No cenário atual, onde dados são a força motriz, a coleta manual de informações tornou-se obsoleta. A disseminação de computadores com acesso à internet transformou a web em uma vasta fonte de dados. Nesse contexto, a raspagem web surge como um método moderno, eficiente e econômico para a coleta de informações. E, quando falamos de raspagem web em Python, a biblioteca Beautiful Soup se destaca como uma ferramenta essencial. Neste artigo, vou guiá-lo através dos passos para instalar o Beautiful Soup e iniciar seus projetos de raspagem.
Antes de explorarmos a instalação e o uso do Beautiful Soup, vamos entender por que você deveria considerá-lo.
O que é Beautiful Soup?
Imagine que você está pesquisando sobre “os efeitos da COVID na saúde pública” e encontra diversas páginas web com informações relevantes. No entanto, estas páginas não oferecem a opção de download dos dados com um simples clique. É aí que o Beautiful Soup entra em cena.
Beautiful Soup é uma das principais bibliotecas Python para extrair dados de websites. Ela facilita a recuperação de informações de páginas HTML ou XML.
Leonard Richardson concebeu o Beautiful Soup para raspagem web em 2004. Sua contribuição para o projeto continua até hoje, com atualizações frequentes em sua conta no Twitter.
Embora o Beautiful Soup tenha sido desenvolvido inicialmente com Python 3.8, ele opera sem problemas com Python 3 e até mesmo com Python 2.4.
Muitos sites utilizam proteção captcha para impedir que ferramentas de IA coletem seus dados. Nesses casos, algumas modificações no cabeçalho ‘user-agent’ no Beautiful Soup, ou o uso de APIs de resolução de Captcha, podem simular um navegador legítimo e burlar a detecção.
Se você não tem tempo para se aprofundar no Beautiful Soup ou prefere que a raspagem seja feita com maior eficiência e simplicidade, recomendo conhecer esta API de raspagem web. Basta inserir o URL e os dados são entregues a você.
Para programadores, a sintaxe clara do Beautiful Soup facilita a navegação em páginas web e a extração de dados desejados, com base em análises condicionais. Ao mesmo tempo, a ferramenta é acessível também para iniciantes.
Embora o Beautiful Soup não seja ideal para raspagens avançadas, ele funciona de maneira excelente para extrair dados de arquivos escritos em linguagens de marcação.
Outro ponto forte do Beautiful Soup é sua documentação clara e detalhada.
Agora, vamos aprender como instalar o Beautiful Soup em sua máquina.
Como instalar o Beautiful Soup para Web Scraping?
O Pip, um gerenciador de pacotes Python criado em 2008, tornou-se uma ferramenta padrão para desenvolvedores que desejam instalar bibliotecas ou dependências Python de forma descomplicada.
O Pip já vem incluso nas instalações das versões mais recentes do Python. Portanto, se você possui uma versão atualizada do Python em seu sistema, está pronto para começar.
Abra o prompt de comando e digite o seguinte comando pip para instalar o Beautiful Soup rapidamente.
pip install beautifulsoup4
Você verá algo similar à imagem abaixo em seu terminal.
É importante ter o instalador PIP atualizado para a versão mais recente, evitando erros comuns.
O comando para atualizar o instalador do pip é:
pip install --upgrade pip
Com isso, cobrimos metade do caminho neste artigo.
Agora que você tem o Beautiful Soup instalado em sua máquina, vamos aprofundar como usá-lo para raspagem web.
Como importar e usar o Beautiful Soup para Web Scraping?
Para importar o Beautiful Soup para o seu script Python, digite o seguinte comando em seu IDE:
from bs4 import BeautifulSoup
Agora o Beautiful Soup está disponível em seu arquivo Python para realizar raspagens.
Vamos analisar um exemplo de código para entender como extrair os dados desejados com o Beautiful Soup.
Podemos instruir o Beautiful Soup a procurar por tags HTML específicas no site de origem e coletar os dados contidos nessas tags.
Neste artigo, vou usar o site marketwatch.com, que atualiza os preços de ações de diversas empresas em tempo real. Vamos extrair alguns dados deste site para nos familiarizarmos com a biblioteca Beautiful Soup.
Importe os pacotes “requests”, que nos permitirá receber e responder a solicitações HTTP, e “urllib”, para carregar a página web a partir de seu URL.
from urllib.request import urlopen import requests
Salve o endereço da página web em uma variável para facilitar o acesso posterior.
url="https://www.marketwatch.com/investing/stock/amzn"
Em seguida, usaremos o método “urlopen” da biblioteca “urllib” para armazenar a página HTML em uma variável. Passe a URL para a função “urlopen” e salve o resultado em uma variável.
page = urlopen(url)
Crie um objeto Beautiful Soup e analise a página web desejada utilizando “html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')
Neste momento, todo o código HTML da página web de destino está armazenado na variável ‘soup_obj’.
Antes de prosseguir, vamos examinar o código fonte da página para entender a estrutura HTML e as tags.
Clique com o botão direito do mouse em qualquer ponto da página web. Em seguida, selecione a opção de inspeção, como exibido abaixo.
