Atualmente, os sistemas computacionais geram diariamente milhões de registros de dados. Isso inclui desde as suas transações financeiras, passando por pedidos online, até os dados dos sensores do seu veículo. Para processar estes eventos de dados em fluxo contínuo e mover registros de forma segura entre diferentes sistemas empresariais, a solução ideal é o Apache Kafka.
O Apache Kafka se apresenta como uma plataforma de código aberto para streaming de dados, capaz de lidar com mais de um milhão de registros por segundo. Além do seu alto desempenho, o Apache Kafka oferece alta escalabilidade, disponibilidade, baixa latência e armazenamento permanente de dados.
Empresas renomadas como LinkedIn, Uber e Netflix utilizam o Apache Kafka para processamento e streaming de dados em tempo real. Uma das maneiras mais simples de começar a utilizar o Apache Kafka é instalá-lo e executá-lo em sua máquina local. Isso não só permite que você observe o servidor Apache Kafka em ação, mas também possibilita a produção e o consumo de mensagens.
Com experiência prática na inicialização do servidor, criação de tópicos e escrita de código Java utilizando o cliente Kafka, você estará totalmente preparado para usar o Apache Kafka para satisfazer todas as suas necessidades de pipeline de dados.
Como baixar o Apache Kafka em sua máquina local
A versão mais recente do Apache Kafka pode ser baixada através do link oficial. O conteúdo baixado estará compactado no formato .tgz. Após o download, será necessário extrair os arquivos.
Se você utiliza Linux, abra seu terminal e navegue até a pasta onde o arquivo compactado do Apache Kafka foi baixado. Em seguida, execute o seguinte comando:
tar -xzvf kafka_2.13-3.5.0.tgz
Após a conclusão do comando, você notará que um novo diretório chamado kafka_2.13-3.5.0 foi criado. Para acessar este diretório, utilize o comando:
cd kafka_2.13-3.5.0
Agora, você pode listar o conteúdo do diretório utilizando o comando ls.
Para usuários do Windows, o processo é similar. Caso você não encontre o comando tar, pode utilizar um software de terceiros como o WinZip para abrir o arquivo.
Como iniciar o Apache Kafka em sua máquina local
Após baixar e extrair o Apache Kafka, chegou a hora de iniciar sua execução. Não há instaladores. Você pode começar a utilizá-lo diretamente através da linha de comando ou da janela do terminal.
Antes de prosseguir, certifique-se de que o Java 8+ esteja instalado em seu sistema, pois o Apache Kafka requer uma instalação Java em execução.
#1. Execute o servidor Apache Zookeeper
O primeiro passo é iniciar o Apache Zookeeper, que já vem incluso no pacote baixado. Este serviço é responsável por manter as configurações e fornecer sincronização para outros serviços.
Dentro do diretório onde você extraiu os arquivos, execute o seguinte comando:
Para usuários Linux:
bin/zookeeper-server-start.sh config/zookeeper.properties
Para usuários do Windows:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
O arquivo zookeeper.properties contém as configurações para a execução do servidor Apache Zookeeper. Nele, é possível configurar propriedades como o diretório onde os dados serão armazenados e a porta em que o servidor irá operar.
#2. Inicie o servidor Apache Kafka
Agora que o servidor Apache Zookeeper está em execução, é hora de iniciar o servidor Apache Kafka.
Abra um novo terminal ou janela de prompt de comando, navegue até o diretório onde os arquivos extraídos se encontram e execute o seguinte comando:
Para usuários Linux:
bin/kafka-server-start.sh config/server.properties
Para usuários do Windows:
bin/windows/kafka-server-start.bat config/server.properties
O seu servidor Apache Kafka agora está em execução. Caso deseje modificar a configuração padrão, você pode fazê-lo editando o arquivo server.properties. Os diferentes valores e suas explicações podem ser encontrados na documentação oficial.
Como usar o Apache Kafka em sua máquina local
Agora que os servidores Apache Zookeeper e Apache Kafka estão ativos, você está pronto para iniciar a produção e o consumo de mensagens em sua máquina local. Vamos aprender como criar o seu primeiro tópico, produzir sua primeira mensagem e consumi-la.
Quais são as etapas para criar um tópico no Apache Kafka?
Antes de criar seu primeiro tópico, vamos entender o que ele realmente significa. No Apache Kafka, um tópico representa um armazenamento de dados lógico que facilita o streaming de dados. Imagine-o como o canal por meio do qual os dados são transmitidos de um componente para outro.
