Principais Conclusões
- A simultaneidade e o paralelismo são conceitos essenciais na execução de tarefas em computação, cada um com características distintas.
- A simultaneidade otimiza o uso de recursos e a capacidade de resposta das aplicações, enquanto o paralelismo é vital para o desempenho e a escalabilidade.
- Python oferece ferramentas para lidar com simultaneidade (threading e programação assíncrona com asyncio) e paralelismo (módulo multiprocessing).
A simultaneidade e o paralelismo são técnicas que permitem a execução de múltiplas operações de forma aparentemente simultânea. Em Python, existem diversas abordagens para gerenciar tarefas simultâneas e paralelas, o que pode gerar dúvidas.
Este artigo explora as ferramentas e bibliotecas disponíveis para implementar simultaneidade e paralelismo em Python de forma eficaz, detalhando suas diferenças e aplicações.
Compreendendo a Simultaneidade e o Paralelismo
Simultaneidade e paralelismo são dois princípios fundamentais na execução de tarefas computacionais, cada um com suas particularidades.

A Importância da Simultaneidade e do Paralelismo
A necessidade de simultaneidade e paralelismo em computação é inegável. Vejamos os motivos:
Simultaneidade em Python
A simultaneidade em Python pode ser alcançada através de threading e programação assíncrona utilizando a biblioteca asyncio.
Threading em Python
Threading é um mecanismo de simultaneidade em Python que permite criar e gerenciar tarefas dentro de um mesmo processo. Threads são ideais para tarefas vinculadas a operações de E/S (entrada/saída) e se beneficiam da execução simultânea.
O módulo threading do Python oferece uma interface de alto nível para criar e gerenciar threads. Embora o GIL (Global Interpreter Lock) limite o paralelismo verdadeiro, os threads ainda podem alcançar a simultaneidade intercalando tarefas de forma eficiente.
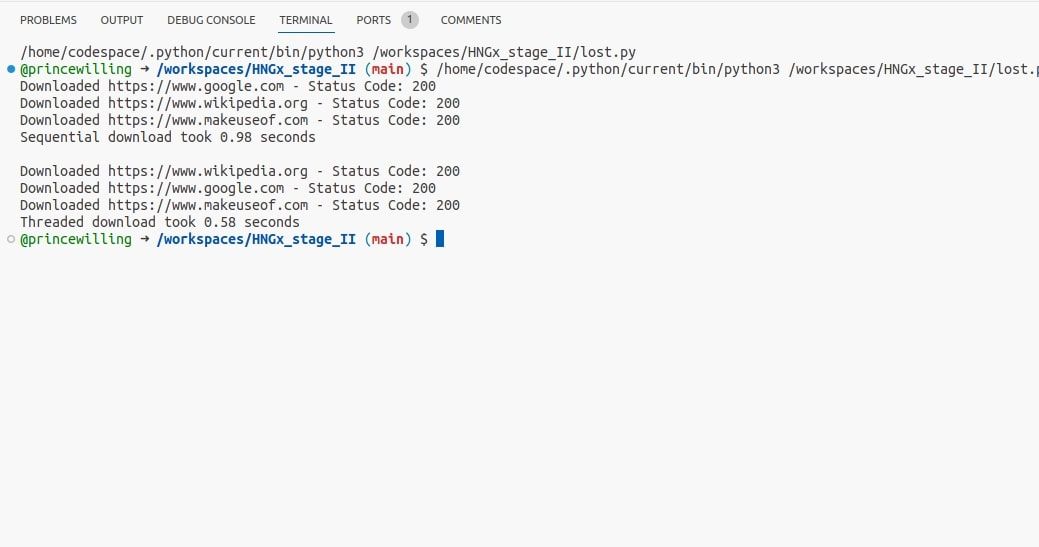
O código a seguir demonstra um exemplo de simultaneidade com threads. Ele utiliza a biblioteca requests para enviar requisições HTTP, uma tarefa comum de bloqueio de E/S, e o módulo time para calcular o tempo de execução.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
Ao executar este código, é possível observar que as requisições com threads são mais rápidas que as sequenciais. Embora a diferença seja pequena nesse exemplo, fica clara a melhoria de desempenho ao usar threads para tarefas de E/S.
Programação Assíncrona com Asyncio
O asyncio oferece um loop de eventos para gerenciar tarefas assíncronas chamadas corrotinas. Corrotinas são funções que podem ser pausadas e retomadas, ideais para tarefas de E/S. A biblioteca é útil em cenários onde as tarefas dependem de recursos externos, como requisições de rede.
