O Amazon Glue tem ganhado notoriedade à medida que inúmeras organizações adotam serviços de integração de dados gerenciados.
O processo de ETL, que envolve a transferência de dados de um banco de dados de origem para um data warehouse, é notoriamente complexo. Sua implementação em larga escala para todos os dados corporativos pode ser desafiadora. Para simplificar essa tarefa, a Amazon introduziu o AWS Glue.
Desenvolvedores de ETL e engenheiros de dados utilizam o Glue para construir, acompanhar e executar fluxos de trabalho de ETL.
O que é o AWS Glue?
O AWS Glue, um serviço de integração de dados sem servidor, simplifica a descoberta, preparação, movimentação e integração de dados de diversas fontes. Essa capacidade é particularmente útil para aplicações de aprendizado de máquina (ML) e análise de dados.
Este serviço reduz significativamente o tempo necessário para preparar dados para análise. Ele automatiza a identificação e catalogação de dados, gera código em Scala ou Python para a transferência de dados da origem e realiza tarefas de carregamento e transformação de acordo com agendamentos ou eventos.
O AWS Glue oferece agendamento flexível e estabelece um ambiente Apache Spark escalável para lidar com grandes volumes de dados. Além disso, ele possibilita o monitoramento e a gestão de fluxos de dados complexos, sendo um serviço sem servidor que facilita o desenvolvimento de aplicações.
O serviço permite a rápida integração de diferentes conjuntos de dados, bem como a decomposição e autorização de dados com eficiência.
Aplicações do AWS Glue
É essencial compreender os contextos mais adequados para o uso do Amazon Glue. A seguir, apresentamos algumas situações em que o AWS Glue se destaca:
- O Glue possibilita a execução de consultas sem servidor em data lakes do Amazon S3. É uma ferramenta excelente para começar, pois centraliza todos os seus dados em uma única interface, permitindo análises sem a necessidade de movimentação.
- O Amazon Glue é útil para compreender seus ativos de dados. Facilita a busca por diversos conjuntos de dados da AWS através do Data Catalog. Além disso, permite o armazenamento de dados em vários serviços da AWS, mantendo uma visão unificada através do Data Catalog.
- O Glue pode ser empregado na criação de fluxos de trabalho de ETL orientados por eventos. Você pode ativar tarefas ETL do Glue via AWS Lambda ao realizar operações no Amazon S3.
- O AWS Glue também pode ser utilizado para limpar, validar, formatar e organizar dados antes de armazená-los em um data lake ou warehouse.
Componentes do AWS Glue
Os principais componentes do AWS Glue são:
- Catálogo de Dados: Armazena metadados e a estrutura dos dados.
- Banco de Dados: Fundamental para acessar e criar bancos de dados para fontes e destinos.
- Tabela: Permite a criação de uma ou mais tabelas no banco de dados, utilizadas tanto pela origem quanto pelo destino.
- Rastreador e Classificador: O rastreador identifica dados na origem, usando classificadores internos ou personalizados, e cria ou utiliza tabelas de metadados no catálogo de dados.
- Job: Representa a lógica de negócios para executar uma tarefa ETL, geralmente escrita em Apache Spark, usando Python ou Scala.
- Acionador: Inicia a execução de um job ETL sob demanda ou em um horário predefinido.
- Endpoint para Desenvolvimento: Configura um ambiente para testar, desenvolver e depurar scripts de jobs ETL.
Vantagens do AWS Glue
A utilização do AWS Glue traz benefícios para o seu ambiente de trabalho ou organização:
- O AWS Glue utiliza um rastreador para verificar automaticamente todos os dados disponíveis.
- Os dados processados podem ser armazenados em várias plataformas, como Amazon RDS, Amazon Redshift e Amazon S3.
- É um serviço baseado em nuvem, eliminando a necessidade de infraestrutura local.
- Sendo um serviço ETL sem servidor, oferece uma opção econômica.
- É um serviço rápido, fornecendo o código ETL em Python/Scala de forma imediata.
Principais Funcionalidades do AWS Glue
O Amazon Glue possui todos os recursos necessários para a integração de dados, possibilitando a obtenção de insights e a aplicação do conhecimento para avanços em minutos, em vez de meses. Algumas das funcionalidades notáveis incluem:
- Interface de Arrastar e Soltar: Permite a criação de processos ETL por meio de um editor visual, gerando automaticamente o código necessário para extração, transformação e carregamento de dados.
- Descoberta Automática de Esquema: Utiliza o serviço Glue para criar rastreadores que se conectam a diferentes fontes de dados, organizando-os e extraindo informações relevantes. Esses dados podem ser usados para monitorar processos ETL por tarefas.
- Agendamento de Jobs: Permite a execução de jobs sob demanda ou de acordo com um cronograma. O agendador é útil para a construção de pipelines ETL complexos, estabelecendo dependências entre as tarefas.
- Geração de Código: O Glue Elastic Views possibilita a criação facilitada de visualizações materializadas, combinando e replicando dados de diferentes fontes sem a necessidade de escrever código personalizado.
- Aprendizado de Máquina Integrado: Inclui um recurso de aprendizado de máquina, o “FindMatches”, que desduplica registros que não são cópias exatas.
- Pontos de Extremidade do Desenvolvedor: Fornece pontos de extremidade que permitem aos desenvolvedores modificar, depurar e testar o código ETL.
- Glue DataBrew: Uma ferramenta de preparação de dados para analistas e cientistas de dados, auxiliando na limpeza e normalização de dados através de uma interface visual.
Preços do AWS Glue
O AWS Glue cobra uma taxa por hora, faturada por segundo, para crawlers (descoberta de dados) e jobs de ETL (processamento e carregamento de dados). O acesso e armazenamento de metadados no AWS Glue Data Catalog envolvem uma taxa mensal fixa.
O Amazon Glue tem um custo inicial de US$ 0,44 e oferece quatro planos:
- Jobs ETL, endpoints de desenvolvimento e outras tarefas ETL: US$ 0,44
- Sessões interativas de crawlers: US$ 0,44
- Jobs do DataBrew: a partir de US$ 0,48
- Armazenamento mensal e solicitações ao Catálogo de Dados: US$ 1,00
A AWS não oferece um plano gratuito para o Glue. Cada hora tem o custo de US$ 0,44 por DPU, o que significa um custo médio de US$ 21 por dia. Os preços podem variar dependendo da região.
Configuração do AWS Glue
O Data Catalog permite a localização e pesquisa de diversos conjuntos de dados da AWS sem movimentá-los. Após a catalogação, os dados ficam disponíveis para consulta através do Amazon Athena e Amazon EMR.
Ref.: https://aws.amazon.com/glue/
- Descubra, armazene metadados e utilize o AWS Glue Data Catalog para acessar seus dados no Amazon Redshift, Amazon S3, Amazon RDS e bancos de dados no Amazon EC2.
- Gerencie dados com o Catálogo de Dados, que funciona como um repositório central de metadados.
- Leia e grave metadados no seu catálogo de dados através do AWS Glue ETL.
- Aproveite o catálogo de dados para ETL, análises e mais com Amazon Athena, Amazon Redshift, Amazon EMR e Amazon ETL.
Como Configurar o AWS Glue?
Inicialmente, acesse o Console de Gerenciamento da AWS e abra o console do IAM. Clique em “Criar função”. Em seguida, selecione “Glue” como tipo de função e defina as permissões.
Para permissões gerais do AWS Glue Studio e AWS Glue, escolha “AWSGlueServiceRole” e para acesso a recursos do Amazon S3, selecione a política gerenciada pela AWS “AmazonS3FullAccess”.
