Pode parecer intimidador, mas integrar uma função de pesquisa robusta ao seu aplicativo não precisa ser um processo complexo ou demorado. Apresento aqui algumas sugestões valiosas!
Embora inúmeras tecnologias tenham causado impacto nas últimas duas ou três décadas, a pesquisa se destaca como uma das poucas que se tornou parte essencial do nosso cotidiano. Ela está presente em todos os lugares – sites de comércio eletrônico, blogs, bases de conhecimento e muito mais – não apenas por causa da aparência de uma caixa de busca e um ícone, mas porque resolvem uma necessidade fundamental.
Se a sua empresa está em busca de uma solução de pesquisa eficaz ou está insatisfeita com a que usa atualmente, o que fazer?
Felizmente, não é necessário arcar com custos de licenciamento exorbitantes, nem manter uma equipe de 20 desenvolvedores e administradores de sistema. Hoje, apresento algumas recomendações de mecanismos de pesquisa que podem ser implementados e integrados rapidamente, especialmente por pequenas empresas com equipes de desenvolvimento reduzidas, de um ou dois integrantes.
MeiliSearch
Um dos mecanismos de pesquisa mais eficazes e valiosos disponíveis é o MeiliSearch.
O que me leva a incluir o MeiliSearch entre minhas principais recomendações?
Aqui estão os motivos:
Código Aberto
Todo o código-fonte que impulsiona o MeiliSearch está acessível gratuitamente no GitHub. Isso significa que os próprios desenvolvedores podem analisar qualquer trecho do código. Em contrapartida, as empresas podem ter certeza da qualidade e da intenção (sem backdoors ou scanners no programa, por exemplo). E, claro, desenvolvedores experientes podem colaborar para aprimorar ainda mais a tecnologia.
Excelente Experiência do Usuário
O MeiliSearch não opera com regras complexas (como “a – b” significando a, mas não b). Basta digitar a sua pesquisa de forma natural e os resultados começam a aparecer de forma fluida. O mecanismo é altamente tolerante e adaptável, oferecendo resultados precisos mesmo quando há erros de digitação ou uso de sinônimos. Além disso, ele suporta diversos idiomas.
Excelente Experiência de Desenvolvimento
Os desenvolvedores vão adorar o MeiliSearch! Ele não é apenas personalizável e escalável, mas também opera como uma API REST! A documentação também é excelente e completa. Embora fazer chamadas HTTP seja trivial em qualquer linguagem, exemplos em cinco linguagens (JavaScript, Ruby, Python, Golang e PHP) são fornecidos para aqueles que estão com pressa.
Soluções de pesquisa simples devem ser fáceis de usar e configurar. Nesse sentido, o MeiliSearch atende a todos os requisitos! Quando estiver pronto para prosseguir, comece na DigitalOcean com um único clique.
Solr
O Solr, parte do projeto Apache, está no mercado há algum tempo. Ele é baseado na conhecida e altamente confiável biblioteca Lucene, que também alimenta a popular solução de pesquisa chamada ElasticSearch. Tudo isso significa que o Solr está entre as soluções de pesquisa mais poderosas, escaláveis, compatíveis com os padrões, ricas em recursos e confiáveis.
Ele é utilizado por gigantes como Disney, eBay, Netflix, Zappos e BestBuy. No entanto, isso não impede que você realize uma instalação menor e mais simples (por exemplo, em uma única máquina, sem necessidade de escalabilidade ou failover) e aproveite todo o poder do Solr.
Então, por que optar pelo Solr?
Aqui estão alguns excelentes motivos:
Preciso e Poderoso
O Solr está entre os sistemas de busca mais precisos, capazes e poderosos do mundo. Além disso, ele é de código aberto, o que explica por que grandes nomes (como mencionado anteriormente) o escolheram. Sua capacidade de processar documentos e responder a consultas de pesquisa é incomparável.
Instalação e Manutenção Simples
Instalar o Solr é tão simples quanto descompactar e executar o programa. Para sistemas simples de uma única máquina, não é necessária manutenção complexa; basta monitorar o uso da RAM, já que soluções de pesquisa em geral e tecnologias baseadas em Java em particular podem consumir bastante RAM (porque elas mantêm ou tentam manter tudo na RAM para fornecer leituras/gravações rápidas).
