimento e arquitetura, abrangendo o método de componentes (implementação), arquitetura e modelo. A vantagem é que esta abordagem engloba todos os aspectos da inteligência de negócios com o data warehouse subjacente durante o desenvolvimento.
O modelo Data Vault oferece uma solução moderna para superar as limitações dos métodos tradicionais de modelagem de dados. Com a sua escalabilidade, flexibilidade e agilidade, fornece uma base sólida para a construção de uma plataforma de dados capaz de acomodar a complexidade e a diversidade dos ambientes de dados atuais.
A arquitetura hub-and-spoke do Data Vault e a separação de entidades e atributos facilitam a integração e harmonização de dados provenientes de diversos sistemas e domínios, impulsionando um desenvolvimento incremental e ágil.
Uma função crucial do Data Vault na construção de uma plataforma de dados é o estabelecimento de uma única fonte de verdade para todos os dados. Sua visão unificada de dados e a capacidade de capturar e rastrear alterações de dados históricos por meio de tabelas satélite viabilizam a conformidade, auditoria, cumprimento de requisitos regulamentares e análises e relatórios abrangentes.
Os recursos de integração de dados quase em tempo real do Data Vault, através do carregamento delta, facilitam o manuseio de grandes volumes de dados em ambientes dinâmicos, como aplicações de Big Data e IoT.
Data Vault vs. Modelos Tradicionais de Data Warehouse
A Terceira Forma Normal (3FN) é um dos modelos tradicionais de data warehouse mais reconhecidos e frequentemente utilizado em grandes projetos. Este modelo está alinhado com as ideias de Bill Inmon, um dos pioneiros do conceito de data warehouse.
A arquitetura Inmon é baseada no modelo de banco de dados relacional e elimina a redundância de dados ao dividir as fontes de dados em tabelas menores, armazenadas em data marts e interconectadas por meio de chaves primárias e estrangeiras. Garante a consistência e precisão dos dados ao impor regras de integridade referencial.
O objetivo da forma normal era construir um modelo de dados abrangente para toda a empresa para o data warehouse central. No entanto, apresenta problemas de escalabilidade e flexibilidade devido a data marts altamente acoplados, dificuldades de carregamento quase em tempo real, processos trabalhosos e um design e implementação de cima para baixo.
O modelo Kimball, utilizado para OLAP (processamento analítico online) e data marts, é outro modelo de data warehouse popular, em que as tabelas de fatos contêm dados agregados e as tabelas de dimensões descrevem os dados armazenados num esquema em estrela ou em floco de neve. Nesta arquitetura, os dados são organizados em tabelas de fatos e dimensões que são desnormalizadas para facilitar a consulta e análise.
O modelo Kimball é baseado num modelo dimensional otimizado para consultas e relatórios, sendo ideal para aplicações de inteligência de negócios. No entanto, apresenta desafios como o isolamento de informações orientadas por assunto, redundância de dados, estruturas de consulta incompatíveis, dificuldades de escalabilidade, granularidade inconsistente de tabelas de fatos, problemas de sincronização e a necessidade de um design de cima para baixo com implementação de baixo para cima.
Em contraste, a arquitetura Data Vault é uma abordagem híbrida que combina elementos das arquiteturas 3FN e Kimball. É um modelo baseado em princípios relacionais, normalização de dados e princípios matemáticos de redundância, representando os relacionamentos entre entidades de maneira diferenciada e estruturando os campos de tabela e os timestamps de forma distinta.
Nesta arquitetura, todos os dados são armazenados num Data Vault bruto ou data lake, enquanto os dados de uso comum são armazenados num formato normalizado num Data Vault de negócios, que contém dados históricos e específicos do contexto, que podem ser utilizados para a geração de relatórios.
