
As métricas ágeis são medições usadas para rastrear o progresso e o sucesso de uma equipe de projeto ágil.
As métricas, quando definidas da maneira certa, fornecem informações sobre o desempenho, a qualidade, a eficiência do teste ou a eficácia geral da equipe e como ela evolui ao longo do tempo.
O objetivo final das métricas ágeis é ajudar as equipes a identificar áreas de melhoria e tomar decisões baseadas em dados que levarão a melhores produtos à medida que a equipe progride.
Na maioria das vezes, as empresas definem métricas que são métricas de vaidade ou números brutos, crescendo da esquerda para a direita. Eles podem parecer bons em alguns painéis, mas geralmente são inúteis para a própria equipe.
O objetivo deles não é ajudar a equipe de forma alguma, mas sim preencher alguns relatórios para a liderança e depois concluir com algumas decisões estratégicas. Infelizmente, é então a equipe que não entende por que essa decisão específica existe.
Em uma cerca para atender a essas métricas erradas, as equipes falsificam seus próprios processos para fazer com que as métricas pareçam boas. Mas a produção da equipe não está melhorando em nada.
últimas postagens
Métricas básicas
Há muitas maneiras de segregar as métricas. Talvez o mais básico seja de cima para baixo e de baixo para cima.
➡️ Top-down significa: nós, líderes, criaremos para você as métricas que queremos que todos vocês conheçam, e seu objetivo final é se encaixar nas áreas verdes delas. Não nos importamos se você – uma equipe gosta deles ou não; é isso que queremos rastrear.
➡️ Bottom-up significa: nós – a equipe precisa melhorar nessas áreas e, para isso, precisamos focar nessas coisas. Assim, definimos métricas que nos permitirão acompanhar o progresso da equipe em direção aos nossos objetivos, e podemos demonstrar para você – liderança exatamente como ela melhorou nosso trabalho ao longo do tempo.
Definição de boa métrica
Então, o que qualquer boa métrica deve conter, ou como descrevê-la?
A propriedade mais importante é a mudança de comportamento. Isso significa que toda vez que você olha para o resultado da métrica, fica claro o que deve mudar dentro da equipe para obter melhorias.
Então deve ser simples. Se você não pode explicá-lo com algumas frases simples para que todos os ouvintes relevantes possam entender, então algo não está muito bom.
Uma boa métrica é comparável ao longo do tempo. Tire um instantâneo dos resultados de uma vez e faça-o novamente algum tempo depois. Coloque-os lado a lado. Se você não pode comparar os dois resultados entre si, deve pensar duas vezes nessa métrica.
Por fim, melhor do que números puros, sempre que possível, faça disso uma proporção ou porcentagem. “10 novos defeitos abertos durante o sprint” não dirá muito. Depende se você normalmente tem um ou 100.
Aqui estão alguns exemplos de métricas que acredito atender a todos esses critérios de definição. Eles têm equipes especificamente ágeis em mente. Existem três categorias principais: desempenho, qualidade e moral.
Categorias de métricas
Métricas de desempenho
O objetivo é entender o quão bom é o time em acompanhar as histórias cometidas dentro de um sprint. Avaliar se o supercomprometimento não é normal ou se as histórias de transição são um padrão de sprint para sprint.
Da perspectiva do desempenho ágil, a equipe deve se esforçar para entregar o conteúdo do sprint planejado com o qual a equipe se comprometeu no início do sprint.
Isso não significa que não devemos ser flexíveis na troca de histórias durante o sprint. Mas deve ser sempre uma negociação levando a uma troca, não a um acréscimo. A capacidade da equipe não aumentará apenas porque alguém adicionou novas histórias dentro do sprint.
Trazemos essa métrica para ficar atento a esses casos e orientar todos do time a proteger a capacidade que têm para o sprint.
Isso aumenta a confiabilidade e a previsibilidade da equipe.
#1. Capacidade de Sprint vs. Pontos de História Entregues
Assista ao histórico da capacidade do sprint em relação ao conteúdo de pontos de história (SP) entregues ao longo dos sprints.
- Pequenos desvios de sprint para sprint são bons. Grandes saltos em qualquer direção sinalizam que algo está errado.
