As estruturas de dados conhecidas como DataFrames são essenciais na linguagem R, proporcionando a organização, adaptabilidade e ferramentas indispensáveis para a análise e manipulação de informações. Sua relevância abrange diversas áreas, incluindo estatística, ciência de dados e a tomada de decisões baseada em dados em todos os setores.
Os DataFrames oferecem a estrutura e organização necessárias para revelar insights valiosos e tomar decisões informadas de maneira sistemática e eficiente.
Em R, os DataFrames são organizados como tabelas, compostas por linhas e colunas. Cada linha representa uma observação, enquanto cada coluna corresponde a uma variável específica. Essa disposição facilita a organização e o trabalho com os dados. DataFrames podem conter uma variedade de tipos de dados, como números, textos e datas, o que os torna extremamente versáteis.
Neste artigo, abordaremos a importância dos DataFrames, demonstrando como criá-los utilizando a função `data.frame()`. Além disso, exploraremos métodos para manipulação de dados e aprenderemos como gerar arquivos CSV e Excel, transformar outras estruturas de dados em DataFrames, e utilizar a biblioteca `tibble`.
Aqui estão alguns dos principais motivos pelos quais os DataFrames são cruciais em R:
A Importância dos DataFrames

- Armazenamento de Dados Estruturados: DataFrames oferecem uma forma estruturada e tabular de armazenar dados, semelhante a uma planilha. Esse formato simplifica o gerenciamento e a organização das informações.
- Tipos de Dados Diversificados: DataFrames podem acomodar diferentes tipos de dados na mesma estrutura. É possível ter colunas com valores numéricos, sequências de caracteres, fatores, datas e muito mais. Essa versatilidade é fundamental ao trabalhar com dados reais.
- Organização de Dados: Cada coluna em um DataFrame representa uma variável, enquanto cada linha representa uma observação ou caso. Essa organização estruturada facilita a compreensão da estrutura dos dados, melhorando a clareza das informações.
- Importação e Exportação de Dados: DataFrames facilitam a importação e exportação de dados de diversos formatos de arquivo, como CSV, Excel e bancos de dados. Essa capacidade agiliza o processo de trabalho com fontes de dados externas.
- Interoperabilidade: DataFrames são amplamente suportados por pacotes e funções R, garantindo compatibilidade com outras ferramentas e bibliotecas estatísticas e de análise de dados. Essa interoperabilidade permite uma integração perfeita no ecossistema R.
- Manipulação de Dados: R oferece um vasto conjunto de pacotes, com “dplyr” sendo um exemplo notável. Esses pacotes facilitam a filtragem, transformação e sumarização de dados usando DataFrames, o que é crucial para a limpeza e preparação dos dados.
- Análise Estatística: DataFrames são o formato de dados padrão para muitas funções estatísticas e de análise de dados em R. Regressão, testes de hipóteses e muitas outras análises podem ser realizadas eficientemente utilizando DataFrames.
- Visualização: Pacotes de visualização de dados como ggplot2 funcionam perfeitamente com DataFrames. Isso facilita a criação de tabelas e gráficos informativos para a exploração e comunicação de dados.
- Exploração de Dados: DataFrames facilitam a exploração de dados através de estatísticas resumidas, visualizações e outros métodos analíticos. Isso auxilia analistas e cientistas de dados a compreender as características dos dados e identificar padrões ou anomalias.
Como Criar DataFrames em R
Existem diversas formas de criar um DataFrame em R. Aqui estão alguns dos métodos mais comuns:
#1. Utilizando a Função `data.frame()`
# Verifica se a biblioteca "dplyr" está instalada e a carrega
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
library(dplyr)
# Define uma semente para reprodutibilidade
set.seed(42)
# Cria um DataFrame de vendas de exemplo
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Exibe o DataFrame
print(sales_data)
Vamos entender o que este código faz:
- Inicialmente, verifica se a biblioteca “dplyr” está presente no ambiente R.
- Caso “dplyr” não esteja instalada, ela é instalada e carregada.