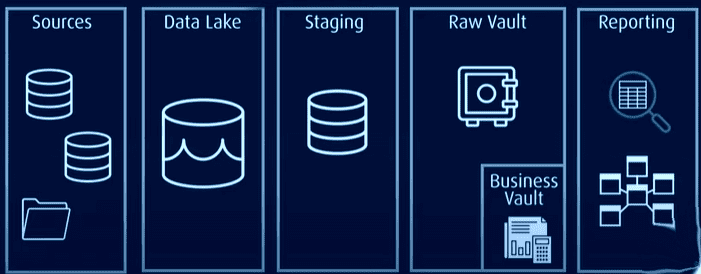
O Data Vault aborda os problemas dos modelos tradicionais por ser mais eficiente, escalável e flexível. Permite carregamento quase em tempo real, maior integridade de dados e fácil expansão sem afetar as estruturas existentes. O modelo também pode ser expandido sem a necessidade de migrar as tabelas existentes.
| Abordagem de modelagem | Estrutura de dados | Abordagem de design |
| Modelagem 3FN | Tabelas em 3FN | Bottom-up |
| Modelagem Kimball | Star Schema ou Snowflake Schema | Top-down |
| Data Vault | Hub-and-Spoke | Bottom-up |
Arquitetura do Data Vault
O Data Vault apresenta uma arquitetura hub-and-spoke e consiste essencialmente em três camadas:
Camada de preparação: Recolhe os dados brutos dos sistemas de origem, como CRM ou ERP.
Camada de Data Warehouse: Quando modelada como um modelo Data Vault, esta camada inclui:
- Data Vault bruto: Armazena os dados brutos.
- Business Data Vault: Inclui dados harmonizados e transformados com base nas regras de negócio (opcional).
- Metrics Vault: Armazena informações de tempo de execução (opcional).
- Operational Vault: Armazena os dados que fluem diretamente dos sistemas operacionais para o data warehouse (opcional).
Camada Data Mart: Esta camada modela os dados como esquema em estrela e/ou outras técnicas de modelagem. Fornece informações para análise e relatórios.
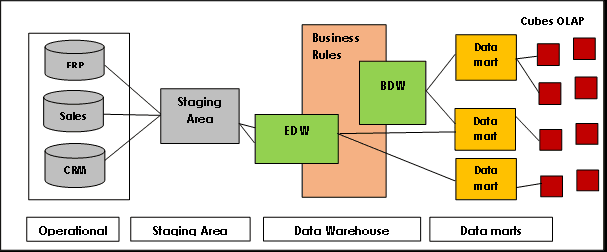 Fonte da imagem: Lamia Yessad
Fonte da imagem: Lamia Yessad
O Data Vault não requer uma arquitetura totalmente nova. Novas funcionalidades podem ser desenvolvidas em paralelo utilizando os conceitos e métodos do Data Vault, sem comprometer os componentes existentes. Os frameworks podem facilitar significativamente o trabalho, criando uma camada entre o data warehouse e o desenvolvedor, reduzindo a complexidade da implementação.
Componentes do Data Vault
Durante a modelagem, o Data Vault divide todas as informações relativas a um objeto em três categorias, em contraste com a modelagem clássica da terceira forma normal. Estas informações são armazenadas de forma rigorosamente separada. As áreas funcionais podem ser mapeadas no Data Vault através dos chamados hubs, links e satélites:
#1. hubs
Os hubs representam o núcleo dos conceitos de negócio, como cliente, vendedor, venda ou produto. A tabela de hub é formada em torno da chave de negócio (nome ou localização da loja), quando uma nova instância desta chave é introduzida pela primeira vez no data warehouse.
O hub não contém informações descritivas nem chaves estrangeiras. Consiste apenas na chave de negócio, com uma sequência de IDs ou hash gerada pelo warehouse, um timestamp de carregamento e a fonte de registro.
#2. links
Os links estabelecem relacionamentos entre as chaves de negócio. Cada entrada num link modela relacionamentos n:m entre qualquer número de hubs. Permite que o Data Vault reaja de forma flexível às alterações na lógica de negócios dos sistemas de origem, como mudanças na natureza das relações. Assim como o hub, o link não contém nenhuma informação descritiva. Consiste nos IDs de sequência dos hubs aos quais faz referência, um ID de sequência gerado pelo warehouse, um timestamp de carregamento e a fonte de registro.