- Capacidade Total de Sprint – o dia disponível de um membro da equipe adiciona um à Capacidade Total. Por exemplo, se a equipe tiver 10 pessoas e todas estiverem disponíveis no sprint completo, a capacidade total do sprint será de 100.
Verifique a capacidade do sprint em relação ao SP concluído de sprint para sprint. Se a equipe estiver (durante o planejamento) se comprometendo com uma quantidade significativamente maior de SP do que a equipe normalmente pode concluir, aumente esse risco para a equipe.
O objetivo deve ser ter um SP planejado total igual ou menor que o SP total concluído por sprint.
Você ainda pode ter mais SP concluído do que planejado se a equipe concluiu (no final do sprint) todas as histórias planejadas e a equipe ainda tem a capacidade de pegar a história adicional.
- Se a equipe entrega repetidamente menos SP do que o planejado, a equipe precisa alterar seu planejamento e levar menos SP para o próximo sprint.
Ferramentas como monday.com, Atlassian Jira ou Asana fornecem uma maneira simples de salvar e extrair pontos de história para cada história nos sprints. Eles podem até gerar isso para você automaticamente após o planejamento de cada sprint.
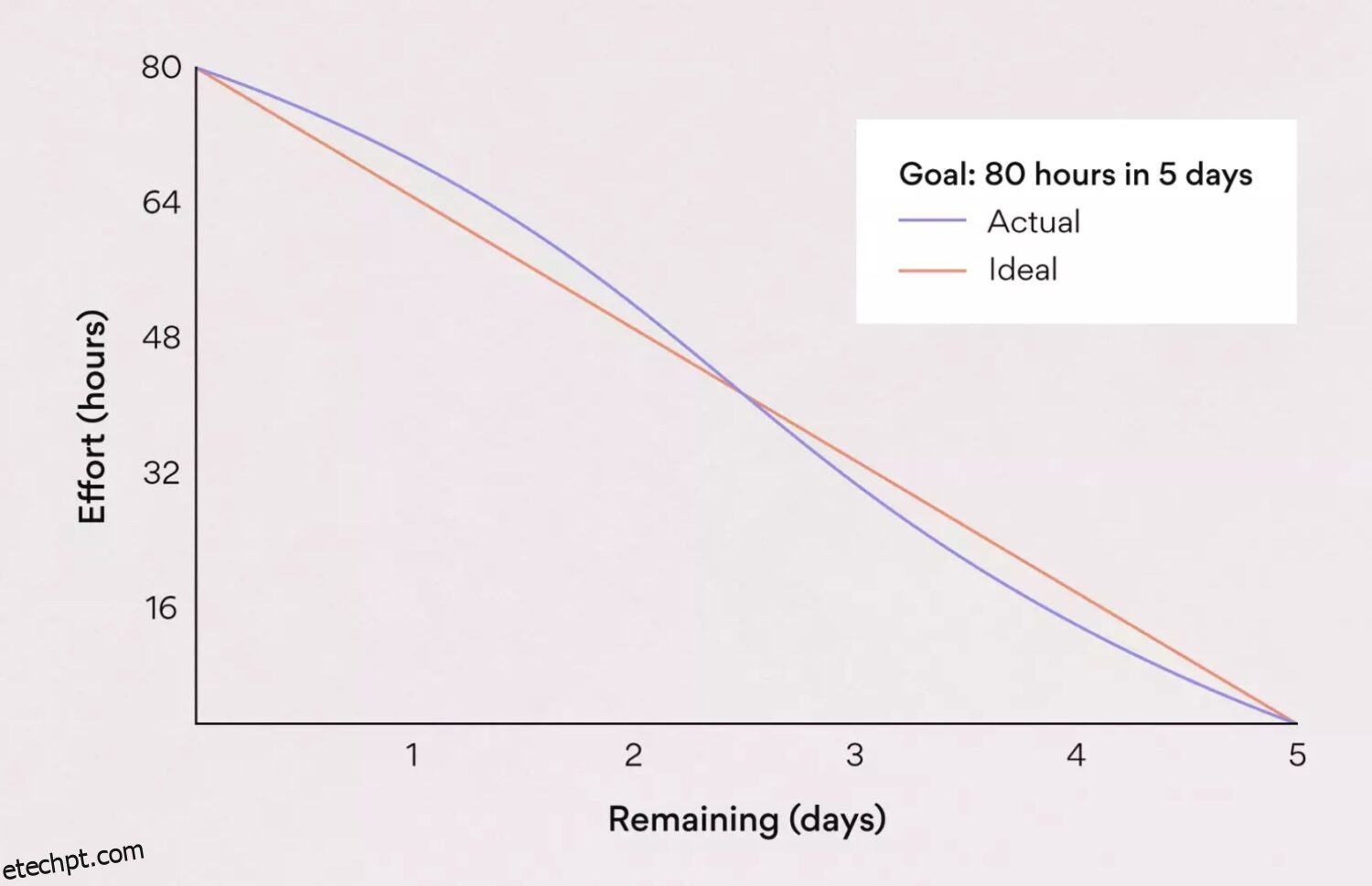
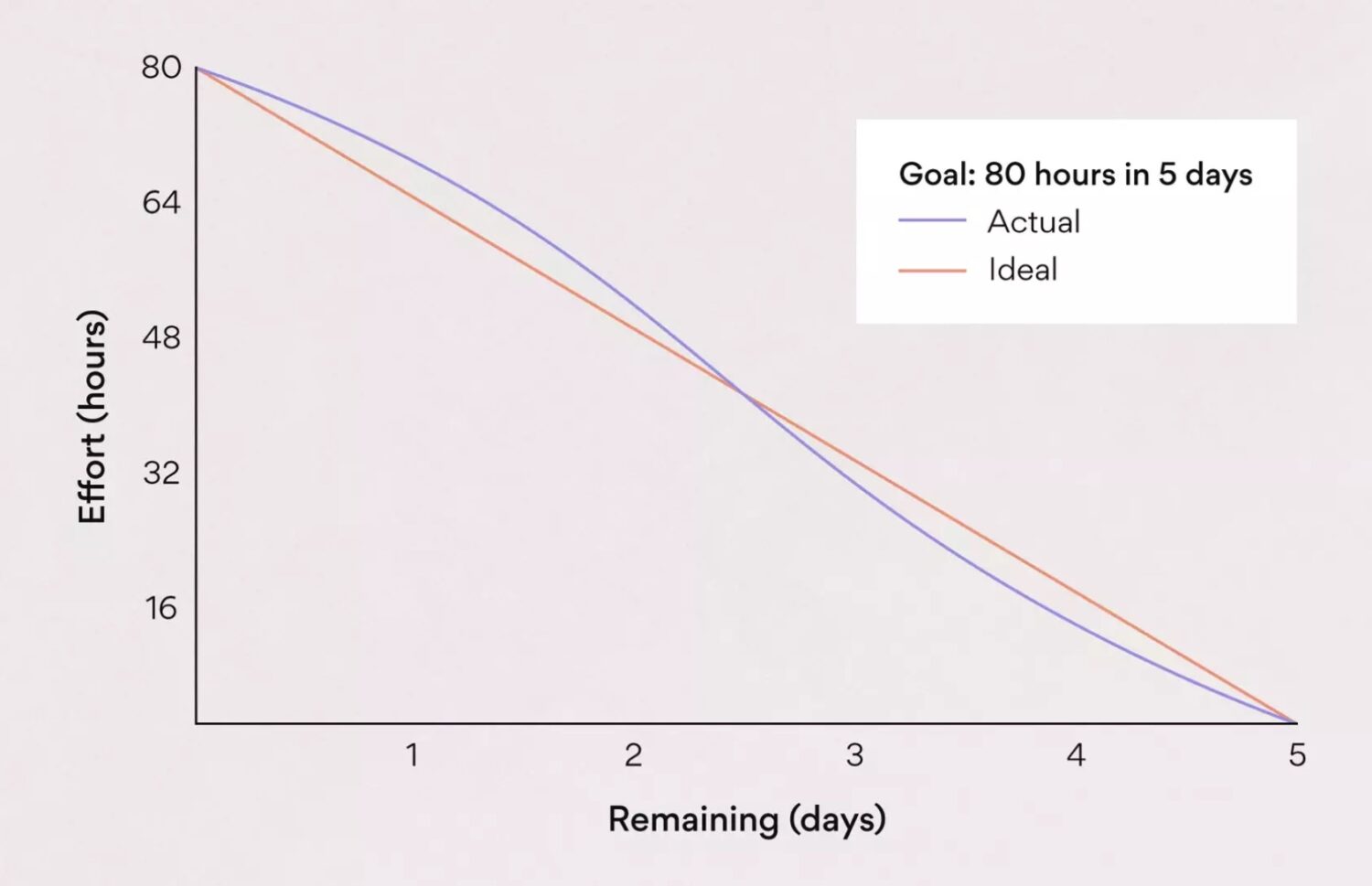
#2. Gráfico Burndown
Esta é uma das métricas que provavelmente a maioria das equipes scrum tem em algum lugar escondido no painel. Concordo que isso pode até parecer uma coisa inútil de se ter. A equipe raramente leva isso em consideração. Em vez disso, o gerente gosta de apontar como as histórias parecem de alto nível e como elas não estão progredindo bem (já que estão todas abertas durante todo o sprint).