- Em seguida, uma semente aleatória é definida para garantir a reprodutibilidade dos resultados.
- Um DataFrame de vendas de exemplo é criado com dados predefinidos.
- Finalmente, o DataFrame de vendas é exibido no console para visualização.
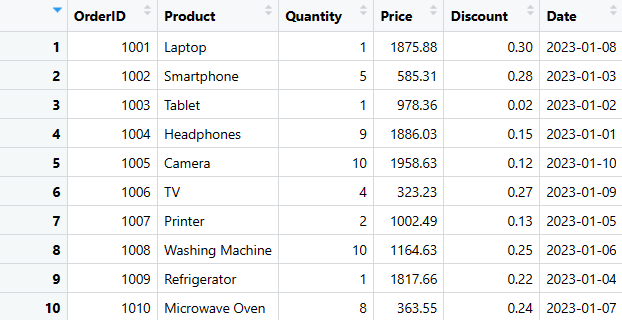
Esta é uma das maneiras mais simples de criar um DataFrame em R. Agora, exploraremos como extrair, adicionar, excluir e selecionar colunas ou linhas específicas, bem como como resumir os dados.
Extrair Colunas
Existem dois métodos para extrair as colunas necessárias de um DataFrame:
- Para recuperar as três últimas colunas de um DataFrame, podemos usar a indexação.
- Para extrair colunas individualmente, podemos usar o operador `$` quando queremos acessar uma coluna específica pelo nome.
Veremos os dois juntos para economizar tempo:
# Extrai as três últimas colunas (Discount, Price e Date)
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Exibe as colunas extraídas
print(last_three_columns)
############################################# OU #########################################################
# Extrai as três últimas colunas usando o operador $
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Cria um novo DataFrame com as colunas extraídas
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Exibe as colunas extraídas
print(last_three_columns)
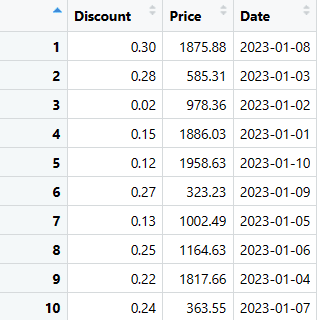
Você pode usar qualquer um desses códigos para extrair as colunas desejadas.
A extração de linhas de um DataFrame pode ser feita através de vários métodos. Aqui está uma maneira simples de realizar essa operação:
# Extrai linhas específicas (linhas 3, 6 e 9) do DataFrame last_three_columns selected_rows <- last_three_columns[c(3, 6, 9), ] # Exibe as linhas selecionadas print(selected_rows)
Você também pode usar condições específicas:
# Extrai e organiza as linhas que atendem às condições especificadas selected_rows <- sales_data %>% filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Discount, Price, Date) # Exibe as linhas selecionadas print(selected_rows)
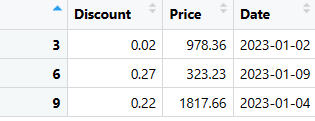
Adicionar Nova Linha
Para adicionar uma nova linha a um DataFrame existente, use a função `rbind()`:
# Cria uma nova linha como um DataFrame
new_row <- data.frame(
OrderID = 1011,
Product = "Coffee Maker",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Usa a função rbind() para adicionar a nova linha ao DataFrame
sales_data <- rbind(sales_data, new_row)