Defina um nome para a função.
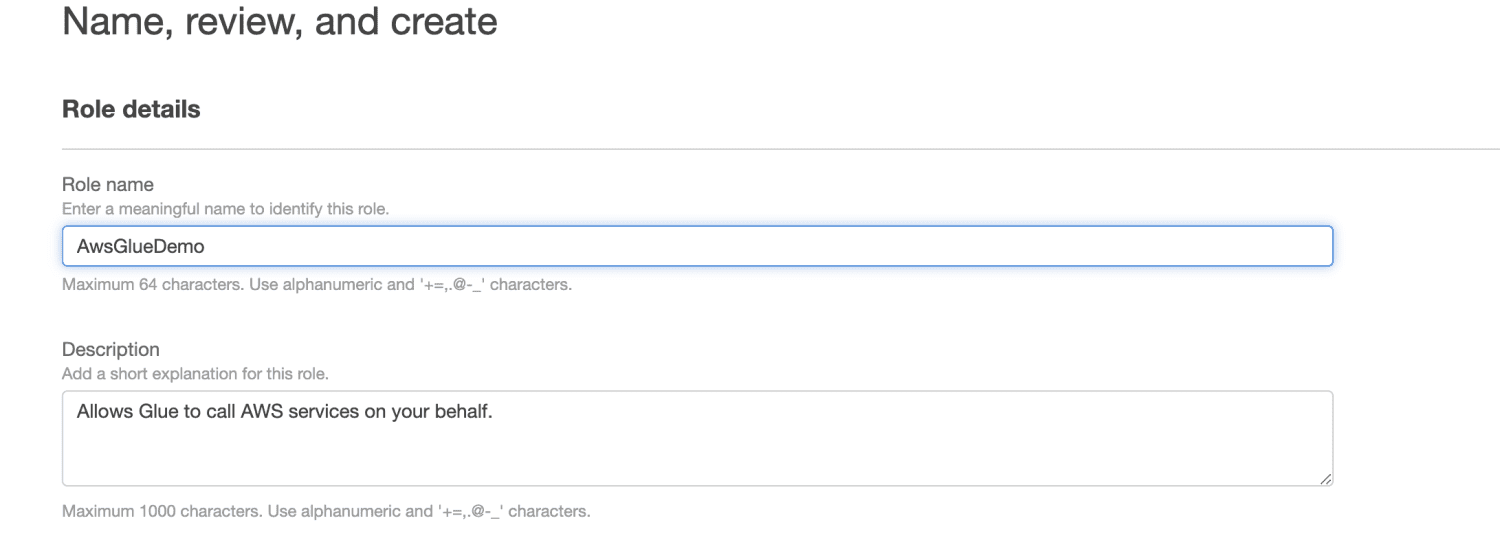
Clique em “Criar Função”.
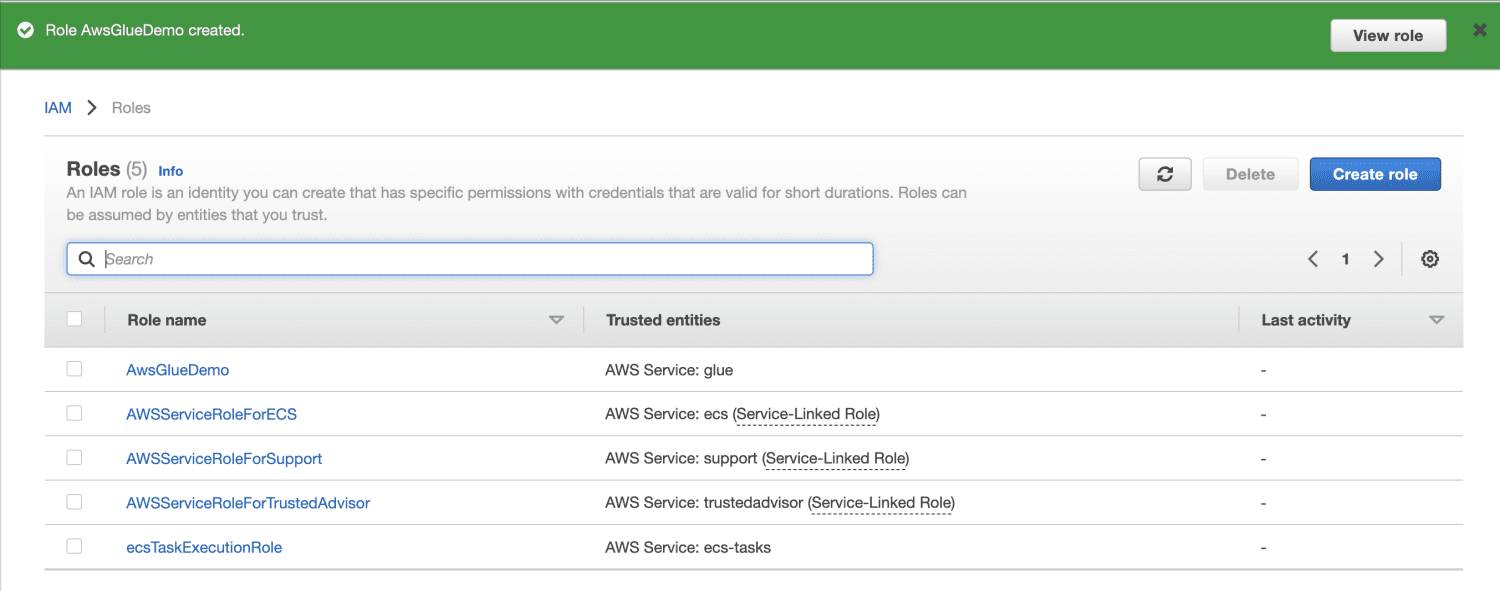
Crie um bucket no Amazon S3.
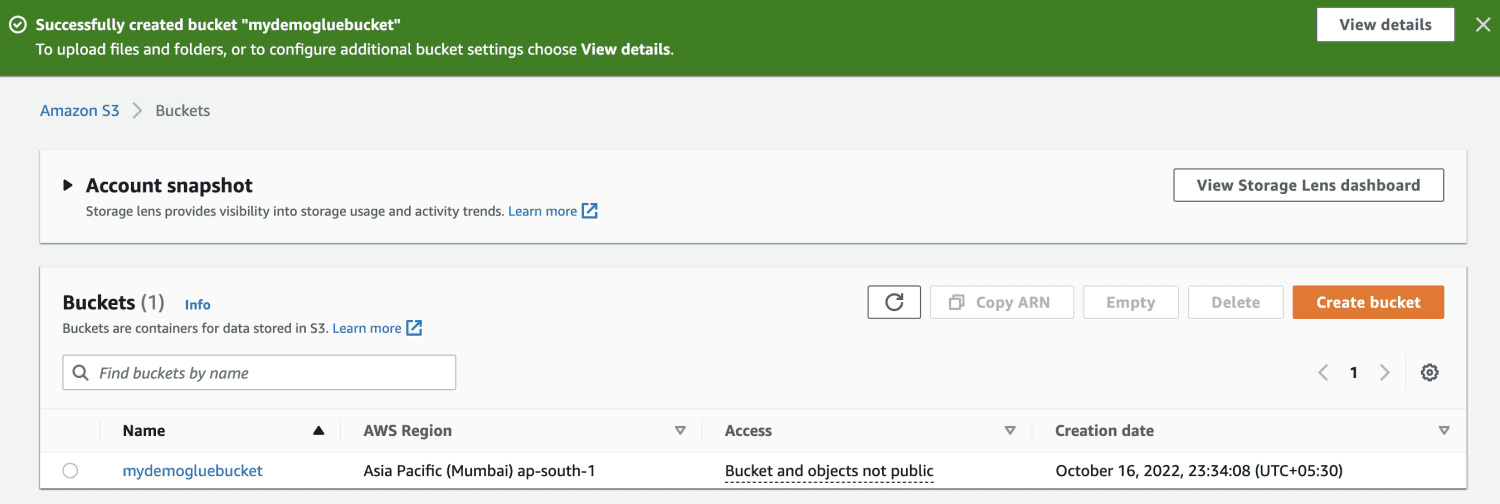
Crie uma pasta dentro do bucket do S3.