O que eu gostaria de destacar é que, apesar disso, você, como equipe, deve verificar o gráfico de burndown para seu próprio bem. Se todas as histórias forem abertas durante todo o sprint e fechadas apenas no último dia do sprint, isso gera incerteza dentro da equipe e quanto ao cumprimento dos objetivos do sprint.
- Revise seu quadro de sprint para histórias concluídas.
- Verifique com a equipe para determinar por que pequenas histórias ainda estão abertas, mesmo que tenham começado no início do sprint.
- Trabalhe com a equipe para construir essa mentalidade, não para manter as histórias abertas por mais tempo do que o necessário.
- O gráfico de burndown ideal geralmente é um estado teórico. No entanto, quanto mais nos aproximamos disso, mais eficaz é o manuseio da história.
Ferramentas de gerenciamento ágil como o Asana podem gerar um gráfico de burndown para você automaticamente para cada sprint.
 Fonte: asana.com
Fonte: asana.com
#3. Conclusão da Meta do Sprint
Isso rastreia a porcentagem de metas de sprint que você concluiu durante cada sprint.
Você documenta os Objetivos do Sprint separadamente, por exemplo, na página do Confluence / Jira, para cada sprint. O status deve ser atribuído se eles foram atendidos ou não dentro do sprint.
Mesmo que a equipe não conclua todas as histórias dentro de um sprint, eles ainda podem atingir a meta do Sprint (por exemplo, faltam apenas histórias secundárias).
Devemos almejar a conclusão de 100% das Metas do Sprint a cada sprint. Se não for esse o caso, descubra o que a equipe está impedindo.
- Se forem muitos tópicos paralelos em cada sprint, reduza a quantidade deles.
- Se muitas histórias ad hoc forem adicionadas durante o sprint, reduza isso para que não afete os objetivos originais do sprint.
- Se as metas do sprint forem muito grandes ou muito desafiadoras, torne-as mais simples. De qualquer forma, não faz sentido ter grandes objetivos de sprint e não cumpri-los até o final do sprint.
Métricas de qualidade de código
Isso deve rastrear a qualidade do código ao longo do tempo. Isso ajuda a manter processos de desenvolvimento saudáveis e diminui o tempo gasto na resolução de problemas. Ou o tempo ocioso do desenvolvedor causado pela espera na execução do código durante as atividades de desenvolvimento e teste.
 Fonte: azuredevopslabs.com
Fonte: azuredevopslabs.com
#1. Testes Automatizados
Crie testes de unidade automatizados pelos desenvolvedores para cada alteração que eles fizerem.