# Exibe o DataFrame atualizado
print(sales_data)
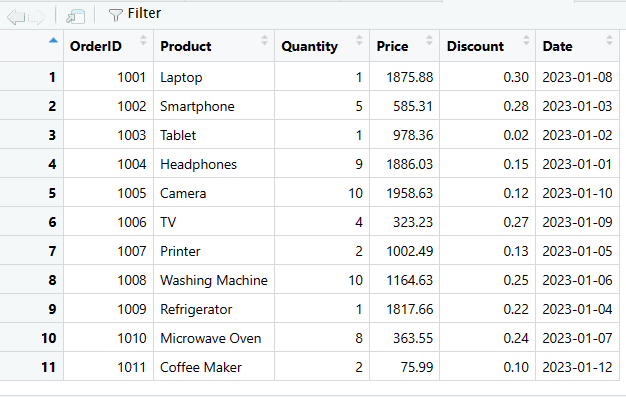
Adicionar Nova Coluna
Você pode adicionar colunas ao seu DataFrame com um código simples. Por exemplo, vamos adicionar uma coluna “Forma de Pagamento” aos dados:
# Cria uma nova coluna "PaymentMethod" com valores para cada linha
sales_data$PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Exibe o DataFrame atualizado
print(sales_data)
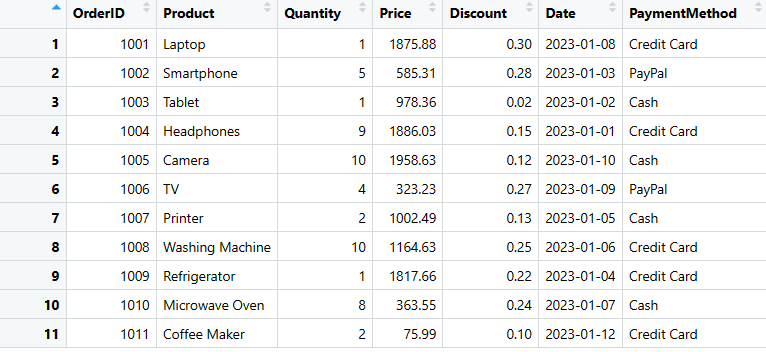
Excluir Linhas
Se você precisar remover linhas desnecessárias, este método pode ser útil:
# Identifica a linha a ser excluída com base em seu OrderID row_to_delete <- sales_data$OrderID == 1010 # Usa a linha identificada para excluí-la e criar um novo DataFrame sales_data <- sales_data[!row_to_delete, ] # Exibe o DataFrame atualizado sem a linha excluída print(sales_data)
Excluir Colunas
Você pode excluir uma coluna de um DataFrame utilizando o pacote `dplyr`:
library(dplyr) # Remove a coluna "Discount" usando a função select() sales_data <- sales_data %>% select(-Discount) # Exibe o DataFrame atualizado sem a coluna "Discount" print(sales_data)
Obter Resumo
Para obter um resumo dos seus dados, utilize a função `summary()`. Ela fornece uma visão geral das tendências centrais e da distribuição das variáveis numéricas nos dados:
# Obtém um resumo dos dados data_summary <- summary(sales_data) # Exibe o resumo print(data_summary)
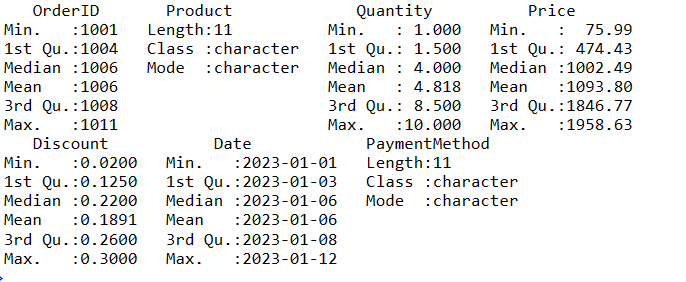
Estas são as várias etapas que podem ser seguidas para manipular dados dentro de um DataFrame.
Vamos agora explorar o segundo método para criar um DataFrame.
#2. Criar um DataFrame R a partir de um Arquivo CSV
Para criar um DataFrame a partir de um arquivo CSV, você pode utilizar a função `read.csv()`:
# Lê o arquivo CSV e o transforma em um DataFrame
df <- read.csv("my_data.csv")
# Visualiza as primeiras linhas do DataFrame
head(df)
Essa função lê os dados de um arquivo CSV e os converte em um DataFrame, permitindo o trabalho com os dados em R.
# Instala e carrega o pacote readr, caso não esteja instalado
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Lê o arquivo CSV e o transforma em um DataFrame
df <- read_csv("data.csv")
# Visualiza as primeiras linhas do DataFrame
head(df)
Você pode usar o pacote `readr` para ler um arquivo CSV em R. A função `read_csv()` do pacote `readr` é comumente usada para esse propósito, sendo mais rápida do que o método padrão.