#3. Satélites
Os satélites contêm as informações descritivas (contexto) para uma chave de negócio armazenada num hub ou um relacionamento armazenado num link. Os satélites funcionam com lógica de “somente inserção”, o que significa que o histórico de dados completo é armazenado no satélite. Vários satélites podem descrever uma única chave de negócio (ou relacionamento). No entanto, um satélite só pode descrever uma chave (hub ou link).
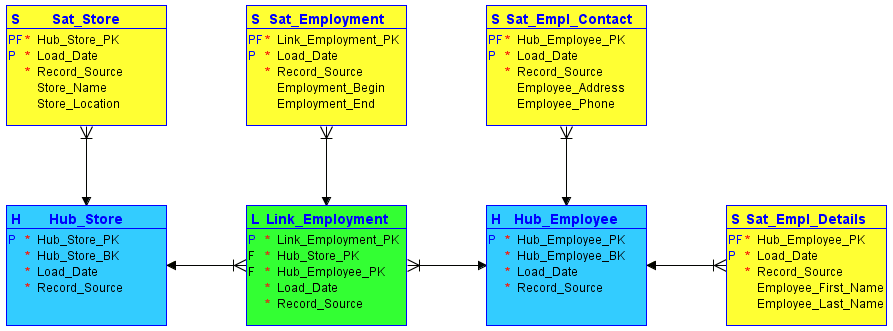 Fonte da imagem: Carbidfischer
Fonte da imagem: Carbidfischer
Como construir um modelo Data Vault
A construção de um modelo Data Vault envolve várias etapas, cada uma crucial para assegurar que o modelo seja escalável, flexível e capaz de atender às necessidades do negócio:
#1. Identificar Entidades e Atributos
Identifique as entidades de negócios e seus atributos correspondentes. Isso envolve trabalhar em estreita colaboração com os stakeholders para compreender os seus requisitos e os dados que precisam capturar. Após a identificação das entidades e atributos, separe-os em hubs, links e satélites.
#2. Definir relações entre entidades e criar links
Após a identificação das entidades e atributos, os relacionamentos entre as entidades são definidos e os links são criados para representar estes relacionamentos. Cada link recebe uma chave de negócio que identifica o relacionamento entre as entidades. Os satélites são adicionados para capturar os atributos e relacionamentos das entidades.
#3. Estabelecer regras e padrões
Após a criação dos links, um conjunto de regras e padrões de modelagem de Data Vault deve ser estabelecido para garantir que o modelo seja flexível e capaz de lidar com alterações ao longo do tempo. Estas regras e padrões devem ser revistos e atualizados regularmente para garantir que se mantenham relevantes e alinhados com as necessidades do negócio.
#4. Preencher o modelo
Após a criação do modelo, deve ser preenchido com dados utilizando uma abordagem de carregamento incremental. Isso envolve o carregamento dos dados nos hubs, links e satélites por meio de cargas delta. O carregamento delta garante que apenas as alterações feitas nos dados sejam carregadas, reduzindo o tempo e os recursos necessários para a integração de dados.
#5. Testar e validar o modelo
Finalmente, o modelo deve ser testado e validado para garantir que atende aos requisitos de negócio e que seja escalável e flexível o suficiente para lidar com mudanças futuras. A manutenção e atualizações regulares devem ser realizadas para garantir que o modelo permaneça alinhado com as necessidades de negócio e continue a fornecer uma visão unificada dos dados.