Painel de Administração
O Solr vem com um painel de administração que permite monitoramento e configuração visual. Com um treinamento básico, mesmo usuários não desenvolvedores podem aprender a interpretar os gráficos principais. Poucas soluções de pesquisa nesta lista oferecem funcionalidades como essa.
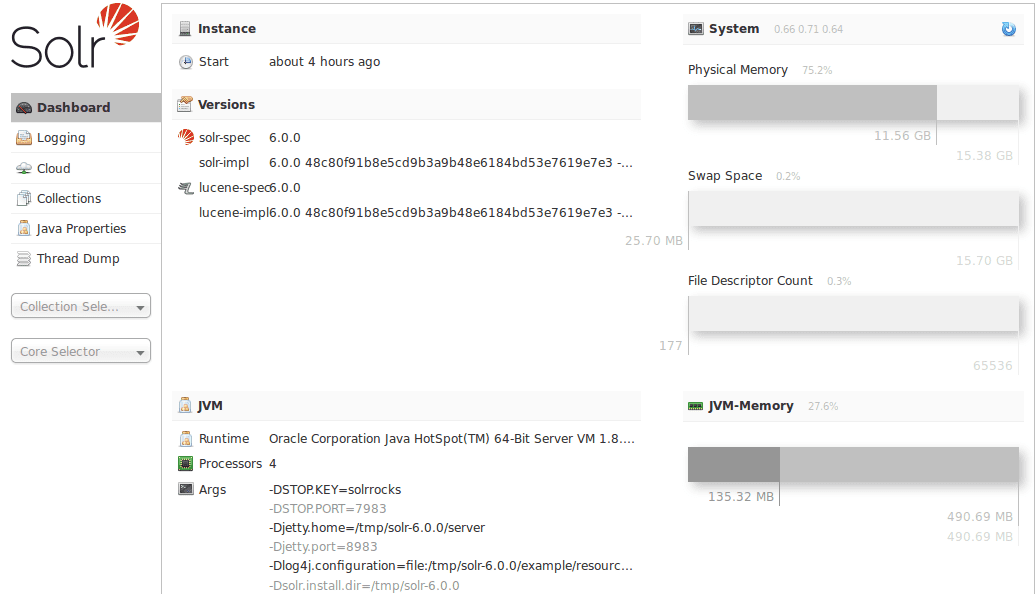
Guiado por API e Compatível com Padrões
O Solr fornece uma interface de resultados em uma API que pode lidar com diversos formatos – JSON, CSV, XML e binário. Ele produz dados de monitoramento de acordo com o padrão JMX, um grande benefício para desenvolvedores Java.
Há muito mais a ser dito em favor do Solr, mas tentar cobrir tudo nos levaria à eternidade. 😂 Basta dizer que o Solr é uma solução de primeira linha e você nunca se arrependerá de escolhê-lo, independentemente do tipo de dados com que você trabalha.
Elasticsearch
O Elasticsearch foi, e provavelmente ainda é, um pioneiro na pesquisa de texto de formato livre. Na verdade, ainda hoje, se você perguntar a um programador ou administrador de sistema por uma recomendação sobre mecanismos de pesquisa, o Elasticsearch provavelmente será o único nome que eles mencionarão. Claro, atualmente, um número considerável também recomendaria algo como o Algolia, mas já abordamos esse ponto. 🤪

Não se deixe enganar pelo botão “Iniciar teste gratuito” no gráfico acima. Embora a tecnologia principal do Elasticsearch seja de código aberto e gratuita, a empresa está tentando monetizar seus esforços e atrair clientes corporativos. Portanto, o que você vê aqui é, na verdade, um teste do serviço de nuvem, que facilita o gerenciamento do Elasticsearch, especialmente quando há clusters envolvidos.
Ufa, são muitos detalhes para esclarecer. Vamos recapitular: o Elasticsearch é de código aberto e gratuito, e qualquer pessoa pode configurá-lo facilmente e usá-lo sem restrições.