#3. Usando a Função `as.data.frame()`
Você pode criar um DataFrame utilizando a função `as.data.frame()`. Essa função permite converter outras estruturas de dados, como matrizes ou listas, em um DataFrame.
Veja como usá-la:
# Cria uma lista aninhada para representar os dados
data_list <- list(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Converte a lista aninhada para um DataFrame
sales_data <- as.data.frame(data_list)
# Exibe o DataFrame
print(sales_data)
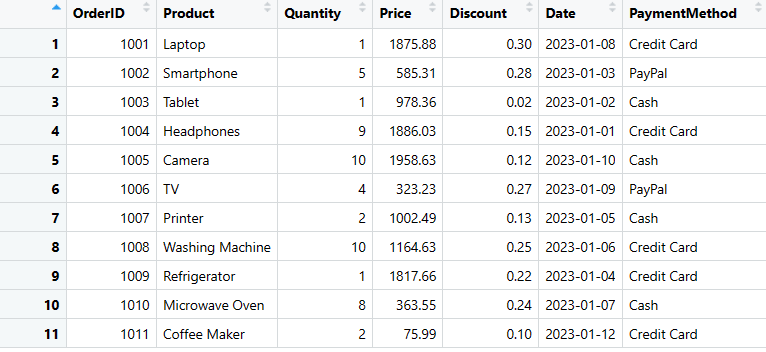
Este método permite criar um DataFrame sem especificar cada coluna individualmente, sendo particularmente útil ao lidar com grandes quantidades de dados.
#4. A partir de um DataFrame Existente
Para criar um novo DataFrame selecionando colunas ou linhas específicas de um DataFrame existente, você pode usar colchetes `[]` para indexação:
# Seleciona linhas e colunas
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Exibe o subconjunto selecionado
print(sales_subset)
Neste código, estamos criando um novo DataFrame chamado `sales_subset`, que contém linhas específicas (1, 3 e 4) e colunas específicas (“Product” e “Quantity”) de `sales_data`.
Você pode ajustar os índices e nomes das linhas e colunas para selecionar os dados necessários.

#5. A partir de um Vetor
Um vetor é uma estrutura de dados unidimensional que consiste em elementos do mesmo tipo, como lógico, inteiro, duplo, caractere, complexo ou bruto. Por outro lado, um DataFrame é uma estrutura bidimensional projetada para armazenar dados em formato tabular com linhas e colunas. Existem vários métodos para criar um DataFrame a partir de um vetor, como o exemplo abaixo:
# Cria vetores para cada coluna
OrderID <- 1001:1011
Product <- c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Cria o DataFrame usando a função data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Exibe o DataFrame
print(sales_data)
Neste código, criamos vetores separados para cada coluna e usamos a função `data.frame()` para combinar esses vetores em um DataFrame chamado `sales_data`, permitindo criar uma tabela estruturada a partir de vetores individuais.
#6. A partir de um Arquivo Excel
Para importar um arquivo Excel para um DataFrame em R, você pode usar pacotes de terceiros como `readxl`, pois R base não oferece suporte nativo para leitura de arquivos Excel. Uma função para leitura de arquivos Excel é `read_excel()`:
# Carrega a biblioteca readxl library(readxl) # Define o caminho do arquivo Excel excel_file_path <- "your_file.xlsx" # Substitua pelo caminho real do arquivo # Lê o arquivo Excel e cria um DataFrame data_frame_from_excel <- read_excel(excel_file_path) # Exibe o DataFrame print(data_frame_from_excel)
Este código lê o arquivo Excel e armazena seus dados em um DataFrame R, permitindo o uso dos dados em seu ambiente R.
#7. A partir de um Arquivo de Texto
A função `read.table()` pode ser utilizada para importar um arquivo de texto para um DataFrame. Essa função requer dois parâmetros essenciais: o nome do arquivo e o delimitador que especifica como os campos do arquivo são separados.