Um tópico suporta múltiplos produtores e consumidores, permitindo que diversos sistemas escrevam e leiam de um mesmo tópico. Ao contrário de outros sistemas de mensagens, qualquer mensagem de um tópico pode ser consumida várias vezes. Além disso, você pode configurar o período de retenção das mensagens.
Por exemplo, imagine um sistema (produtor) que gera dados de transações bancárias, e outro sistema (consumidor) que recebe esses dados e envia notificações para os usuários. Para que essa comunicação seja possível, um tópico é necessário.
Abra um novo terminal ou janela de prompt de comando, navegue até o diretório onde os arquivos foram extraídos e execute o seguinte comando para criar um tópico chamado “transações”:
Para usuários Linux:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Para usuários do Windows:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
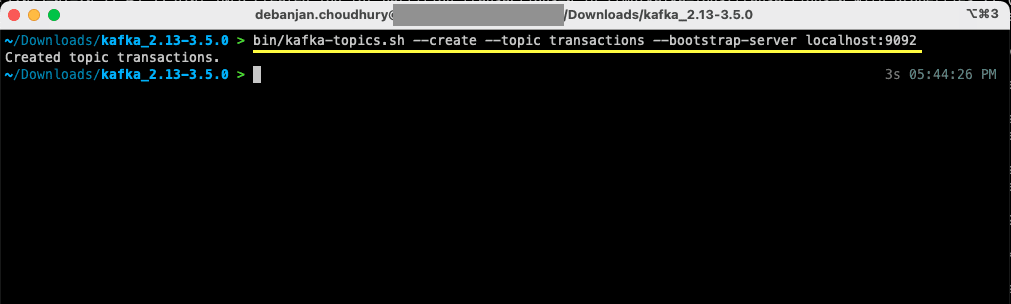
Seu primeiro tópico foi criado e você já pode começar a produzir e consumir mensagens.
Como produzir uma mensagem para o Apache Kafka?
Com o seu tópico do Apache Kafka pronto, agora você pode produzir a sua primeira mensagem. Abra um novo terminal ou janela de prompt de comando, ou utilize a mesma que usou para criar o tópico. Verifique se você está no diretório correto onde extraiu os arquivos. Utilize a seguinte linha de comando para produzir sua mensagem no tópico:
Para usuários Linux:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Para usuários do Windows:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Após executar o comando, você notará que o terminal ou janela de prompt de comando estará aguardando uma entrada. Digite sua primeira mensagem e pressione Enter.
> This is a transactional record for $100
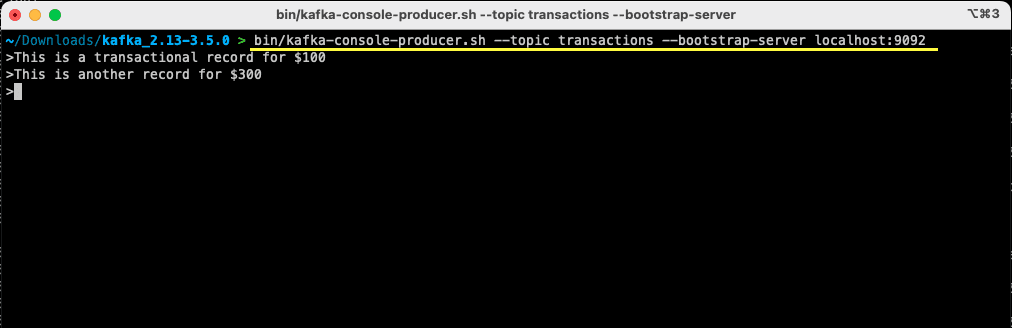
Você acabou de produzir a sua primeira mensagem para o Apache Kafka em sua máquina local. Agora você está pronto para consumir esta mensagem.
Como consumir uma mensagem do Apache Kafka?
Agora que seu tópico foi criado e você produziu uma mensagem, chegou o momento de consumir essa mensagem.
O Apache Kafka permite que diversos consumidores se conectem ao mesmo tópico. Cada consumidor pode fazer parte de um grupo de consumidores – um identificador lógico. Por exemplo, se dois serviços precisarem consumir os mesmos dados, eles podem ter grupos de consumidores diferentes.
No entanto, se você tiver duas instâncias do mesmo serviço, é recomendado evitar o consumo e processamento da mesma mensagem duas vezes. Nesse caso, ambos devem pertencer ao mesmo grupo de consumidores.
No terminal ou janela de prompt de comando, certifique-se de estar no diretório correto. Use o comando abaixo para iniciar o consumidor:
Para usuários Linux:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Para usuários do Windows:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

Você verá a mensagem que produziu anteriormente aparecer no seu terminal. Agora você utilizou o Apache Kafka para consumir a sua primeira mensagem.