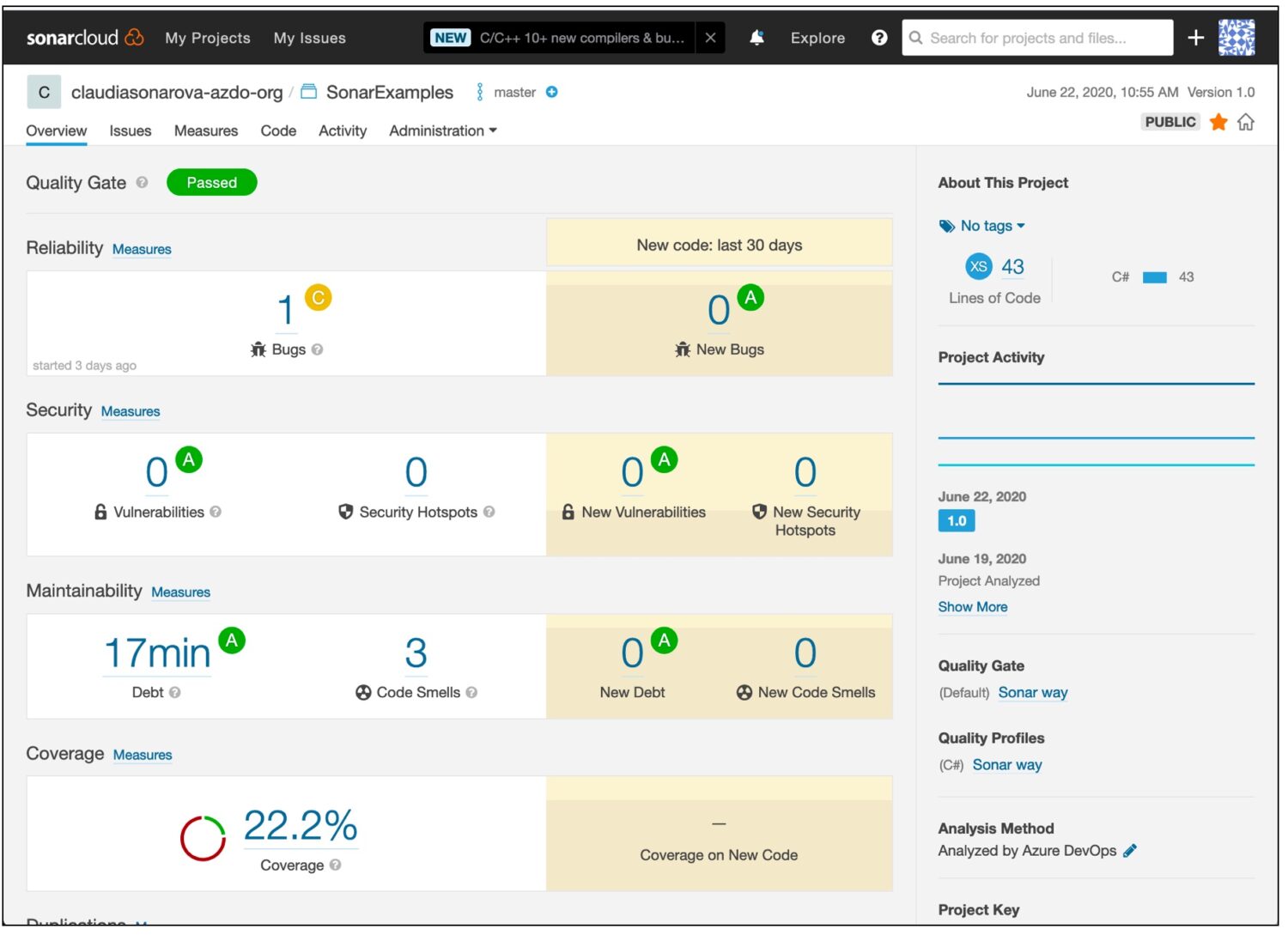
- Meça a cobertura de código por testes automatizados – use Azure Pipelines ou SonarCloud para executar os testes. Apontar para 85% de cobertura. Acima de 90% não é realmente eficiente.
- Certifique-se de que a criação do teste de unidade automatizado faça parte da definição de concluído para as novas histórias.
- Acompanhe a cobertura de teste de código antigo como parte das histórias de dívidas técnicas na lista de pendências.
#2. Complexidade do código
Avalie as complicações desnecessárias que o código está obtendo ao longo do tempo e corrija-o ativamente por histórias de dívidas técnicas. Ou impeça que aconteçam, se possível.
Defina padrões de código e diretrizes para educar os desenvolvedores a segui-los. Certifique-se de que eles sigam as regras de codificação para minimizar o aumento irracional na complexidade do código. Atualizado regularmente as diretrizes com base na experiência da equipe.
Identificar Code Smells – indicadores de possíveis problemas no código, como código duplicado, métodos longos e variáveis não utilizadas.