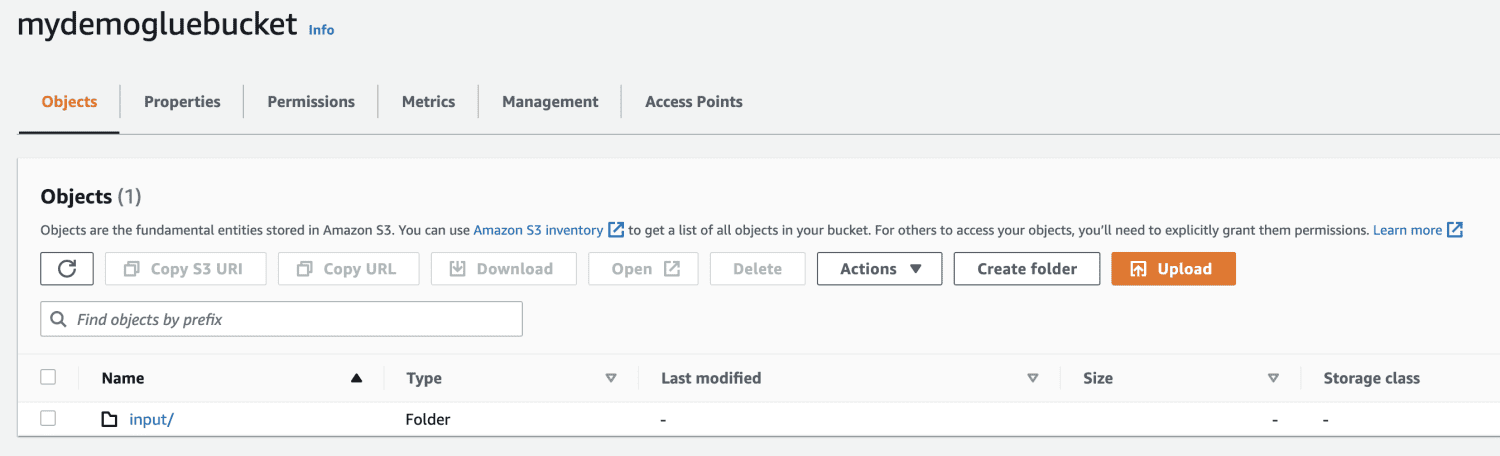
Selecione o arquivo para upload.
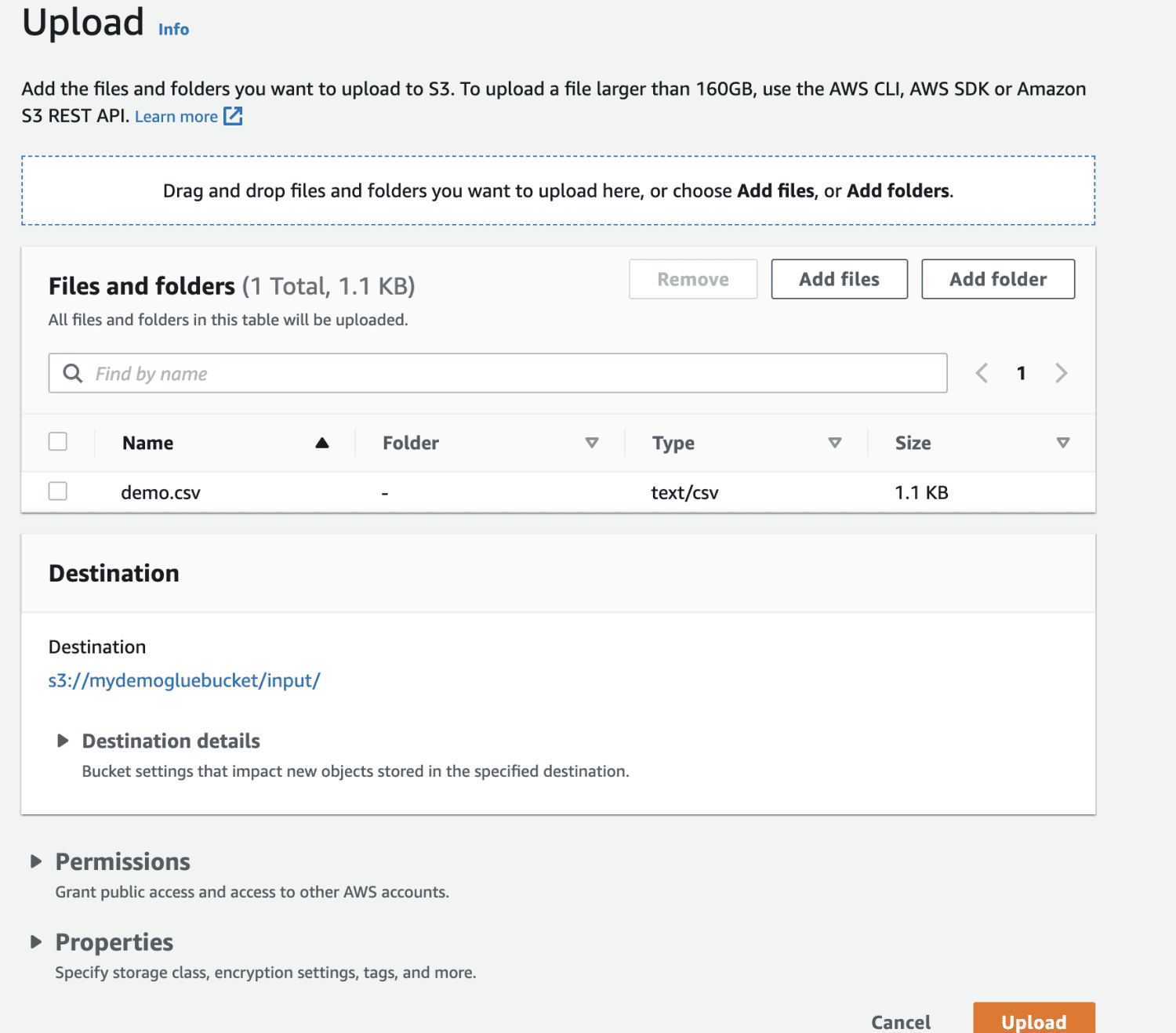
Finalmente, carregue o arquivo no bucket.