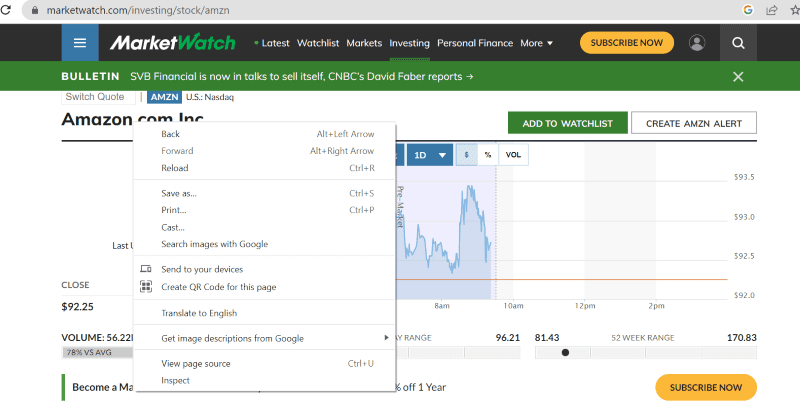
Clique em “inspecionar” para visualizar o código fonte.
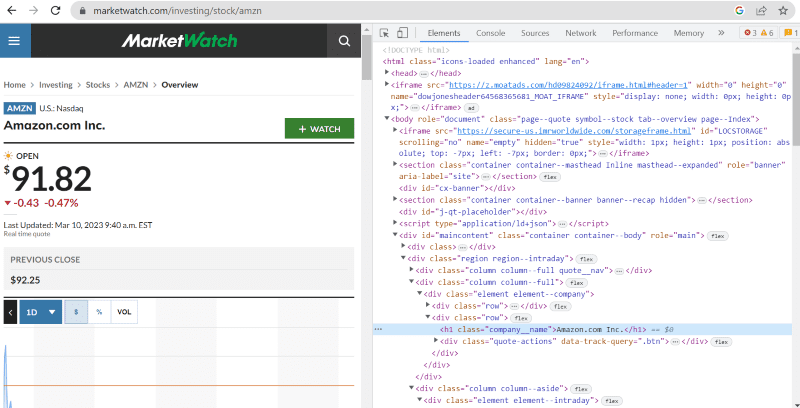
No código fonte acima, você encontrará tags, classes e detalhes sobre cada elemento visível na interface do site.
O método “find” do Beautiful Soup permite que procuremos por tags HTML específicas e recuperemos os dados desejados. Para isso, especificamos o nome da classe e as tags, extraindo assim os dados específicos.
Por exemplo, “Amazon.com Inc.” aparece na página web com a classe: ‘company__name’ marcada como ‘h1’. Podemos inserir estas informações no método ‘find’ para extrair o trecho HTML correspondente em uma variável.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Vamos imprimir o script HTML armazenado na variável “name” e o texto que nos interessa na tela.
print(name) print(name.text)

Você pode ver os dados extraídos sendo exibidos na tela.
Web Raspagem do site IMDb
Muitas pessoas consultam as avaliações de filmes no IMDb antes de decidir o que assistir. Esta demonstração fornecerá uma lista dos filmes mais bem avaliados e ajudará você a se familiarizar com o uso do Beautiful Soup para raspagem web.
Etapa 1: importe as bibliotecas Beautiful Soup e requests.
from bs4 import BeautifulSoup import requests
Etapa 2: vamos atribuir a URL que queremos raspar a uma variável chamada ‘url’ para facilitar o acesso no código.
O pacote “requests” é usado para obter a página HTML da URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Etapa 3: no trecho de código abaixo, analisaremos a página HTML da URL para criar um objeto Beautiful Soup.
soup_obj = BeautifulSoup(url.text, 'html.parser')
A variável “soup_obj” agora contém todo o script HTML da página desejada, conforme a imagem abaixo.
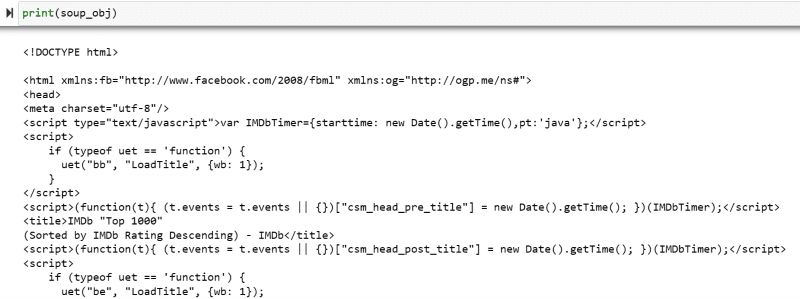
Vamos inspecionar o código fonte da página web para encontrar o script HTML dos dados que queremos extrair.
Passe o cursor sobre o elemento da página web que você quer extrair. Em seguida, clique com o botão direito do mouse e selecione a opção “inspecionar” para visualizar o código fonte deste elemento. Os visuais a seguir o guiarão melhor.
