A colaboração no aprendizado pode aprimorar suas decisões e solucionar diversos problemas práticos, integrando as conclusões de múltiplos modelos.
O aprendizado de máquina (ML) continua a se expandir em diversos setores, desde finanças e medicina até desenvolvimento de aplicativos e segurança.
Um treinamento adequado dos modelos de ML é crucial para o sucesso em sua empresa ou função, e várias abordagens podem ser empregadas para atingir esse objetivo.
Neste artigo, vamos explorar o conceito de aprendizado em conjunto, sua relevância, aplicações práticas e técnicas.
Continue lendo!
O Que É Aprendizado em Conjunto?
No contexto do aprendizado de máquina e estatística, o termo “conjunto” refere-se a métodos que geram várias hipóteses através de um aprendizado base comum.
O aprendizado em conjunto é uma metodologia que envolve a criação e combinação estratégica de diversos modelos (como especialistas ou classificadores) com o objetivo de resolver um problema computacional ou melhorar a precisão das previsões.
Essa abordagem busca aprimorar o desempenho de um determinado modelo em tarefas como previsão, aproximação de funções, classificação, entre outros. Além disso, visa mitigar o risco de selecionar um modelo inadequado ou menos eficaz entre várias opções. Para alcançar um desempenho preditivo superior, são empregados diversos algoritmos de aprendizado.
A Importância do Aprendizado em Conjunto em ML
Em modelos de aprendizado de máquina, fontes como viés, variância e ruído podem introduzir erros. O aprendizado em conjunto pode ajudar a mitigar essas causas de erro, garantindo a estabilidade e precisão dos algoritmos de ML.
A seguir, as razões pelas quais o aprendizado em conjunto está sendo amplamente adotado em diversos cenários:
Escolhendo o Classificador Correto
O aprendizado em conjunto auxilia na escolha de um modelo ou classificador mais adequado, reduzindo os riscos associados a uma seleção inadequada de modelos.
Existem vários tipos de classificadores para diferentes problemas, como máquinas de vetores de suporte (SVM), perceptrons multicamadas (MLP), classificadores Naive Bayes, árvores de decisão, etc. Além disso, existem diferentes implementações de algoritmos de classificação. O desempenho pode variar dependendo dos dados de treinamento.
Em vez de selecionar apenas um modelo, o uso de um conjunto desses modelos e a combinação de seus resultados individuais pode ajudar a evitar a escolha de modelos menos eficientes.
Volume de Dados
Muitos métodos e modelos de ML podem não apresentar resultados eficazes se alimentados com dados insuficientes ou com um volume muito grande de dados.
O aprendizado em conjunto, por outro lado, pode operar eficazmente em ambos os cenários, tanto com volumes de dados pequenos quanto grandes.
- Com dados limitados, o bootstrap pode ser usado para treinar vários classificadores com amostras de dados distintas.
- Com grandes volumes de dados, que podem dificultar o treinamento de um único classificador, os dados podem ser divididos em subconjuntos menores.
Complexidade

Um único classificador pode não ser suficiente para lidar com problemas altamente complexos. As fronteiras de decisão que separam dados de diferentes classes podem ser intrincadas. Aplicar um classificador linear a uma fronteira não linear complexa pode ser ineficaz.
No entanto, ao combinar adequadamente um conjunto de classificadores lineares, é possível aprender uma determinada fronteira não linear. O classificador pode segmentar os dados em partições menores e mais fáceis de aprender, com cada classificador aprendendo uma partição mais simples. Em seguida, diferentes classificadores são combinados para gerar uma aproximação da fronteira de decisão.
Estimativa de Confiança
No aprendizado em conjunto, uma métrica de confiança é atribuída a uma decisão tomada por um sistema. Se a maioria dos classificadores concordar com uma decisão, o resultado pode ser considerado como uma decisão de alta confiança.
Por outro lado, se metade dos classificadores discordar da decisão, a confiança da decisão é considerada baixa.
É importante observar que confiança alta ou baixa não garante que a decisão esteja correta. No entanto, há uma probabilidade maior de uma decisão de alta confiança estar correta se o conjunto for devidamente treinado.
Precisão com Fusão de Dados
A combinação estratégica de dados de múltiplas fontes pode aumentar a precisão das decisões de classificação, superando a precisão obtida com uma única fonte de dados.
Como Funciona o Aprendizado em Conjunto?