O comando kafka-console-consumer recebe diversos argumentos. Vamos entender cada um deles:
- O argumento –topic especifica o tópico do qual você irá consumir.
- O argumento –from-beginning instrui o consumidor a começar a ler as mensagens a partir da primeira disponível.
- Seu servidor Apache Kafka é especificado através da opção –bootstrap-server.
- Adicionalmente, você pode definir o grupo de consumidores através do parâmetro –group.
- Caso um grupo de consumidores não seja especificado, ele será gerado automaticamente.
Com o consumidor do console em execução, você pode tentar produzir novas mensagens. Você verá que todas elas serão consumidas e aparecerão no seu terminal.
Agora que você criou seu tópico e produziu e consumiu mensagens com sucesso, vamos integrar tudo isso em uma aplicação Java.
Como criar produtor e consumidor Apache Kafka usando Java
Antes de começar, certifique-se de que o Java 8+ esteja instalado em sua máquina local. O Apache Kafka oferece sua própria biblioteca cliente que permite uma conexão perfeita. Se você estiver utilizando o Maven para gerenciar suas dependências, adicione a seguinte dependência ao seu pom.xml:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Você também pode baixar a biblioteca do Repositório Maven e adicioná-la ao seu classpath Java.
Com a biblioteca configurada, abra o editor de código de sua preferência. Vamos ver como iniciar o produtor e o consumidor usando Java.
Criar produtor Apache Kafka Java
Com a biblioteca kafka-clients instalada, você está pronto para começar a criar o seu produtor Kafka.
Vamos criar uma classe chamada SimpleProducer.java. Esta classe será responsável por produzir mensagens no tópico que você criou anteriormente. Dentro desta classe, você criará uma instância de org.apache.kafka.clients.producer.KafkaProducer. Posteriormente, você usará este produtor para enviar as suas mensagens.
Para criar o produtor Kafka, você precisará do host e da porta do seu servidor Apache Kafka. Como você o está executando em sua máquina local, o host será localhost. Dado que você não alterou as propriedades padrão ao inicializar o servidor, a porta será 9092. Observe o código abaixo para a criação do seu produtor:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Você notará que três propriedades estão sendo definidas. Vamos analisá-las rapidamente:
- O BOOTSTRAP_SERVERS_CONFIG permite definir onde o servidor Apache Kafka está em execução.
- O KEY_SERIALIZER_CLASS_CONFIG informa ao produtor qual formato usar para enviar as chaves das mensagens.
- O formato para enviar a mensagem propriamente dita é definido através da propriedade VALUE_SERIALIZER_CLASS_CONFIG.
Como você enviará mensagens de texto, ambas as propriedades são definidas para usar StringSerializer.class.