As revisões por pares devem garantir que os padrões de código sejam aplicados ao código recém-criado.
Use ferramentas como painéis e relatórios do Azure Ado ou SonarCloud para descobrir problemas de código.
#3. Etapas manuais na implantação
Acompanhe quantas etapas manuais a equipe precisa executar para liberar o código em ambientes de teste ou produção.
- Nosso objetivo será alcançar o 0 aqui ao longo do tempo.
- Crie histórias de dívidas técnicas, se necessário, para trazer o pipeline de implantação/liberação até o roteiro de automação. Reduza gradualmente as etapas manuais restantes nos processos de sprint a sprint.
Métricas de moral
Essa é uma métrica para rastrear como a equipe se sente em relação ao seu trabalho e aos processos com os quais lida diariamente.
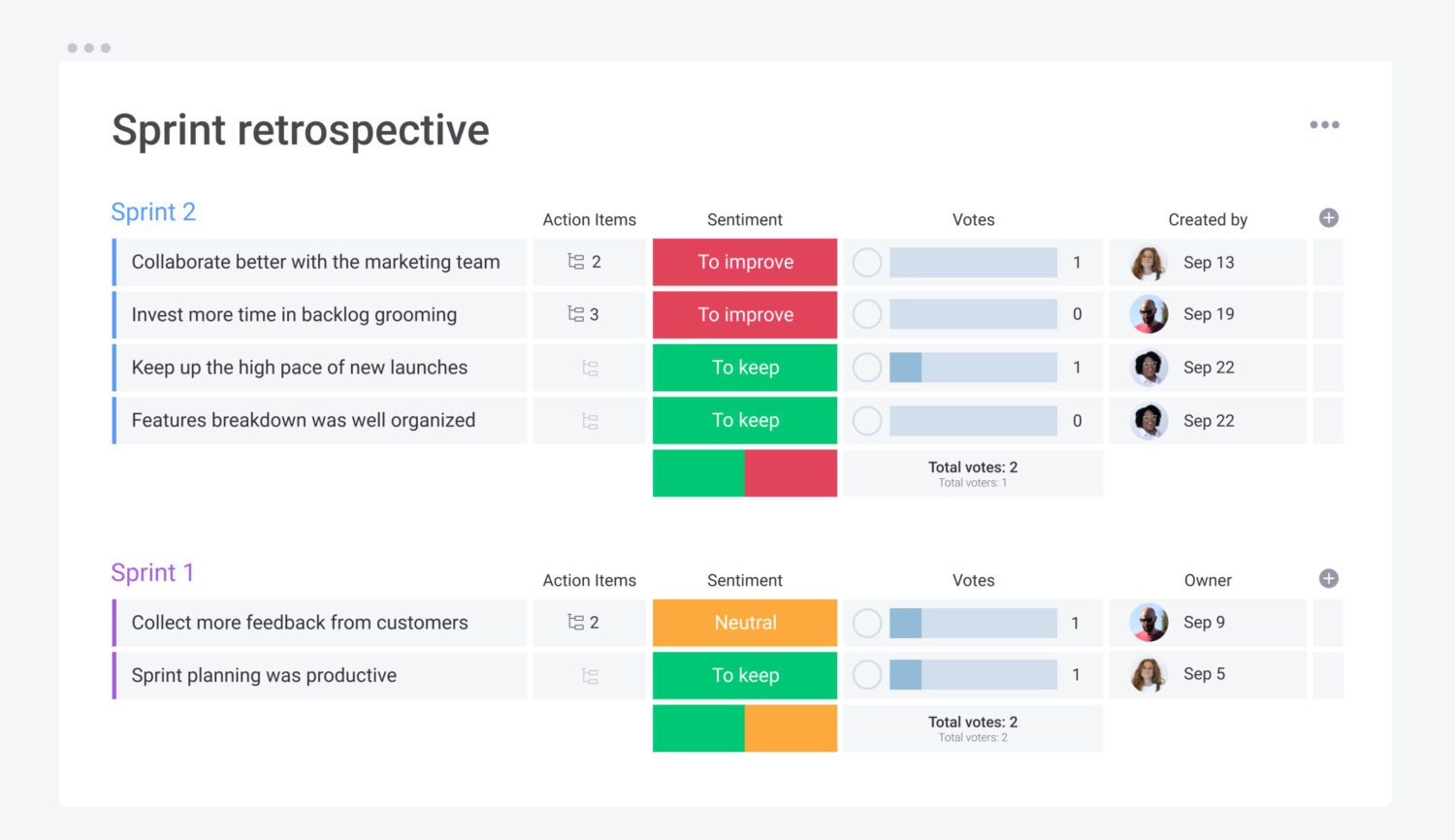
#1. Cumprimento Retrospectivo do Sprint
Você pode acompanhar quantos itens de ação foram realmente concluídos no próximo sprint.