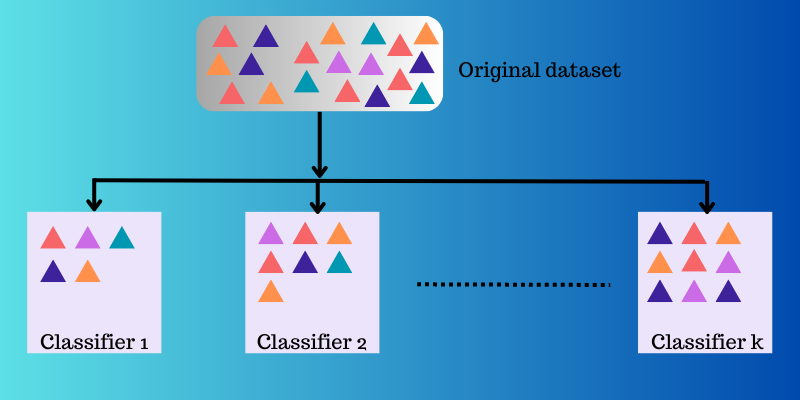
O aprendizado em conjunto emprega várias funções de mapeamento aprendidas por diferentes classificadores e as combina para criar uma única função de mapeamento.
Um exemplo ilustrativo de como o aprendizado em conjunto funciona:
Imagine que você está desenvolvendo um aplicativo de comida para usuários finais. Para garantir uma experiência de usuário de alta qualidade, você busca coletar feedback sobre problemas, lacunas, erros, bugs, etc.
Você pode obter opiniões de familiares, amigos, colegas de trabalho e outros contatos sobre suas preferências alimentares e experiências com pedidos de comida online. Além disso, você pode lançar seu aplicativo em versão beta para coletar feedback em tempo real.
Essencialmente, você está combinando várias perspectivas e opiniões para aprimorar a experiência do usuário.
O aprendizado em conjunto e seus modelos operam de maneira semelhante. Ele emprega um conjunto de modelos e os combina para gerar uma saída final, aprimorando a precisão e o desempenho preditivo.
Técnicas Básicas de Aprendizado em Conjunto
#1. Modo
O “modo” é o valor mais frequente em um conjunto de dados. No aprendizado em conjunto, os profissionais de ML utilizam vários modelos para gerar previsões para cada ponto de dado. Essas previsões são consideradas votos individuais, e a previsão com mais votos é considerada a previsão final. O modo é mais utilizado em problemas de classificação.
Exemplo: Se quatro pessoas avaliarem seu aplicativo com nota 4 e uma pessoa avaliar com nota 3, o modo seria 4, pois essa é a nota mais frequente.
#2. Média/Média
Nessa técnica, os profissionais consideram todas as previsões do modelo e calculam sua média para obter a previsão final. A média é utilizada principalmente em problemas de regressão, cálculo de probabilidades em problemas de classificação e muito mais.
Exemplo: No exemplo anterior, onde quatro pessoas avaliaram o aplicativo com 4 e uma com 3, a média seria (4+4+4+4+3)/5 = 3,8.
#3. Média Ponderada
Nesse método, pesos diferentes são atribuídos a modelos distintos para gerar uma previsão. O peso alocado representa a relevância de cada modelo.
Exemplo: Imagine que cinco pessoas forneceram feedback sobre seu aplicativo. Três são desenvolvedores de aplicativos, e duas não possuem experiência em desenvolvimento. O feedback dos três desenvolvedores terá mais peso do que o das outras duas pessoas.
Técnicas Avançadas de Aprendizado em Conjunto
#1. Bagging
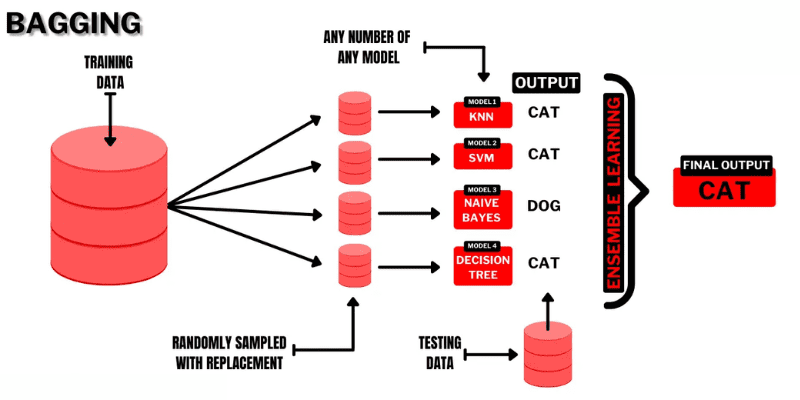
Bagging (Bootstrap AGGregatING) é uma técnica de aprendizado em conjunto simples e intuitiva que apresenta um bom desempenho. Como o nome sugere, é uma combinação de “bootstrap” e “agregação”.