Recursos de aprendizagem do Data Vault
O domínio do Data Vault pode proporcionar habilidades e conhecimentos valiosos que são muito procurados nas indústrias atuais baseadas em dados. Aqui está uma lista abrangente de recursos, incluindo cursos e livros, que podem auxiliar na aprendizagem das complexidades do Data Vault:
#1. Modelagem de Data Warehouse com Data Vault 2.0

Este curso da Udemy oferece uma introdução completa à abordagem de modelagem do Data Vault 2.0, gestão de projetos Agile e integração de Big Data. O curso abrange os conceitos básicos e os fundamentos do Data Vault 2.0, incluindo a sua arquitetura e camadas, cofres de negócios e informações e técnicas avançadas de modelagem.
Ensina como projetar um modelo Data Vault do zero, converter modelos tradicionais como 3FN e modelos dimensionais em Data Vault e compreender os princípios da modelagem dimensional em Data Vault. O curso exige conhecimentos básicos de bases de dados e fundamentos de SQL.
Com uma alta classificação de 4,4 em 5 e mais de 1700 avaliações, este curso best-seller é adequado para quem procura construir uma base sólida em Data Vault 2.0 e integração de Big Data.
#2. Modelagem de Data Vault explicada com um caso de uso

Este curso da Udemy visa orientá-lo na criação de um modelo de Data Vault através de um exemplo prático de negócio. Serve como um guia para iniciantes em modelagem de Data Vault, abrangendo conceitos-chave como os cenários adequados para utilizar modelos Data Vault, as limitações da modelagem OLAP convencional e uma abordagem sistemática para construir um modelo Data Vault. O curso é acessível a pessoas com conhecimentos mínimos de bases de dados.
#3. The Data Vault Guru: um guia pragmático
O Data Vault Guru, de Patrick Cuba, é um guia completo sobre a metodologia Data Vault, que oferece uma oportunidade única de modelar o data warehouse corporativo utilizando princípios de automação semelhantes aos usados na entrega de software.
O livro fornece uma visão geral da arquitetura moderna e, em seguida, oferece um guia completo sobre como fornecer um modelo de dados flexível que se adapta às mudanças da empresa, o Data Vault.
Além disso, o livro estende a metodologia Data Vault, fornecendo correção automática de agendamento, trilhos de auditoria, controlo de metadados e integração com ferramentas de entrega ágil.
#4. Construindo um Data Warehouse Escalável com Data Vault 2.0
Este livro fornece aos leitores um guia completo para criar um data warehouse escalável do início ao fim utilizando a metodologia Data Vault 2.0.
Este livro abrange todos os aspetos essenciais da construção de um data warehouse escalável, incluindo a técnica de modelagem do Data Vault, projetada para evitar as falhas típicas de um data warehouse.
O livro apresenta numerosos exemplos para ajudar os leitores a entender os conceitos com clareza. Com os seus conhecimentos práticos e exemplos do mundo real, este livro é um recurso essencial para qualquer pessoa interessada em armazenamento de dados.
#5. O elefante no frigorífico: etapas guiadas para o sucesso do Data Vault
O livro “The Elephant in the Fridge”, de John Giles, é um guia prático que visa ajudar os leitores a alcançar o sucesso do Data Vault, começando com o negócio e terminando com o negócio.
O livro enfatiza a importância da ontologia corporativa e da modelagem de conceitos de negócios e fornece orientação passo a passo sobre como aplicar esses conceitos para criar um modelo de dados sólido.
Por meio de conselhos práticos e modelos de exemplo, o autor oferece uma explicação clara e direta de tópicos complexos, tornando o livro um excelente guia para quem é novo no Data Vault.
Considerações finais
O Data Vault representa o futuro do armazenamento de dados, oferecendo às empresas vantagens significativas em termos de agilidade, escalabilidade e eficiência. É particularmente adequado para empresas que precisam carregar grandes volumes de dados rapidamente e para aquelas que desejam desenvolver as suas aplicações de inteligência de negócios de forma ágil.
Além disso, as empresas que possuem uma arquitetura em silos já existente podem beneficiar muito com a implementação de um data warehouse central upstream utilizando o Data Vault.
Você também pode ter interesse em aprender sobre a linhagem de dados.