- O Scrum Master deve coletar os resultados da reunião Retrospectiva nas páginas da equipe para rastrear os itens de ação acordados.
- A equipe então acompanharia o progresso.
- O gerenciamento de projetos pode então revisar se os itens de ação estão progredindo ou o que impede a equipe de concluí-los. Em seguida, altere o ambiente para permitir que a equipe progrida nos itens de ação acordados.
Pelo menos 33% ou 1 (dependendo do que for maior) dos itens de ação do sprint anterior serão adotados nos próximos sprints.
Se for menor que isso, são necessárias mudanças para permitir que a equipe implemente as melhorias acordadas.
As ferramentas de gerenciamento de projetos contêm modelos prontos para uso para atividades de retrospectiva de sprint. Aqui está um exemplo de monday.com:
 Fonte: monday.com
Fonte: monday.com
#2. Colaboração em equipe
Programação de par de pistas.
- Forme um casal natural por história para trabalharem juntos, compartilhando observação, conhecimento e sucesso. Crie subtarefas em histórias pertencentes a diferentes membros da equipe.
Rastreie revisões de código de iniciativas de colegas.
- Os colegas são solicitados ou agem proativamente para revisar a saída da história de outra pessoa.
A métrica pode ser extraída do quadro monday.com/Asana/Jira das subtarefas.
Pelo menos 50% das histórias do sprint devem ser compartilhadas pelos membros da equipe. Se for menor, investigue os motivos e tome ações onde fizer sentido.
Para revisões voluntárias por pares, acompanhe as histórias com subtarefas dedicadas. No começo, 20% das histórias de código revisadas dessa maneira é um bom começo. Gradualmente, ao longo dos sprints, você deve encorajar e motivar a equipe a trabalhar de forma mais colaborativa e aumentá-la para 50% das histórias de código por sprint como meta.
#3. Dívida Técnica vs. Novas Histórias de Funcionalidade
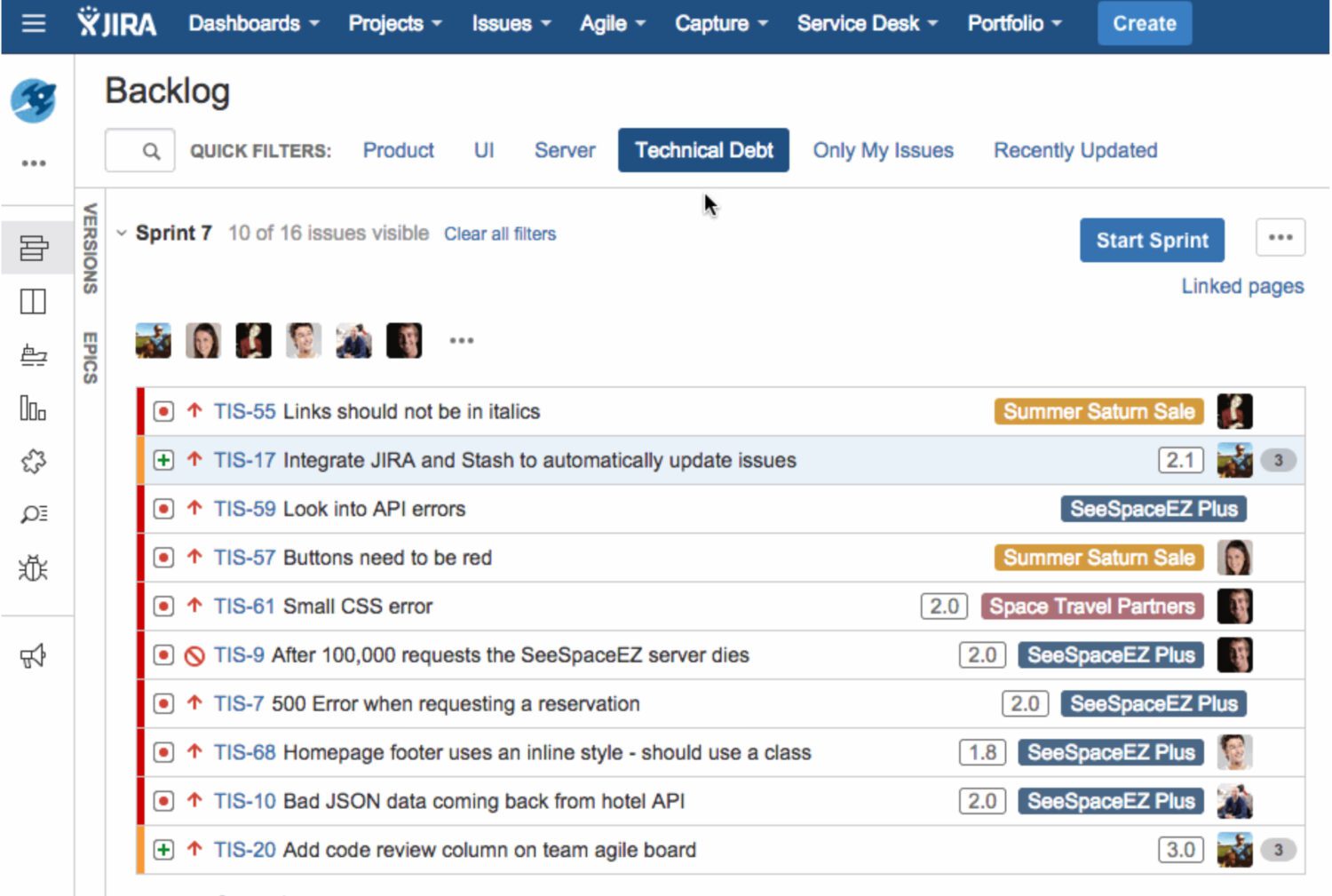 Fonte: atlassian.com
Fonte: atlassian.com
