A extração de dados da web, conhecida como web scraping, é uma técnica eficiente para coletar informações de websites de forma automatizada. Embora seja possível realizar essa tarefa manualmente, o processo pode ser demorado e entediante. O uso de ferramentas de web scraping agiliza essa atividade, tornando-a mais rápida, eficiente e econômica.
Surpreendentemente, o Google Sheets se revela uma ferramenta completa para web scraping, graças à função IMPORTXML. Com ela, é possível extrair dados de páginas da web com facilidade e utilizá-los em análises, relatórios e outras tarefas baseadas em dados.
A Função IMPORTXML no Google Sheets
O Google Sheets oferece a função IMPORTXML, que permite importar dados de diversos formatos da web, como XML, HTML, RSS e CSV. Essa função é extremamente útil para quem precisa coletar dados de websites sem se envolver em codificações complexas.
A sintaxe básica do IMPORTXML é a seguinte:
=IMPORTXML(url, xpath_query)
- url: o endereço da página da web de onde os dados serão extraídos.
- xpath_query: a consulta XPath que define os dados a serem coletados.
XPath (XML Path Language) é uma linguagem utilizada para navegar em documentos XML, incluindo HTML, permitindo especificar a localização dos dados dentro de uma estrutura HTML. O domínio das consultas XPath é essencial para o uso correto da função IMPORTXML.
Compreendendo o XPath
O XPath oferece diversas funções e expressões para navegar e filtrar dados em documentos HTML. Um guia abrangente sobre XML e XPath excede o propósito deste artigo, portanto, focaremos em alguns conceitos essenciais do XPath:
- Seleção de elementos: elementos são selecionados através de / e // para indicar caminhos. Por exemplo, /html/body/div seleciona todos os elementos div dentro do corpo de um documento.
- Seleção de atributos: atributos são selecionados usando @. Por exemplo, //@href seleciona todos os atributos href da página.