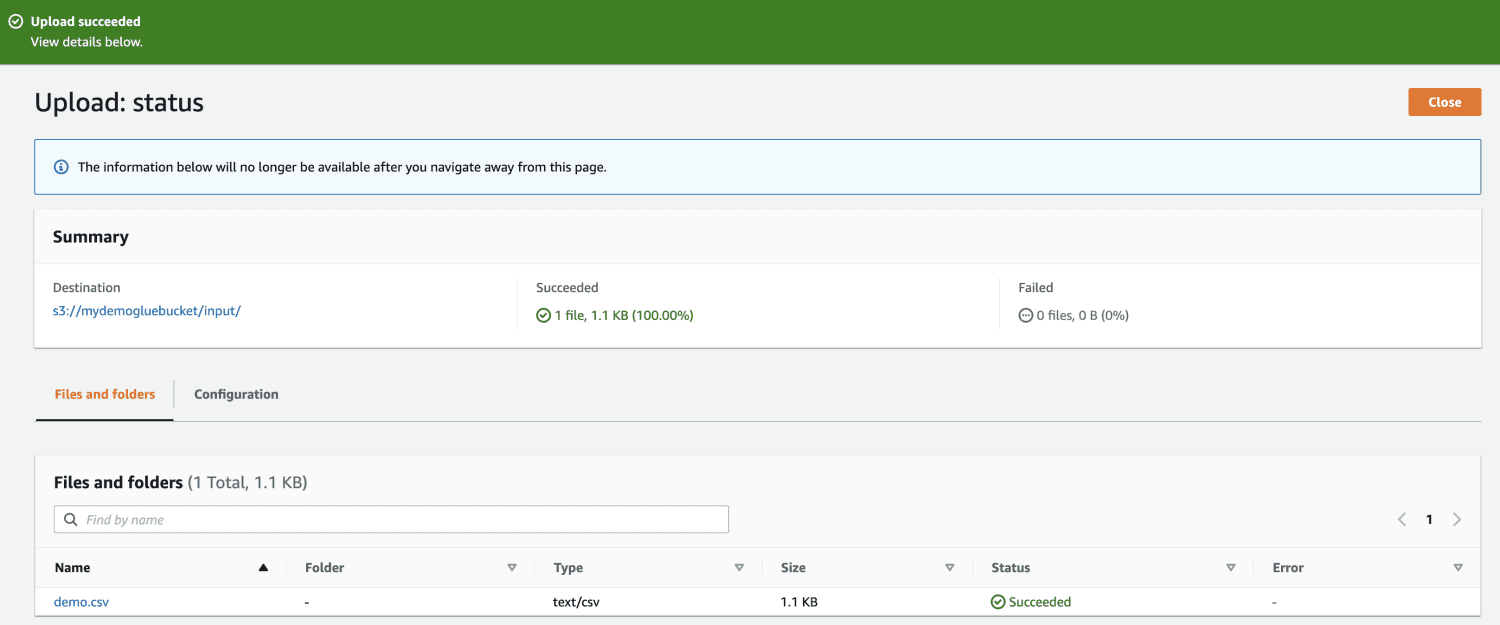
Em seguida, acesse o AWS Glue no console de gerenciamento e crie um banco de dados.
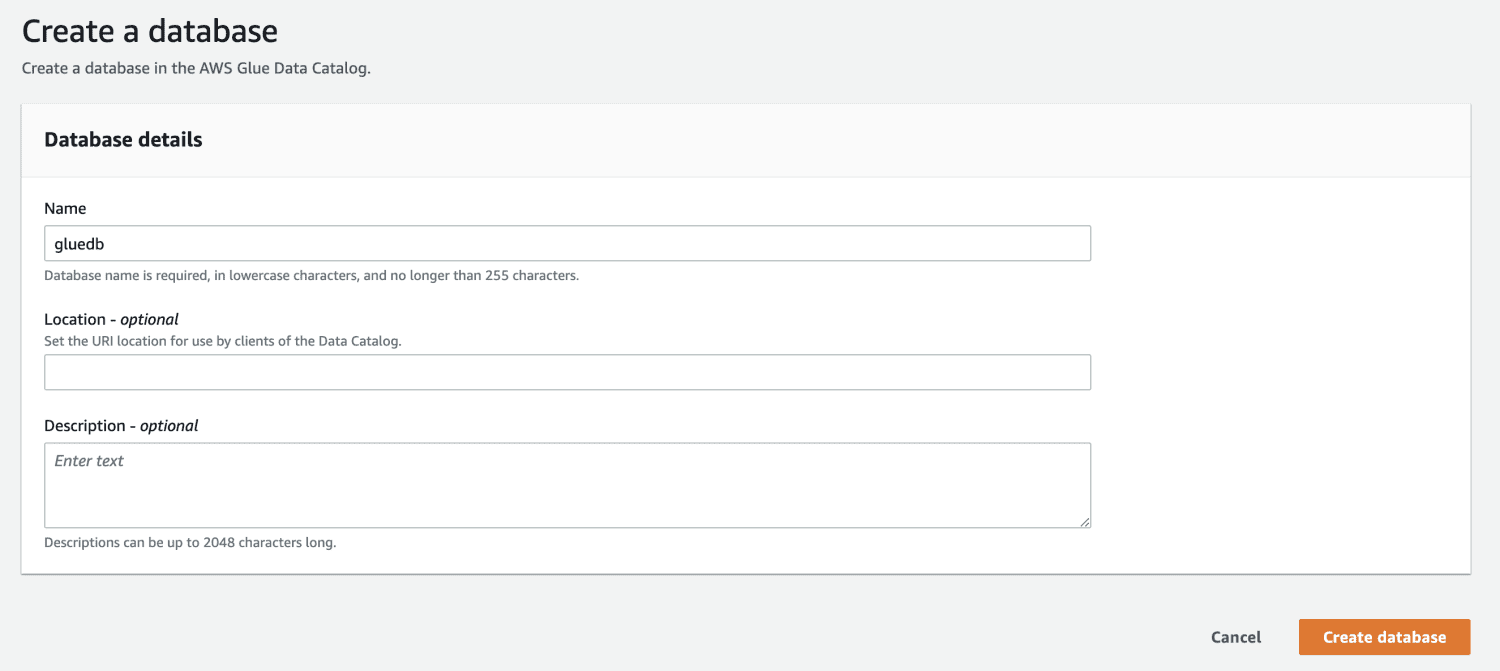
Após criar o banco de dados no AWS Glue, crie um crawler.