E agora, como esperado, vamos analisar os motivos para escolher o Elasticsearch:
- Mecanismo de pesquisa maduro e testado em diversas situações. Isso significa que é muito mais provável que você encontre soluções caso se depare com bugs “estranhos”.
- Foco de primeira classe em clustering, escalabilidade e gravações assíncronas.
- Acessível por meio de uma API REST simples (que acabou sendo copiada por todos).
- Orientado a documentos, mas suporta esquema, se necessário.
- Resultados incrivelmente rápidos e precisos. Velocidade de pesquisa configurável.
- Documentação excelente, tanto em quantidade quanto em utilidade.
- Uma plataforma de nuvem completa de pesquisa e análise (a pilha ELK), se você quiser pagar pela conveniência.
A única ressalva que eu teria em relação ao Elasticsearch é o enorme consumo de RAM. Quero dizer, como consultores, é difícil convencer os clientes a investir em um servidor que custa US$ 20/mês, o que infelizmente não chega nem perto do que o Elasticsearch exige.
Se você está curioso para aprender sobre o Elasticsearch, confira este curso da Udemy.
Typesense
O Typesense é um mecanismo de pesquisa leve, direto e poderoso. Aqueles que buscam praticidade e simplicidade devem definitivamente experimentar este.
Uma das melhores características do Typesense é a possibilidade de experimentá-lo diretamente no site deles. Isso pode poupar frustração e tempo nos casos em que você configura tudo e experimenta a API… apenas para descobrir que um ou mais recursos não funcionam como você gostaria.
Isso não significa que não possam existir bugs no mecanismo; a questão é que a interpretação do mecanismo sobre algo pode não ser a sua preferência, ou pode estar em conflito direto com o seu negócio. Erros de digitação, símbolos especiais, sinônimos e muito mais… você pode verificar os resultados que o mecanismo produz diretamente na página inicial (eles estão usando um banco de dados de livros para isso).
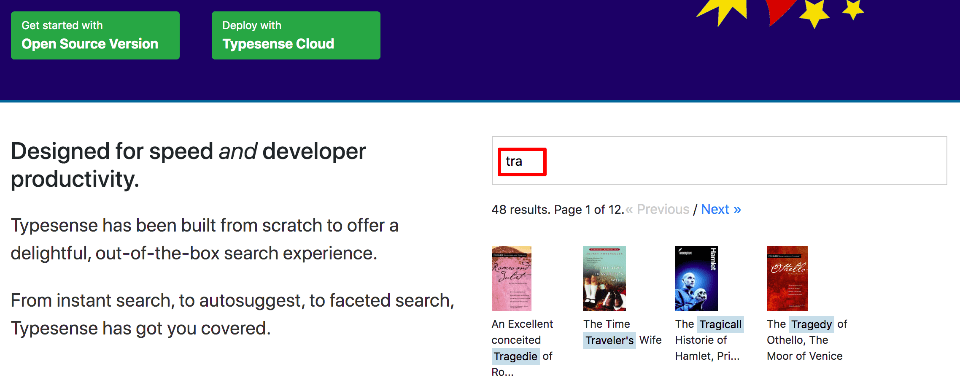
Como você pode ver, esta seção está logo abaixo da mais alta. Na caixa de pesquisa, inseri a consulta “tra” e, abaixo, vejo os resultados correspondentes do banco de dados de livros (bem como os metadados – resultados totais, página atual etc.).
O Typesense tem muito a oferecer quando se trata de um mecanismo de pesquisa de sua escolha:
- A tecnologia por trás dele é totalmente de código aberto e receptiva.
- Fácil de configurar uma configuração de HA (Alta Disponibilidade), caso você precise de uma.
- Tolerante quando se trata de erros de digitação e outros ruídos nas consultas de pesquisa.
- Um sistema de filtragem avançado para quem precisa de um controle refinado dos resultados da pesquisa.
- API REST simples, embora a documentação dificulte um pouco encontrá-la!
- Clientes (SDKs) estão disponíveis para algumas das principais linguagens (JavaScript, Python, Ruby e PHP).