- Filtros de predicado: a filtragem de elementos ocorre com o uso de predicados entre colchetes ([ ]). Por exemplo, /div[@class=”container”] seleciona todos os elementos div que possuem a classe container.
- Funções: o XPath oferece diversas funções, como contains(), starts-with() e text(), para realizar ações específicas, como verificar o conteúdo de textos ou valores de atributos.
Até agora, você já conhece a sintaxe do IMPORTXML, tem a URL do site e sabe qual elemento deseja extrair. Mas como encontrar o XPath de um elemento?
Não é necessário conhecer a estrutura do site de cor para extrair dados com IMPORTXML. Na verdade, os navegadores oferecem uma ferramenta que permite copiar o XPath de qualquer elemento instantaneamente.
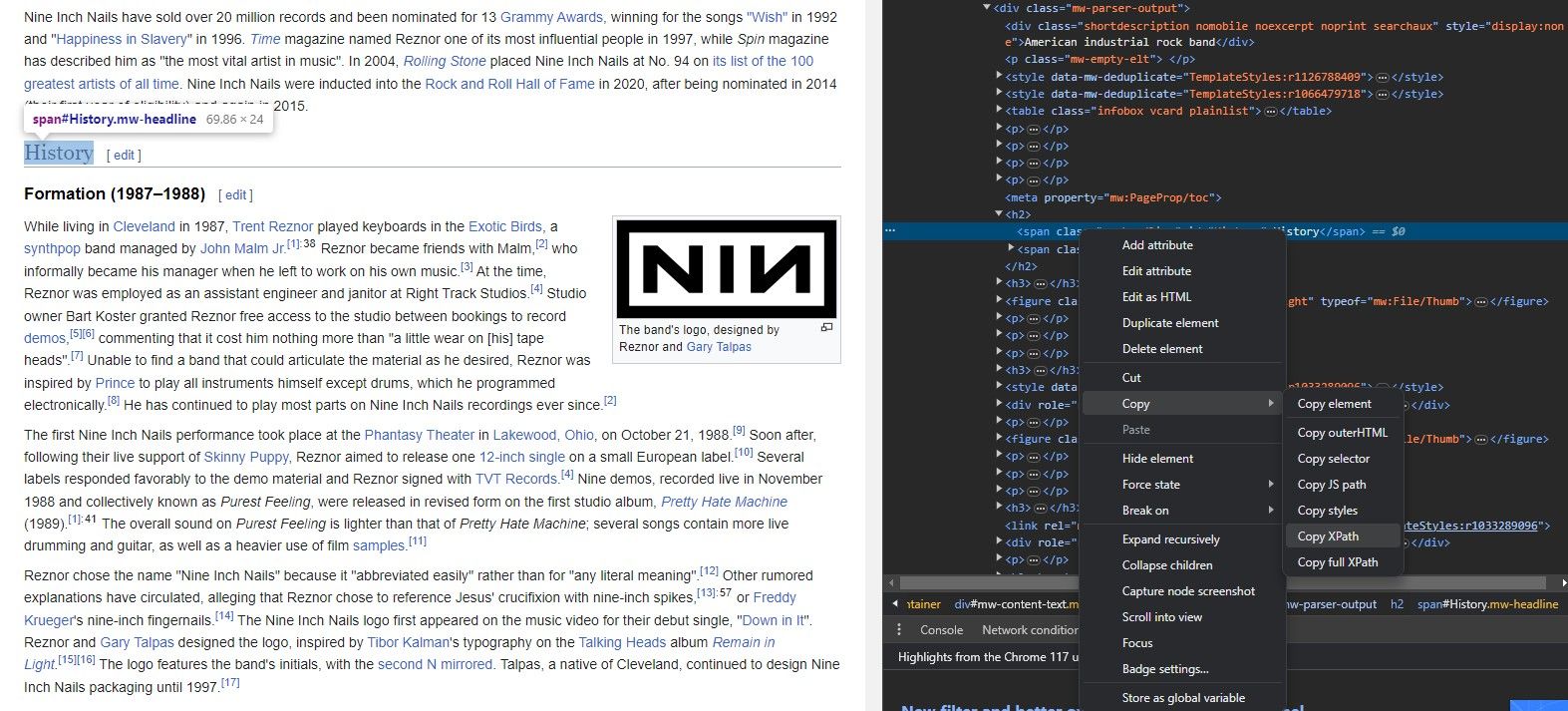
A ferramenta “Inspecionar elemento” permite obter o XPath de elementos do site. Veja como:
Agora, com tudo o que você precisa, vamos usar o IMPORTXML na prática e extrair alguns links.
Como Extrair Links de um Site com IMPORTXML
O IMPORTXML permite extrair diversos tipos de dados de sites, incluindo links, vídeos, imagens e quase todos os elementos do site. Os links são elementos cruciais para a análise da web, permitindo obter informações valiosas sobre um site através da análise das páginas para as quais ele aponta.
Com o IMPORTXML, você pode extrair links rapidamente no Google Sheets e analisá-los usando as diversas funções que a ferramenta oferece.
1. Extrair Todos os Links
Para extrair todos os links de uma página da web, utilize a seguinte fórmula:
=IMPORTXML(url, "//a/@href")
Essa consulta XPath seleciona todos os atributos href de um elemento, extraindo todos os links da página.
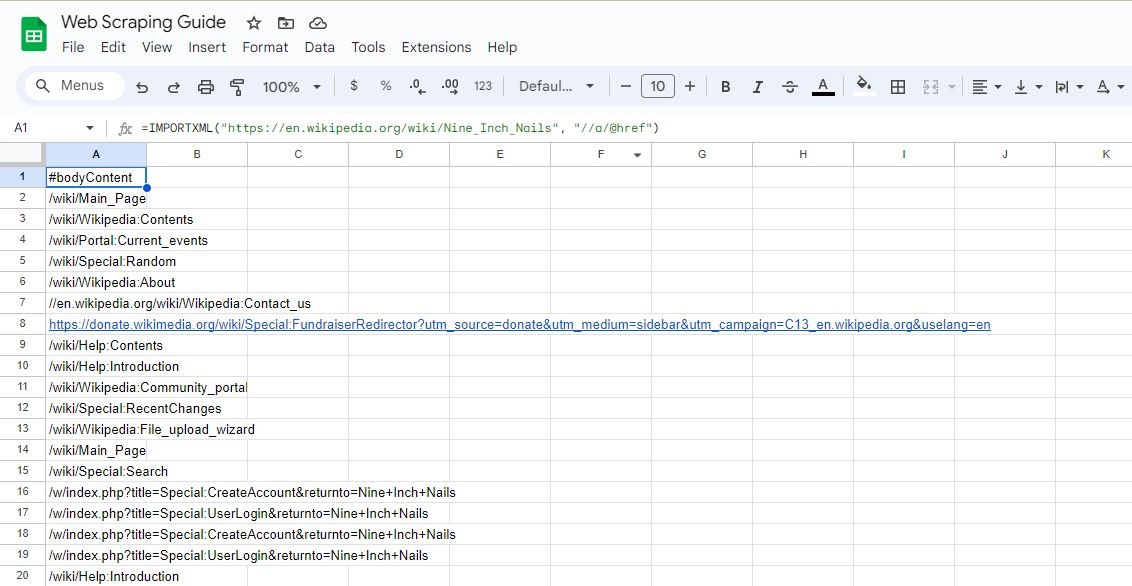
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
A fórmula acima extrai todos os links de um artigo da Wikipedia.