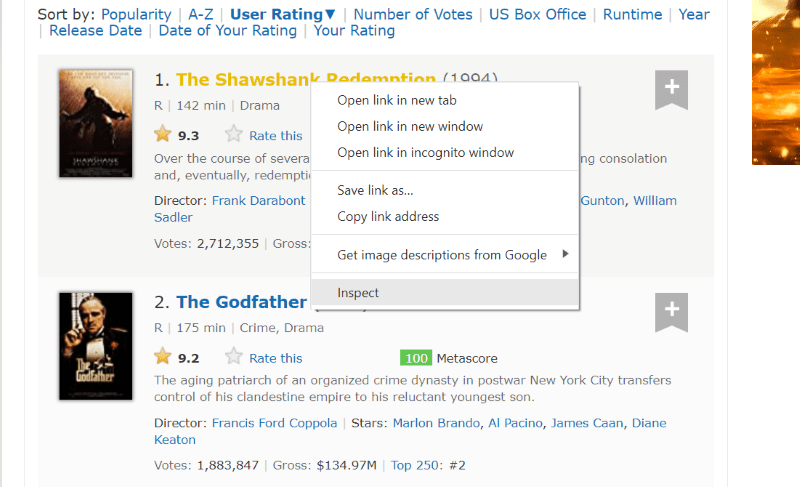
A classe ‘lister-list’ contém todos os dados relativos aos filmes com melhor classificação, como subdivisões em tags div sucessivas.
No script HTML de cada cartão de filme, na classe ‘lister-item mode-advanced’, temos uma tag ‘h3’ que armazena o nome do filme, sua classificação e o ano de lançamento, conforme destacado na imagem abaixo.
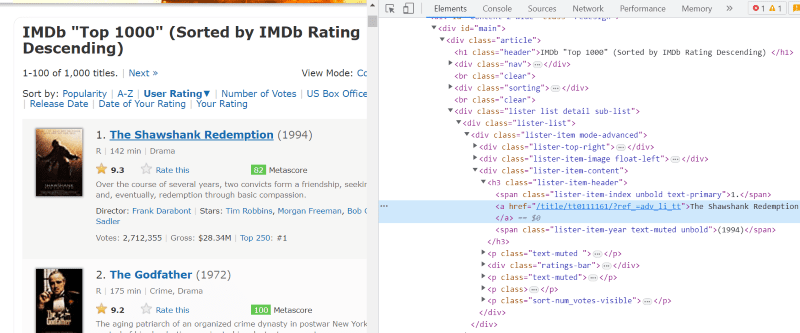
Nota: O método “find” do Beautiful Soup busca a primeira tag que corresponde ao nome de entrada especificado. Diferente do “find”, o método “find_all” busca todas as tags que correspondem à entrada fornecida.
Passo 4: Você pode usar os métodos “find” e “find_all” para salvar o script HTML do nome, classificação e ano de cada filme em uma variável de lista.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
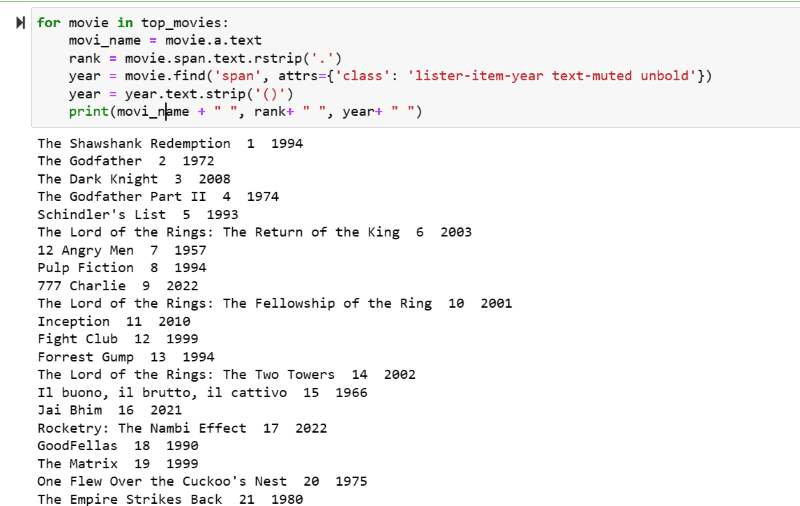
Etapa 5: percorra a lista de filmes armazenada na variável: “top_movies” e extraia o nome, a classificação e o ano de cada filme em formato de texto de seu script HTML usando o código abaixo.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
Na captura de tela de saída, você verá a lista de filmes com seu nome, classificação e ano de lançamento.
Você pode facilmente transferir os dados impressos para uma planilha do Excel com código Python adicional e usá-los para suas análises.
Considerações Finais
Este artigo o guiará na instalação do Beautiful Soup para raspagem web. Além disso, os exemplos de raspagem que eu forneci devem lhe dar uma base sólida para começar a usar o Beautiful Soup.
Dado seu interesse em como instalar o Beautiful Soup para raspagem web, recomendo que você consulte este guia completo para aprofundar seus conhecimentos em raspagem web usando Python.