Finalmente, se a ideia de configurar novos servidores for cansativa, o Typesense também oferece uma solução em nuvem onde o provisionamento leva apenas um clique. O faturamento é por hora e as leituras e gravações são ilimitadas. Sinceramente, esta é a melhor opção para a maioria das empresas, desde que tenham avaliado os preços com antecedência e tenham certeza de que é uma vantagem líquida.
Em suma, o Typesense faz muito sentido (sem trocadilhos!) se você precisa de algo pequeno, elegante, preciso e realmente eficiente.
Sonic
O Sonic se destaca por ser uma alternativa ao ElasticSearch que opera com “apenas alguns MBs de RAM”.
Como isso é possível?
Bem, a Java Virtual Machine (JVM) é conhecida por consumir muita RAM (normalmente, apenas iniciar a JVM consome cerca de 1 GB de RAM); não é surpresa, portanto, que algo codificado na linguagem Rust (que oferece controle total e segurança de memória para desenvolvedores) possa ser executado com a mesma rapidez e usar apenas alguns MBs de RAM.

Até o momento, existem algumas empresas listadas entre seus usuários, embora eu tenha certeza de que há outras que não se incomodaram em adicionar seus nomes. Não me lembro como ou quando exatamente, mas já encontrei o Sonic antes; naquela época, embora eu estivesse feliz em ver uma alternativa que consumisse pouca memória, achei que ele precisaria de tempo para se estabilizar e corrigir bugs ocultos. Bem, parece que eles já chegaram a esse ponto; o quão popular o Sonic se tornará é algo que só o tempo dirá.
Ok, deixando de lado as divagações, por que você deveria considerar usar o Sonic para sua organização/projeto?
Aqui estão alguns motivos:
- Consumo de memória extremamente baixo, quando comparado a outros mecanismos de pesquisa.
- As bibliotecas estão disponíveis para todas as principais linguagens de programação. Node, PHP e Rust são as linguagens que os próprios autores disponibilizaram, enquanto outras foram criadas pela comunidade (alegre-se, pois até mesmo linguagens exóticas como Elixir e Nim são suportadas!).
- Vários idiomas são suportados (era muito para contar, mas acho que, no momento da redação, cerca de 40 a 50 idiomas são suportados).
- Uma surpresa! Você pode até usar novos idiomas, e o mecanismo funcionará (😂😂), embora você perca alguns recursos avançados, como palavras de parada.
- Motor muito rápido. Se você verificar a página do GitHub, verá que os tempos de ingestão e pesquisa foram em microssegundos em diversos casos! Claro, este foi um teste em uma única máquina, já que a latência da rede nunca permitiria que os números fossem tão baixos.
Se você quiser ver este mecanismo em ação, acesse este link (uma das empresas que o utilizam) e experimente a caixa de pesquisa que você vê lá:
Existem algumas limitações no Sonic como mecanismo de pesquisa. Os desenvolvedores as destacaram e discutiram abertamente na página do GitHub. Meu conselho seria analisar essa lista com atenção e verificar se seus casos de uso não coincidem com as limitações apontadas. Dito isso, tudo tem limitações; a questão é que elas são mantidas em segredo e, por isso, não percebemos até que seja tarde demais. Portanto, considero o Sonic uma ótima opção para um mecanismo de busca.
TNT Search
Agora temos uma adição fascinante a esta lista. A primeira coisa interessante é que este mecanismo de pesquisa completo e pronto para uso em produção foi escrito em PHP!
Sim, de todas as linguagens possíveis, PHP. E digo isso não porque odeio PHP, mas porque ele é um processo de curta duração por natureza.

A segunda coisa interessante é a sua licença, pelo menos no momento da redação. Na verdade, a licença em si é MIT, então não há problemas aí, mas os autores classificam este software como PS4Ware; se você usa o TNTSearch em produção, deve enviar um jogo de PS4 para eles! 😂😂😂 Agora, não é obrigatório, como o “deveria” indica, mas é bem engraçado. Também espero que eles atualizem para uma licença PS5, embora seja muito cedo agora.