Para realmente enviar uma mensagem para o seu tópico, você precisa usar o método Producer.send() que recebe um ProducerRecord. O código a seguir fornece um método que enviará uma mensagem para o tópico e exibirá a resposta juntamente com o offset da mensagem:
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Com todo o código pronto, agora você pode enviar mensagens para o seu tópico. Você pode usar um método main para testar isso, conforme apresentado no código abaixo:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
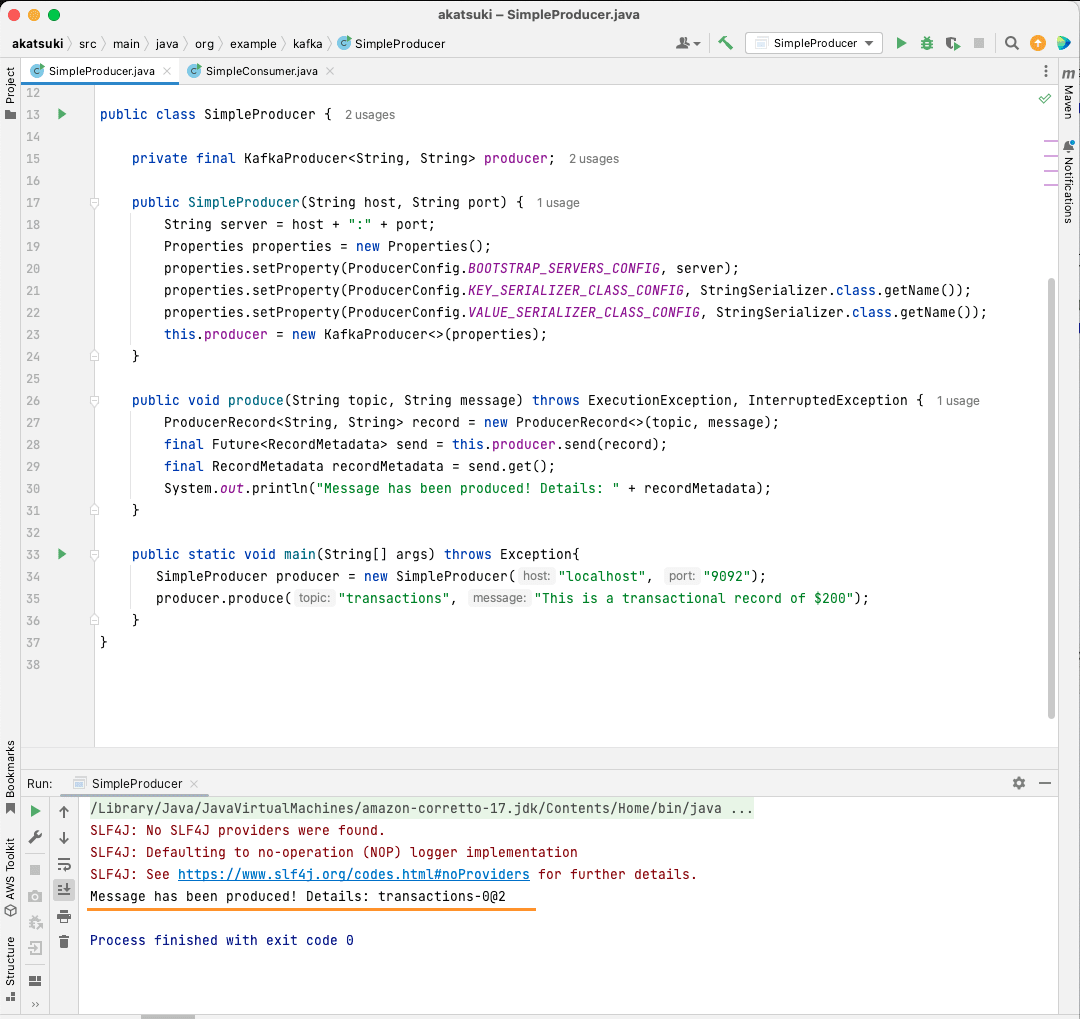
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
Neste código, você está criando um SimpleProducer que se conecta ao seu servidor Apache Kafka em sua máquina local. Ele usa internamente o KafkaProducer para produzir mensagens de texto no seu tópico.
Criar consumidor Apache Kafka Java
Agora é o momento de criar um consumidor Apache Kafka utilizando o cliente Java. Crie uma classe chamada SimpleConsumer.java. Em seguida, crie um construtor para essa classe que inicializa o org.apache.kafka.clients.consumer.KafkaConsumer. Para criar o consumidor, você precisará do host e da porta onde o servidor Apache Kafka está em execução. Adicionalmente, você precisa do grupo de consumidores e do tópico do qual deseja consumir. Utilize o seguinte código:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
De forma similar ao Kafka Producer, o Kafka Consumer também recebe um objeto Properties. Vamos analisar as propriedades:
- BOOTSTRAP_SERVERS_CONFIG informa ao consumidor onde o servidor Apache Kafka está em execução.
- O grupo de consumidores é especificado através do GROUP_ID_CONFIG.
- Quando o consumidor inicia, o AUTO_OFFSET_RESET_CONFIG permite que você especifique de qual ponto do histórico você deseja começar a consumir as mensagens.
- KEY_DESERIALIZER_CLASS_CONFIG informa ao consumidor o tipo da chave da mensagem.
- VALUE_DESERIALIZER_CLASS_CONFIG informa o tipo da mensagem propriamente dita.
Como você irá consumir mensagens de texto, as propriedades do desserializador são definidas como StringDeserializer.class.
Agora, você irá consumir as mensagens do seu tópico. Para simplificar, assim que a mensagem for consumida, você irá imprimi-la no console. Observe como isso pode ser feito utilizando o seguinte código:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Este código irá continuar verificando o tópico. Ao receber qualquer registro, a mensagem será impressa. Teste o seu consumidor em ação utilizando um método main. Você irá iniciar uma aplicação Java que irá continuar consumindo o tópico e exibindo as mensagens. Pare a aplicação para finalizar o consumidor.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Ao executar o código, você notará que ele irá consumir não só a mensagem produzida pelo seu produtor Java, mas também aquelas produzidas através do Console Producer. Isso ocorre porque a propriedade AUTO_OFFSET_RESET_CONFIG foi definida como “earliest”.