É recomendado inserir a URL da página da web em uma célula separada e fazer referência a essa célula. Isso evita que a fórmula fique muito longa e complexa. O mesmo pode ser feito com a consulta XPath.
2. Extrair Todos os Textos dos Links
Para extrair o texto dos links junto com suas URLs, utilize:
=IMPORTXML(url, "//a")
Essa consulta seleciona todos os elementos , permitindo extrair o texto do link e as URLs dos resultados.
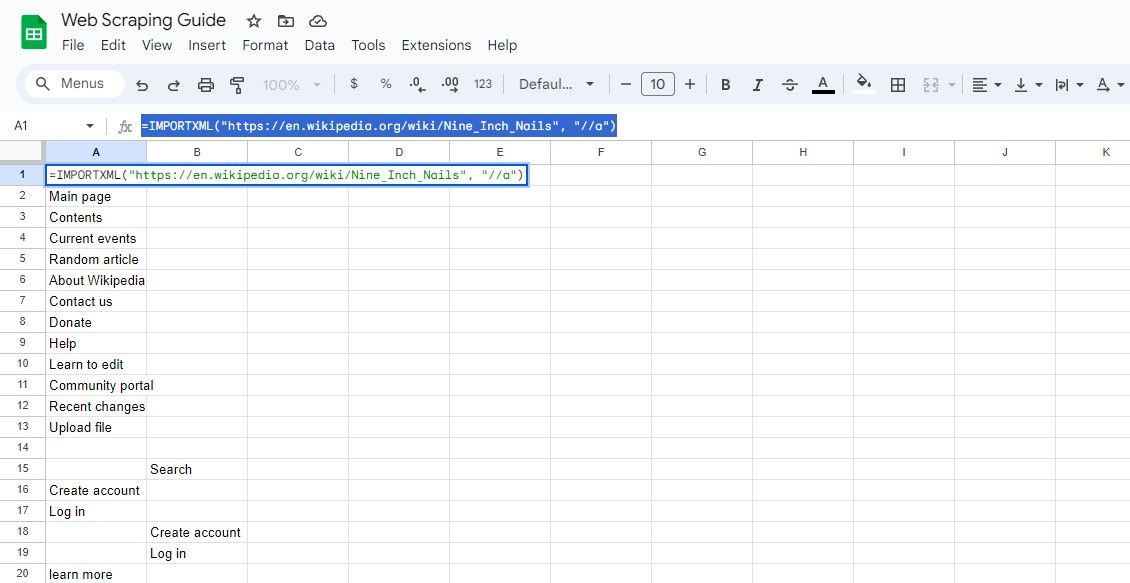
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
A fórmula acima obtém os textos dos links no mesmo artigo da Wikipedia.
Como Extrair Links Específicos de um Site com IMPORTXML
Em algumas situações, pode ser necessário extrair links específicos com base em critérios. Por exemplo, pode ser preciso extrair links que contenham uma palavra-chave específica ou links que estejam localizados em uma seção específica da página.
Com um bom conhecimento de XPath, é possível localizar qualquer elemento desejado.
1. Extração de Links Contendo uma Palavra-Chave
Para extrair links que contenham uma palavra-chave específica, utilize a função contains() do XPath:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Essa consulta seleciona os atributos href dos elementos onde o atributo href contém a palavra-chave especificada.