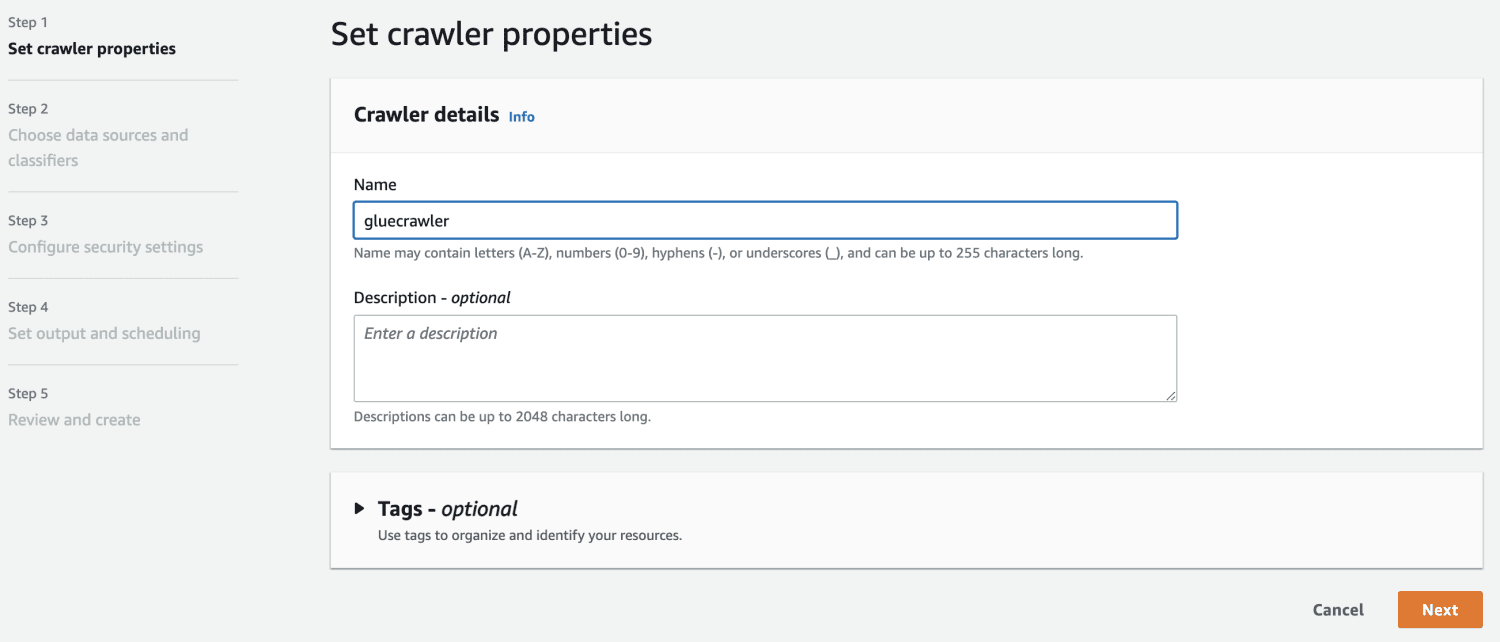
Na fonte de dados, selecione o bucket do S3 que foi criado.
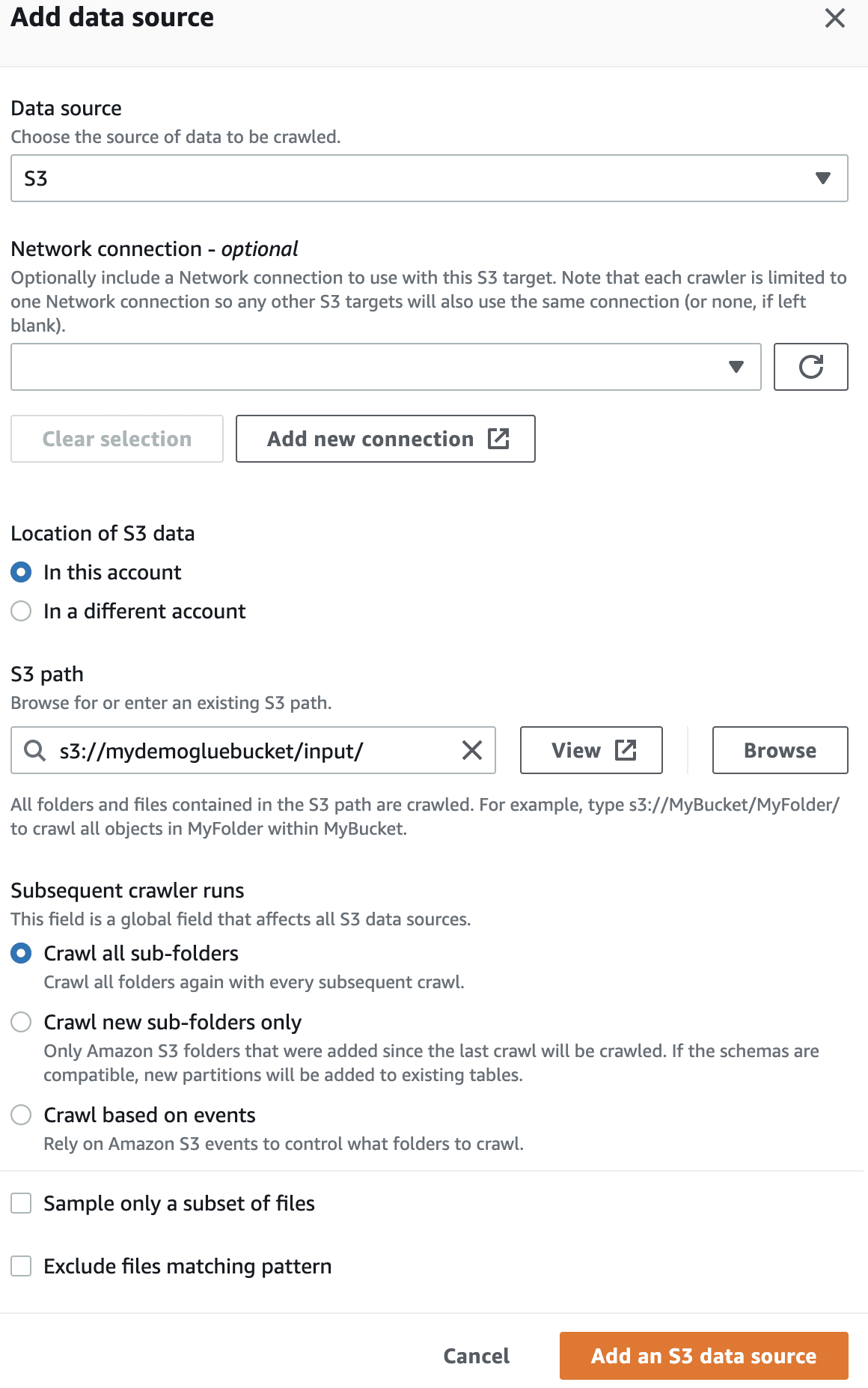
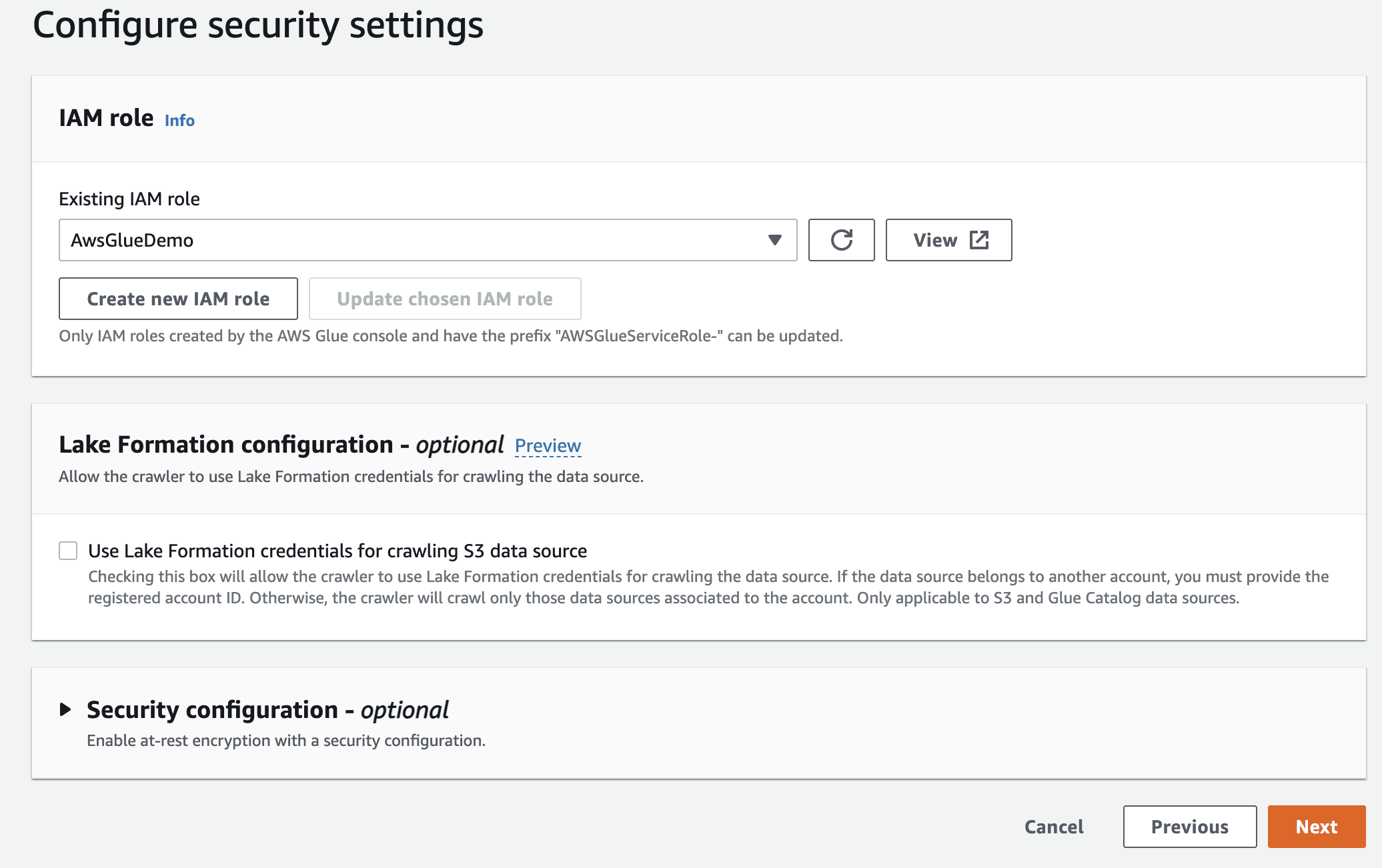
Selecione a função do IAM para AWS Glue que você criou anteriormente.