Bootstrapping é um método de amostragem no qual subconjuntos de observações são criados a partir de um conjunto de dados original com substituição. O tamanho do subconjunto é igual ao tamanho do conjunto de dados original.
 Fonte: programador Buggy
Fonte: programador Buggy
No bagging, os subconjuntos ou “sacos” são usados para entender a distribuição do conjunto completo. No entanto, os subconjuntos podem ser menores que o conjunto original. Esse método utiliza um único algoritmo de ML. O objetivo é combinar resultados de diferentes modelos para obter um resultado generalizado.
Como o bagging funciona:
- Vários subconjuntos são gerados do conjunto original com observações selecionadas por substituição. Esses subconjuntos são usados para treinar modelos ou árvores de decisão.
- Um modelo fraco ou base é criado para cada subconjunto. Os modelos operam independentemente e em paralelo.
- A previsão final é feita combinando as previsões de cada modelo usando estatísticas como média, votação, etc.
Algoritmos populares de bagging:
- floresta aleatória
- árvores de decisão ensacadas
O bagging ajuda a minimizar erros de variância em árvores de decisão.
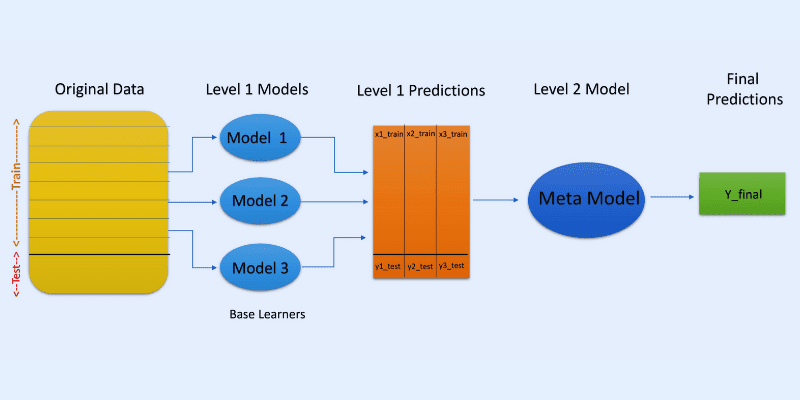
#2. Empilhamento
 Fonte da imagem: OpenGenus IQ
Fonte da imagem: OpenGenus IQ
No empilhamento ou generalização empilhada, as previsões de diferentes modelos são usadas para criar um novo modelo para previsões no conjunto de teste.
O empilhamento envolve a criação de subconjuntos de dados bootstrap para treinar modelos, semelhante ao bagging. No entanto, a saída dos modelos é usada como entrada para outro classificador, um metaclassificador, para a previsão final das amostras.
O uso de duas camadas de classificadores é para determinar se os conjuntos de dados de treinamento foram aprendidos corretamente. Uma abordagem comum é de duas camadas, mas mais camadas podem ser usadas.
Por exemplo, você pode usar de 3 a 5 modelos na primeira camada e um único modelo na segunda camada. A camada dois combina as previsões obtidas da primeira camada para gerar a previsão final.
Além disso, qualquer modelo de aprendizado de ML pode ser usado para agregar previsões, embora modelos lineares como regressão linear e regressão logística sejam comuns.
Algoritmos populares de ML no empilhamento:
- Misturando
- Superconjunto
- Modelos empilhados
Observação: A combinação usa um conjunto de validação ou validação do conjunto de dados de treinamento para previsões. Ao contrário do empilhamento, a combinação envolve previsões feitas apenas a partir do holdout.
#3. Boosting
Boosting é um método iterativo de aprendizado em conjunto que ajusta o peso de uma observação com base em sua classificação anterior. O objetivo de cada modelo subsequente é corrigir os erros do modelo anterior.
Se uma observação for classificada incorretamente, o boosting aumenta o peso dessa observação.
No boosting, os profissionais treinam o primeiro algoritmo em um conjunto de dados completo. Em seguida, constroem algoritmos de ML subsequentes usando resíduos do algoritmo de boosting anterior. Observações incorretamente previstas têm mais peso.
Como funciona o boosting:
- Um subconjunto é gerado do conjunto original. Cada ponto de dado tem os mesmos pesos inicialmente.
- Um modelo base é criado no subconjunto.
- A previsão é feita no conjunto de dados completo.
- Os erros são calculados com valores reais e previstos.