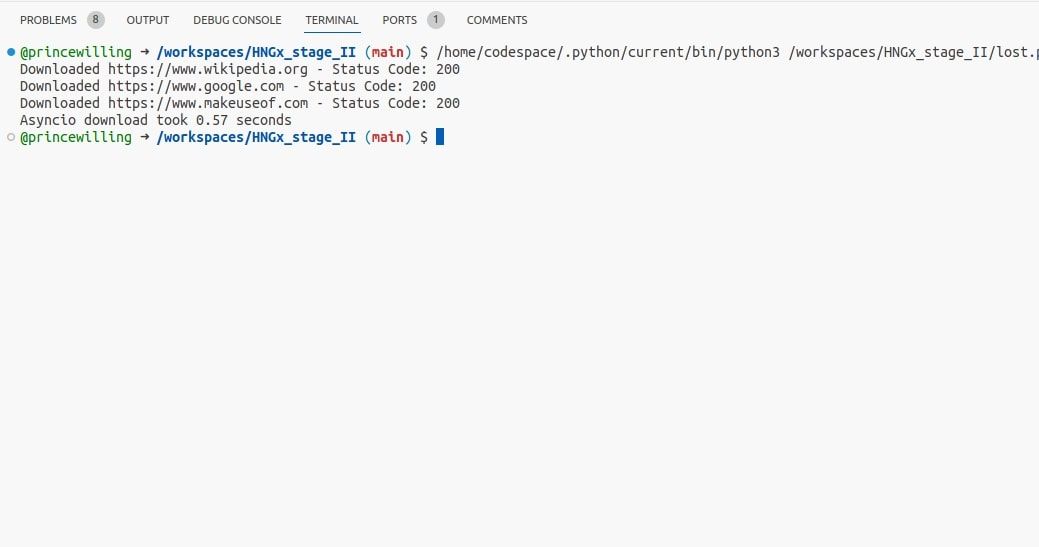
O exemplo anterior de requisições pode ser modificado para utilizar asyncio:
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
Este código demonstra como baixar páginas web simultaneamente com asyncio, aproveitando as vantagens de operações de E/S assíncronas, o que pode ser mais eficiente do que threading em tarefas de E/S.
Paralelismo em Python
O paralelismo em Python pode ser implementado utilizando o módulo multiprocessing, que permite o uso total de processadores multi-core.
Multiprocessing em Python
O módulo multiprocessing do Python oferece uma forma de alcançar o paralelismo através da criação de processos separados, cada um com seu próprio interpretador Python e espaço de memória. Isso contorna o Global Interpreter Lock (GIL), tornando-o adequado para tarefas vinculadas à CPU.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()
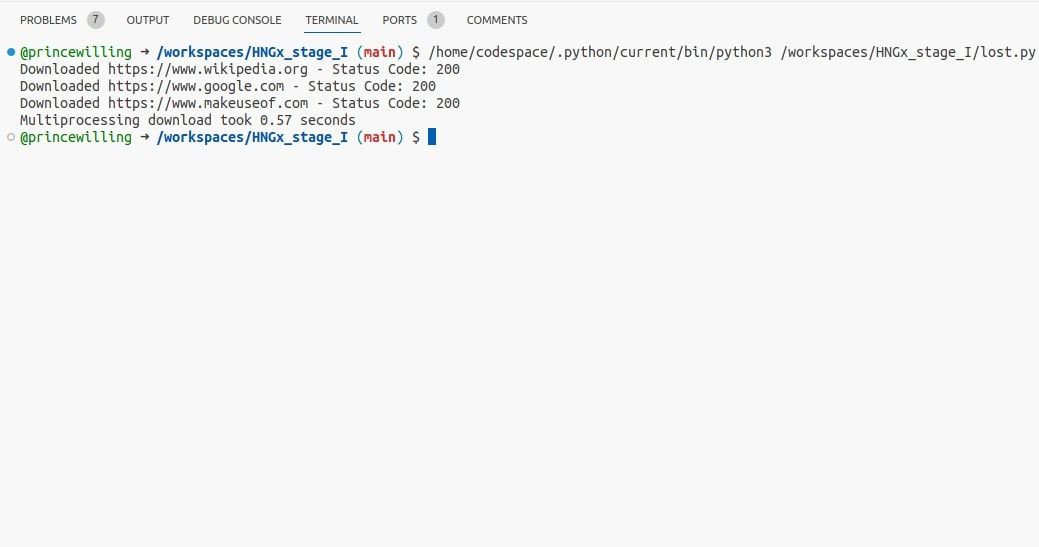
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
Nesse exemplo, o multiprocessing gera múltiplos processos, permitindo que a função download_url seja executada em paralelo.
Quando Utilizar Simultaneidade ou Paralelismo
A escolha entre simultaneidade e paralelismo depende da natureza das tarefas e dos recursos de hardware disponíveis.
A simultaneidade é mais indicada para tarefas de E/S, como leitura e escrita em arquivos ou requisições de rede, e quando há restrições de memória.
O multiprocessing deve ser utilizado para tarefas vinculadas à CPU, que se beneficiam do paralelismo verdadeiro, e quando há necessidade de isolamento entre tarefas para que a falha de uma não afete outras.
Aproveitando as Vantagens da Simultaneidade e do Paralelismo
O paralelismo e a simultaneidade são estratégias eficazes para melhorar a responsividade e o desempenho do código Python. É fundamental entender as diferenças entre esses conceitos e escolher a abordagem mais adequada.
Python oferece as ferramentas e os módulos necessários para otimizar o código com simultaneidade ou paralelismo, seja para processos vinculados à CPU ou à E/S.