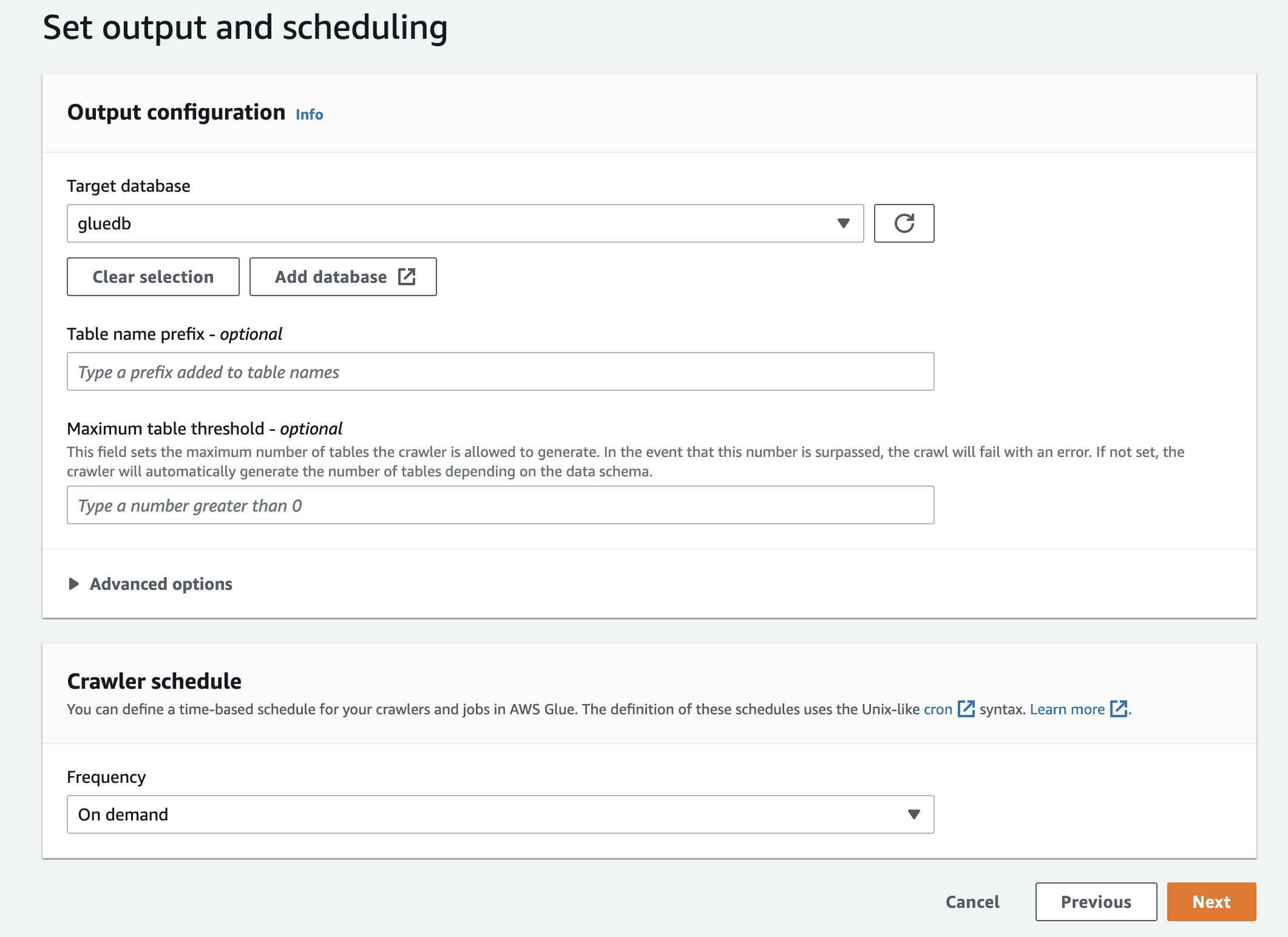
Por fim, na saída, selecione o banco de dados “gluedb” que você criou.
Confira todas as configurações e crie o rastreador.