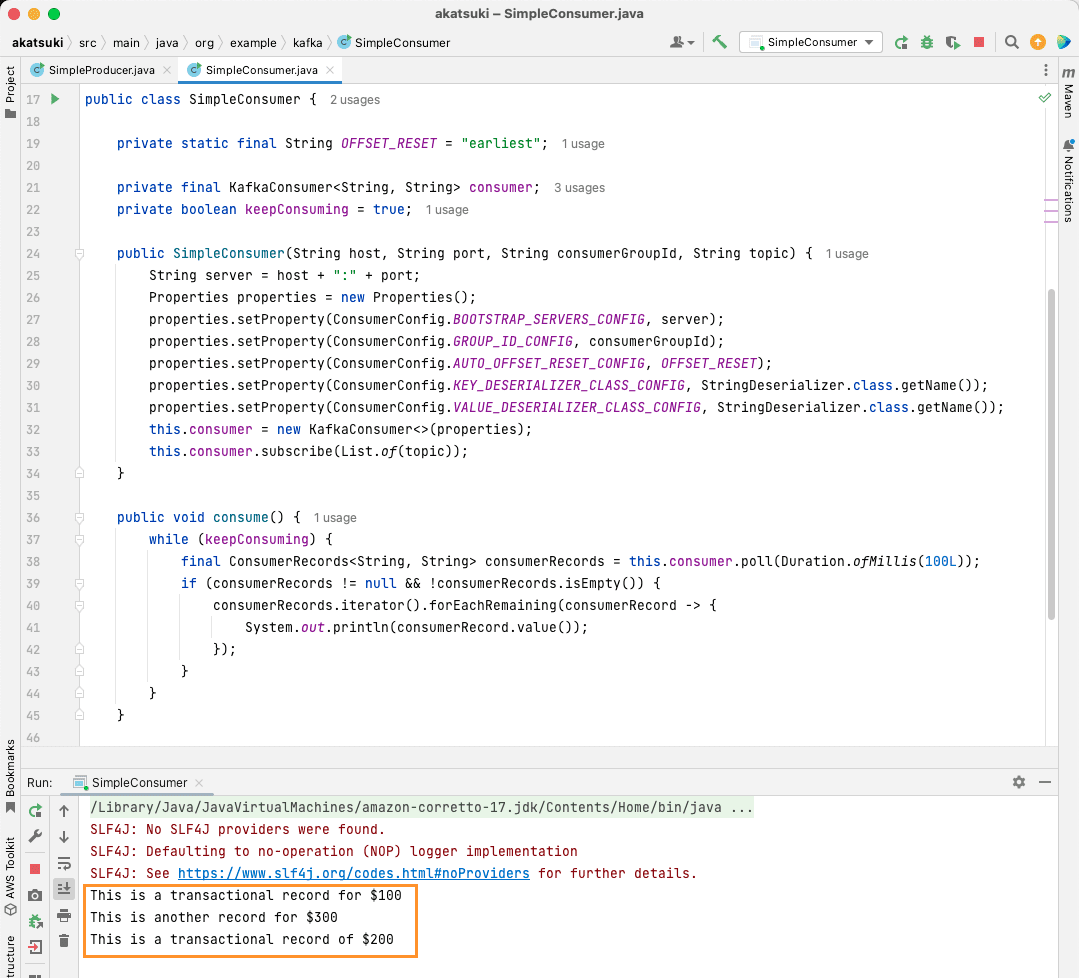
Com o SimpleConsumer em execução, você pode usar o produtor do console ou a aplicação SimpleProducer Java para produzir mensagens adicionais para o tópico. Você irá vê-las sendo consumidas e impressas no console.
Atenda a todas as suas necessidades de pipeline de dados com o Apache Kafka
O Apache Kafka permite que você gerencie todos os seus requisitos de pipeline de dados de forma simples. Com o Apache Kafka configurado em sua máquina local, você pode explorar todos os seus diferentes recursos. Além disso, o cliente Java oficial permite que você escreva, se conecte e se comunique com o servidor Apache Kafka de maneira eficaz.
Como um sistema de streaming de dados versátil, escalável e de alto desempenho, o Apache Kafka pode ser um divisor de águas. Você pode usá-lo para desenvolvimento local ou mesmo integrá-lo aos seus sistemas de produção. Assim como a configuração local é fácil, a configuração do Apache Kafka para aplicações maiores não é uma tarefa difícil.
Se você está procurando plataformas de streaming de dados, você pode consultar as melhores plataformas de dados de streaming para análise e processamento em tempo real.