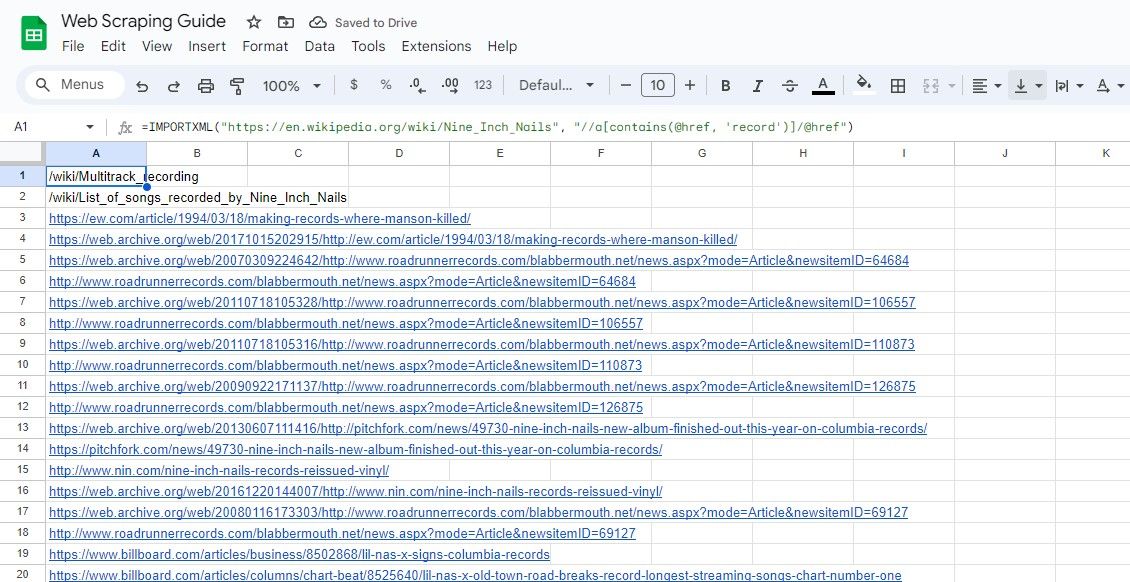
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
A fórmula acima extrai todos os links que contêm a palavra “record” em seu texto em um exemplo de artigo da Wikipedia.
2. Extração de Links Dentro de uma Seção
Para extrair links de uma seção específica da página, especifique o XPath da seção. Por exemplo:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Essa consulta seleciona os atributos href dos elementos dentro dos elementos div que possuem a classe “section”.
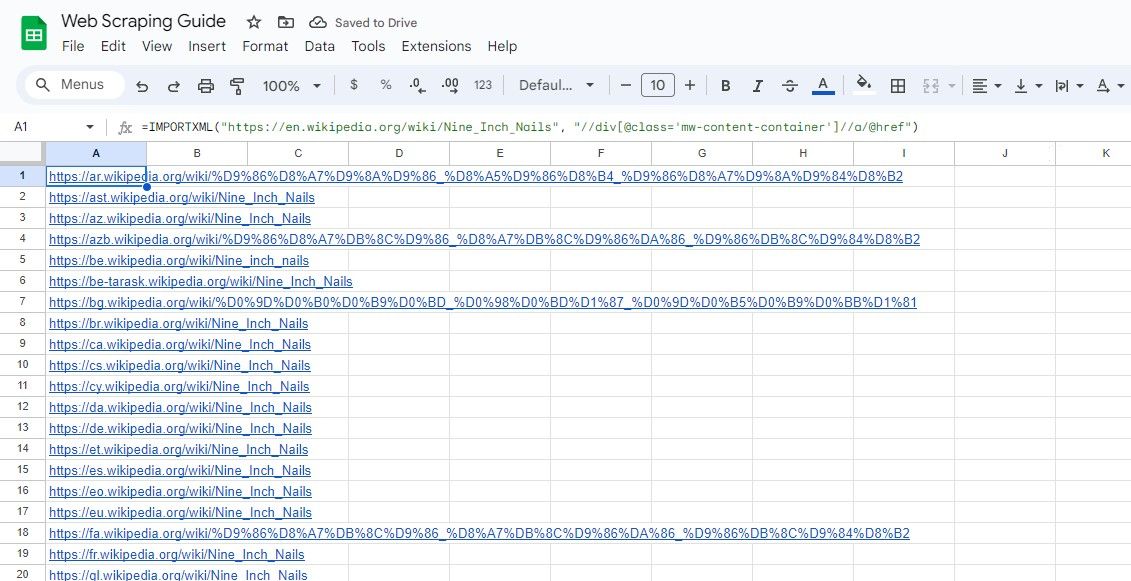
De forma semelhante, a fórmula abaixo seleciona todos os links dentro da classe div que possui a classe “mw-content-container”:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
É importante notar que o IMPORTXML pode ser usado para mais do que web scraping. A família de funções IMPORT permite importar tabelas de dados de sites para o Google Sheets.
Embora o Google Sheets e o Excel compartilhem a maioria das funções, a família de funções IMPORT é exclusiva do Google Sheets. Para importar dados de sites para o Excel, outros métodos devem ser considerados.
Simplifique o Web Scraping com o Google Sheets
O web scraping com o Google Sheets e a função IMPORTXML é uma forma versátil e acessível de coletar dados de websites.
Ao dominar o XPath e aprender a criar consultas eficazes, é possível explorar todo o potencial do IMPORTXML e obter informações valiosas de recursos da web. Comece a extrair dados e eleve sua análise da web a um novo nível!