- Observações incorretamente previstas têm mais peso.
- Um novo modelo é criado, e a previsão final é feita, tentando corrigir erros anteriores. Vários modelos são criados da mesma maneira, corrigindo erros anteriores.
- A previsão final é feita com o modelo final, que é a média ponderada de todos os modelos.
Algoritmos populares de boosting:
- Cat Boost
- Light GBM
- AdaBoost
O boosting gera previsões superiores e reduz erros devido ao viés.
Outras Técnicas de Conjunto

Mistura de especialistas: Treina vários classificadores e combina suas saídas com uma regra linear geral. Os pesos das combinações são determinados por um modelo treinável.
Voto majoritário: Envolve a escolha de um classificador ímpar e calcula previsões para cada amostra. A classe com a maior quantidade de votos de um conjunto de classificadores será a classe predita do conjunto. É utilizada para resolver problemas como classificação binária.
Regra Max: Utiliza distribuições de probabilidade de cada classificador e emprega confiança para fazer previsões. É utilizada em problemas de classificação multiclasse.
Aplicações Práticas do Aprendizado em Conjunto
#1. Detecção de Rosto e Emoção
O aprendizado em conjunto emprega técnicas como análise de componente independente (ICA) para detecção de rosto.
O aprendizado em conjunto também é usado para detectar emoções através da análise da fala e detecção de emoções faciais.
#2. Segurança
Detecção de Fraudes: O aprendizado em conjunto aumenta o poder da modelagem de comportamento normal, sendo eficaz na detecção de atividades fraudulentas em sistemas bancários e de cartões de crédito, fraudes em telecomunicações, lavagem de dinheiro, etc.

DDoS: Ataques de negação de serviço distribuída (DDoS) são graves para ISPs. Classificadores de conjunto podem reduzir a detecção de erros e distinguir ataques de tráfego genuíno.
Detecção de Intrusão: O aprendizado em conjunto pode ser usado em ferramentas de detecção de intrusão para detectar códigos intrusos, monitorar redes, encontrar anomalias, etc.
Detecção de Malware: O aprendizado em conjunto é eficaz na detecção e classificação de malware, como vírus, worms, ransomware, cavalos de Tróia e spyware, utilizando técnicas de aprendizado de máquina.
#3. Aprendizado Incremental
No aprendizado incremental, um algoritmo de ML aprende a partir de novos conjuntos de dados, mantendo o aprendizado anterior, mas sem acessar os dados anteriores. Sistemas de conjunto são usados no aprendizado incremental para aprender um classificador adicional em cada conjunto de dados à medida que se tornam disponíveis.
#4. Medicina
Classificadores de conjunto são úteis em diagnósticos médicos, como a detecção de distúrbios neurocognitivos, como Alzheimer, usando dados de ressonância magnética e classificação da citologia cervical. Além disso, são aplicados em proteômica, neurociência e outras áreas.
#5. Sensoriamento Remoto
Detecção de Mudanças: Classificadores de conjunto são usados para detecção de mudanças através de métodos como média bayesiana e votação por maioria.
Mapeamento da Cobertura da Terra: Métodos como boosting, árvores de decisão, análise de componentes principais do kernel (KPCA) são usados para detectar e mapear a cobertura da terra.
#6. Finanças
A precisão é crucial em finanças. O aprendizado em conjunto pode analisar mudanças no mercado de ações, detectar manipulações de preços de ações e muito mais.
Recursos Adicionais de Aprendizado

#1. Métodos de Conjunto para Aprendizado de Máquina
Este livro ajuda a aprender e implementar métodos de aprendizado em conjunto.
#2. Métodos Ensemble: Fundamentos e Algoritmos
Este livro apresenta fundamentos e algoritmos de aprendizado em conjunto e suas aplicações no mundo real.
#3. Aprendizado em Conjunto
Oferece uma introdução a um método de conjunto unificado, desafios e aplicações.
#4. Ensemble Machine Learning: Métodos e Aplicações
Abrange técnicas avançadas de aprendizado em conjunto.
Conclusão
Esperamos que você tenha agora uma compreensão do aprendizado em conjunto, seus métodos, aplicações e benefícios. O aprendizado em conjunto pode ajudar a resolver muitos desafios da vida real, desde segurança e desenvolvimento de aplicativos até finanças, medicina e outros. Suas aplicações estão se expandindo e provavelmente haverá mais desenvolvimentos no futuro próximo.
Você também pode explorar ferramentas para geração de dados sintéticos para treinar modelos de aprendizado de máquina.