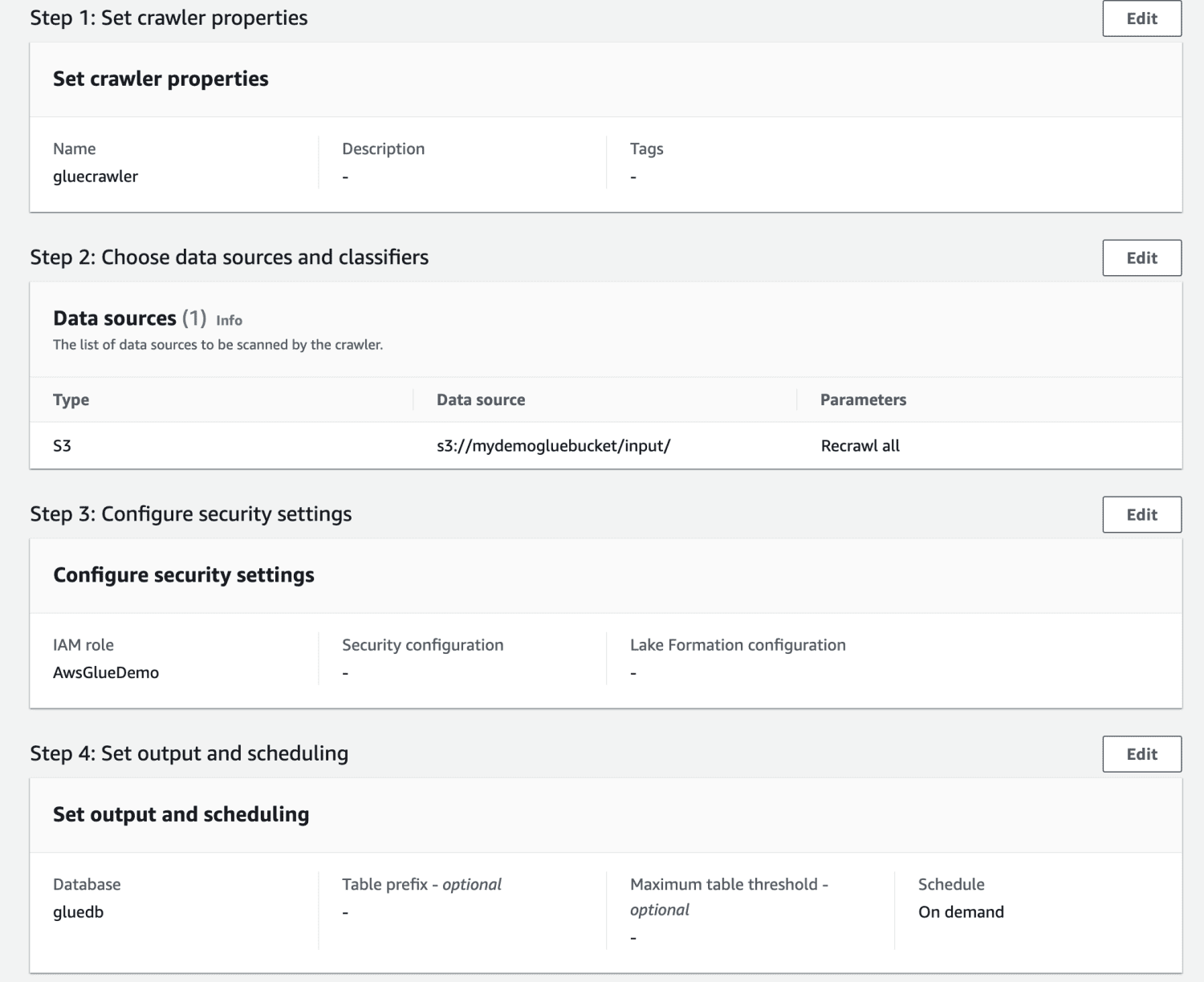
Após a criação, selecione o rastreador e clique em “Executar”. Após algum tempo, o status será “pronto”.
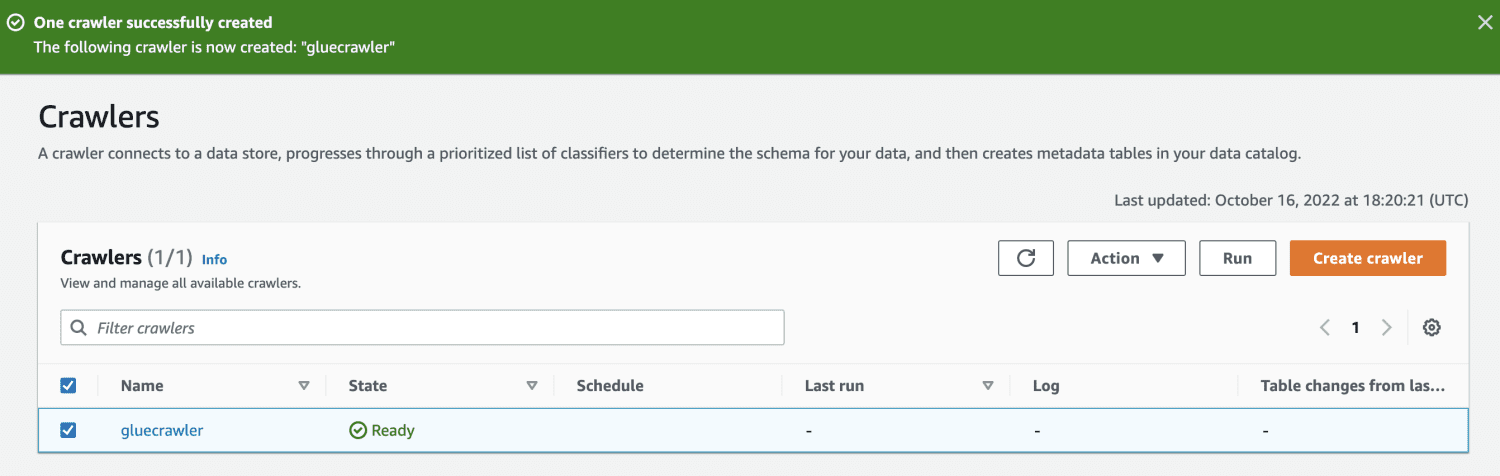
Ao executar o crawler, o banco de dados receberá uma tabela com todos os dados do arquivo CSV.
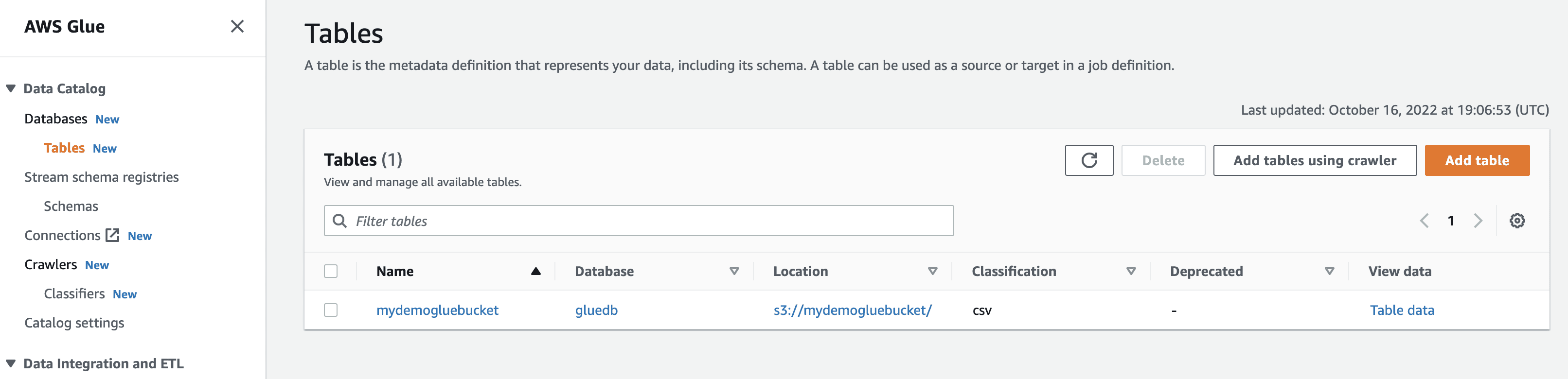
Ao clicar em “visualizar dados”, você será redirecionado para o Amazon Athena (editor de consultas). Ao executar a consulta, você visualizará os dados da tabela.