Dar à equipe a oportunidade de resolver suas próprias histórias de dívidas aumentará a satisfação da equipe com seu trabalho.
- Pelo contrário, o acúmulo de dívidas tecnológicas sem um plano para resolvê-las progressivamente irá desmotivar a equipe ao longo do tempo. E a solução se tornará mais instável, complexa e difícil de resolver sem retrabalho substancial.
A equipe sabe melhor o que não funciona bem com a solução, mesmo que as partes interessadas ou os usuários finais não percebam. Essas histórias têm o maior impacto na própria equipe de desenvolvimento. Para as partes interessadas, eles podem ser invisíveis. É por isso que é importante dar à equipe a chance de trabalhar em histórias que os ajudem a organizar as atividades de desenvolvimento.
O objetivo é rastrear quantas histórias de dívida técnica levantadas são resolvidas ao longo do tempo e se o acúmulo de tais histórias só cresce ou não.
A equipe pode rotular as histórias como TechDebt no backlog e dar a elas prioridade da equipe, para que possam ir para o topo e serem selecionadas em sprints.
Dependendo do estado do projeto e de quantas dívidas de tecnologia são identificadas no backlog, você pode querer garantir que o TechDebt backlog não cresça mais de 10% de sprint para sprint.
Priorize as histórias de dívidas de tecnologia e inclua-as nos sprints para manter o crescimento da carteira de dívidas de tecnologia sob controle, de modo que a equipe possa trabalhar nas histórias de dívidas de tecnologia de 10 a 20% do tempo de cada sprint.
Palavras Finais
Todo projeto eventualmente precisará de algumas métricas, seja porque a liderança quer tê-las ou porque a equipe decide medir seu próprio sucesso.
O melhor que você pode fazer é começar a construir sua biblioteca de métricas pronta para ser escolhida e usada; quanto antes melhor. E ao fazer isso, certifique-se de sempre buscar métricas de mudança de comportamento acima de tudo.
Em seguida, confira processos não saudáveis que podem arruinar seu sprint.