# Define o nome do arquivo e o delimitador file_name <- "your_text_file.txt" # Substitua pelo nome real do arquivo delimiter <- "\t" # Substitua pelo delimitador real (ex: "\t" para tabulação, "," para CSV) # Usa a função read.table() para criar um DataFrame data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Exibe o DataFrame print(data_frame_from_text)
Este código lê o arquivo de texto e cria um DataFrame em R, tornando-o acessível para análise de dados.
#8. Usando Tibble
Para criar um DataFrame utilizando os vetores fornecidos e a biblioteca `tidyverse`, siga estas etapas:
# Carrega a biblioteca tidyverse
library(tidyverse)
# Cria um tibble usando os vetores fornecidos
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Exibe o tibble de vendas criado
print(sales_data)
Este código usa a função `tibble()` da biblioteca `tidyverse` para criar um DataFrame `tibble` chamado `sales_data`. O formato `tibble` fornece uma impressão mais informativa em comparação com o DataFrame padrão de R.
Como Usar DataFrames Eficientemente em R
Utilizar DataFrames eficientemente em R é fundamental para a manipulação e análise de dados. DataFrames são uma estrutura de dados essencial em R, normalmente criados e manipulados usando a função `data.frame()`. Aqui estão algumas dicas para trabalhar de forma eficiente:
- Antes de criar, verifique se seus dados estão limpos e bem estruturados. Remova linhas ou colunas desnecessárias, lide com valores ausentes e certifique-se de que os tipos de dados sejam adequados.
- Defina os tipos de dados apropriados para suas colunas (por exemplo, numérico, caractere, fator, data). Isso pode melhorar o uso da memória e a velocidade de computação.
- Use indexação e subconjuntos para trabalhar com partes menores dos seus dados. O `subset()` e os operadores `[]` são úteis para este propósito.
- Embora o uso de `attach()` e `detach()` possa ser conveniente, eles também podem levar a ambiguidades e comportamentos inesperados.
- R é altamente otimizado para operações vetorizadas. Sempre que possível, utilize funções vetorizadas em vez de loops para manipulação de dados.
- Loops aninhados podem ser lentos em R. Em vez de loops aninhados, tente usar operações vetorizadas ou aplicar funções como `lapply` ou `sapply`.
- DataFrames grandes podem consumir muita memória. Considere usar pacotes como `data.table` ou `dtplyr`, que são mais eficientes em termos de memória para conjuntos de dados maiores.
- R possui uma ampla gama de pacotes para manipulação de dados. Utilize pacotes como `dplyr`, `tidyr` e `data.table` para transformações eficientes de dados.
- Minimize o uso de variáveis globais, especialmente ao trabalhar com vários DataFrames. Utilize funções e passe DataFrames como argumentos.
- Ao trabalhar com dados agregados, use as funções `group_by()` e `summary()` em `dplyr` para realizar cálculos eficientemente.
- Para conjuntos de dados grandes, considere usar o processamento paralelo com pacotes como `parallel` ou `foreach` para acelerar as operações.
- Ao ler dados em R, use funções como `readr` ou `data.table::fread` em vez de funções R básicas como `read.csv` para uma importação de dados mais rápida.
- Para conjuntos de dados muito grandes, considere usar sistemas de banco de dados ou formatos de armazenamento especializados, como Feather, Arrow ou Parquet.
Seguindo essas práticas recomendadas, você pode trabalhar eficientemente com DataFrames em R, tornando suas tarefas de manipulação e análise de dados mais gerenciáveis e rápidas.
Considerações Finais
Criar DataFrames em R é simples, e existem diversos métodos disponíveis. Abordamos a importância dos DataFrames e discutimos sua criação usando a função `data.frame()`.
Além disso, exploramos métodos para manipulação de dados, abordamos como criar arquivos CSV e Excel, converter outras estruturas de dados em DataFrames e utilizar a biblioteca `tibble`.
Você pode estar interessado nos melhores IDEs para programação R.