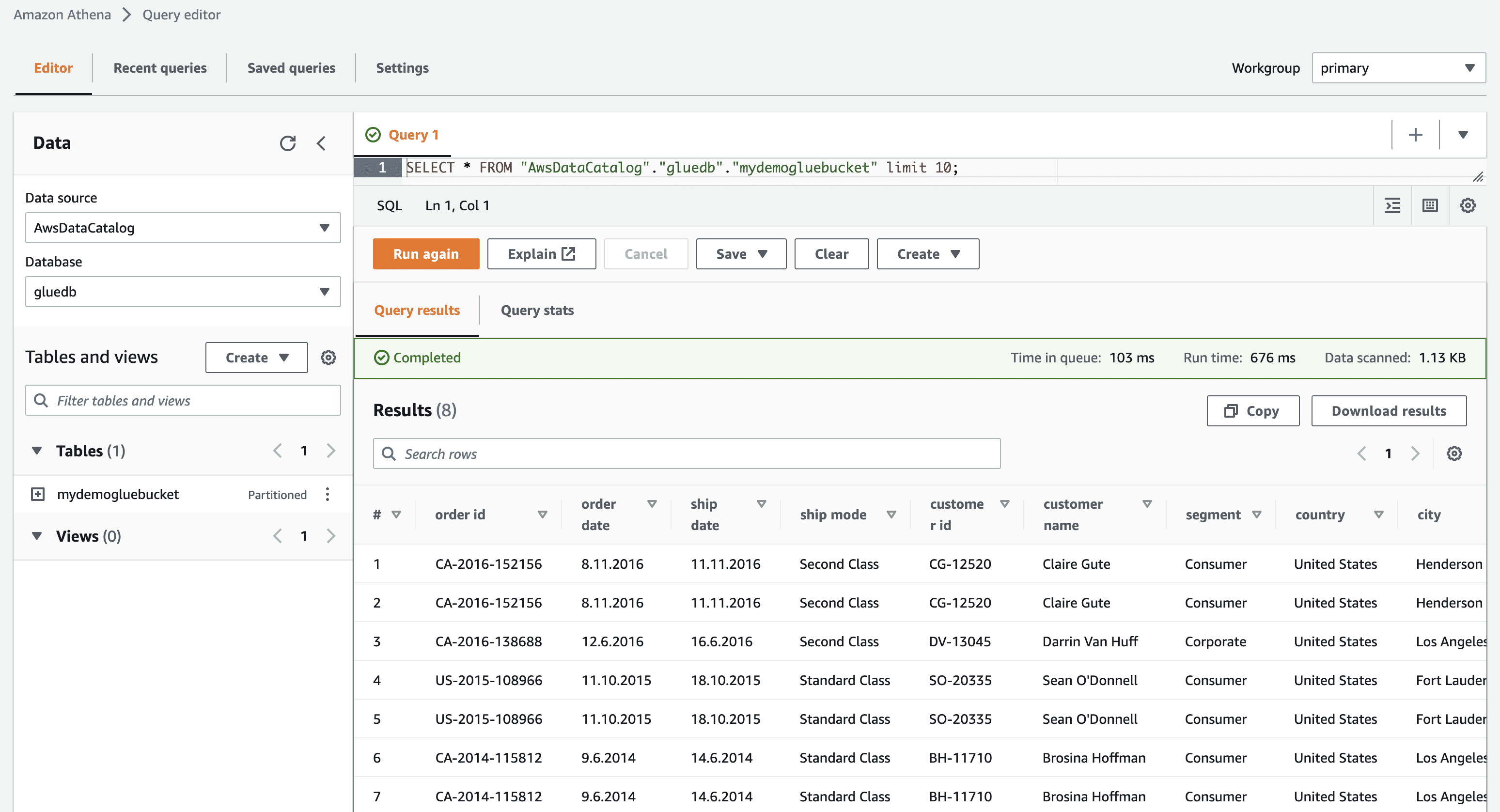
Agora você pode usar este crawler do AWS Glue com sucesso em qualquer job de ETL.
O que é o AWS Glue Databrew?
O AWS Glue DataBrew permite que os usuários normalizem e limpem dados sem escrever código. Esta ferramenta pode reduzir o tempo necessário para a preparação de dados para machine learning e análise em até 80%, em comparação com soluções de preparação de dados personalizadas.
O DataBrew oferece mais de 250 transformações de dados predefinidas, que podem ser utilizadas para automatizar tarefas de preparação de dados, como filtragem de anomalias, correção de valores inválidos e conversão de dados em formatos padrão.
Essa ferramenta facilita a colaboração entre cientistas de dados, analistas e engenheiros na extração de insights de dados brutos. Sendo um serviço sem servidor, o DataBrew dispensa a gestão de infraestrutura ou a criação de clusters para a exploração e transformação de terabytes de dados brutos.
Recursos do DataBrew para Empresas
Preparação de Dados Visualizada
O DataBrew oferece uma nova maneira de visualizar dados que geralmente são apresentados em bancos de dados colunares como números alfanuméricos. Ele visualiza todas as fontes de dados carregadas para facilitar a compreensão das relações e hierarquia dos dados.
Mais de 250 Automações de Preparação de Dados
Cientistas de dados seguem uma variedade de fluxos de trabalho isolados e repetíveis. Esses fluxos de trabalho foram modelados pela AWS como módulos de linguagem e módulos agnósticos de dados, criando uma biblioteca de ações úteis para usuários finais.
Linhagem de Dados
Assim como os logs de auditoria, a linhagem de dados permite rastrear as atividades de transformação de dados no AWS DataBrew, incluindo informações sobre a fonte de dados, transformações aplicadas e a saída de dados, incluindo o local de destino.
Mapeamento de Dados
O DataBrew permite a identificação de campos correspondentes em diferentes fontes de dados, que podem ser carregados em um esquema após a identificação.
Benefícios do AWS Glue DataBrew
Os benefícios do AWS Glue DataBrew incluem:
- Redução da complexidade na preparação de dados.
- Geração automática de perfis de dados.
- Automatização de mais de 250 processos de preparação de dados.
- Sugestões prescritivas inteligentes.
Alternativas ao AWS Glue
Airflow
O Airflow é uma ferramenta de código aberto para gestão de fluxos de trabalho. Ele permite a criação de fluxos de trabalho utilizando diagramas acíclicos direcionados (DAGs). O agendador do Airflow executa tarefas através de uma matriz de trabalhadores, seguindo as dependências especificadas.
Matillion

Matillion ETL é uma ferramenta de ETL/ELT projetada para plataformas de bancos de dados em nuvem como Amazon Redshift e Google BigQuery. Possui uma interface de usuário baseada em navegador com funcionalidades avançadas de ETL/ELT push-down. A instalação é rápida, permitindo o uso em poucos minutos.
Stitch
O Stitch é um serviço ETL de código aberto que conecta várias fontes de dados e replica dados para destinos preferenciais. É uma ferramenta fácil de usar que não exige conhecimento de codificação para a transferência de dados entre origens e destinos. Possui uma interface gráfica amigável e é conhecido pela sua rapidez.
Diferentemente de outras ferramentas ETL, o Stitch não oferece um painel pré-fabricado, exigindo a integração de dados com data warehouses abertos como destino, o que pode tornar a navegação pelos inventários um pouco complexa.
Alteryx

O Alteryx é uma plataforma de automação de análise que auxilia na preparação e combinação da coleta de dados. Esses dados podem ser usados para acelerar processos e fornecer insights de negócios. Por ser uma ferramenta de arrastar e soltar, não é necessário conhecimento de programação. É uma excelente fonte de aconselhamento e respostas de profissionais da área.
Conclusão
Este artigo abordou o AWS Glue, uma solução baseada em nuvem para trabalhar com pipelines ETL. O processo de interação do usuário com o AWS Glue envolve três fases: a criação de um catálogo de dados por meio de rastreadores, a criação do código ETL e o agendamento ETL. Espero que este artigo tenha fornecido uma boa visão geral do Amazon Glue.
Você também pode explorar as melhores dicas para proteger o armazenamento do AWS S3.