De qualquer forma, vindo de uma forte experiência em PHP + Laravel, eu realmente aprecio os esforços desses caras. O site deles não diz muita coisa, mas parece indicar que eles são consultores, então eu recomendo que você entre em contato com eles se tiver projetos!
Agora, existem bons motivos para usar o TNTSearch em seus projetos?
Sim, existem:
- Codificado em PHP, para PHP, por PHP. O ecossistema PHP precisa de mais soluções dedicadas e de alta qualidade como esta.
- Recursos importantes, como pesquisa difusa, pesquisa geográfica e classificação de texto.
- Fácil de alterar o índice de pesquisa, o que é uma grande flexibilidade que falta em muitas soluções.
- Stemming, classificação BM25 e tokenização personalizada garantem alta precisão.
- Fácil implantação – como qualquer outro pacote Composer!
Você pode verificar o desempenho do motor aqui e ver por si mesmo o quão rápido e preciso ele é. Eu enfatizaria o aspecto PHP novamente: se você está mantendo um projeto em PHP, é interessante permanecer dentro do universo do PHP o máximo possível (por quê? Pense nos custos de um novo treinamento). E para esses casos, o TNTSearch traz uma proposta de valor difícil de recusar!
Vespa
O Vespa é uma opção abrangente e robusta. Assim como outras entradas nesta lista, ele é muito grande para ser resumido em poucas palavras. Mas eu preciso tentar, então, aqui vai. 🙂 O Vespa é um mecanismo de pesquisa, com certeza, mas usá-lo apenas como um mecanismo de pesquisa comum seria desperdiçar seu potencial.
O Vespa foi criado para lidar com quantidades massivas de dados (Big Data) e fornecer recursos orientados por Machine Learning e personalização sem fim.

O Vespa se posiciona como concorrente do Elasticsearch e dos bancos de dados tradicionais, e oferece uma comparação interessante sobre o que usar e quando.
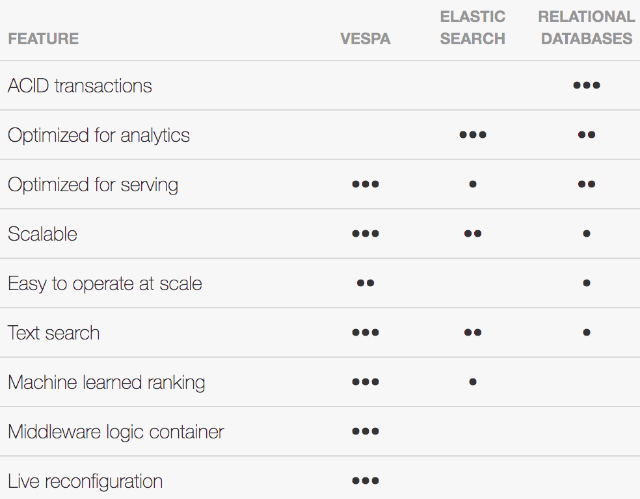
Como você pode ver, quanto mais próximo você deseja chegar de operações baseadas em aprendizado de máquina, mais sentido o Vespa faz. Como um mecanismo de pesquisa puro para uma empresa de pequeno e médio porte, não acho que ele tenha vantagens sobre outras opções.
Agora, considerando que você está gerando grandes quantidades de dados continuamente e deseja aprimorar a tomada de decisões por meio de IA/ML (uma descrição que se encaixa em muitas empresas SaaS hoje), veja por que o Vespa faz muito sentido:
- Código aberto: sem licenças esdrúxulas e sem contratos traiçoeiros. E nada a pagar por isso, embora eu sempre ressalte que as empresas devem contribuir com um valor regular para os projetos que mais utilizam (mesmo que seja apenas $50/mês já ajuda bastante).
- Tempo real: O Vespa é verdadeiramente em tempo real. Ele não apenas processa, analisa e pesquisa os dados assim que eles chegam; até mesmo sua configuração pode ser modificada em tempo real.
- Escalável e tolerante: O Vespa é facilmente escalável. Ele também responde muito bem ao desaparecimento repentino de nós, proporcionando alta confiabilidade.
- Classificação e recomendações: A classificação de pesquisa e as recomendações do Vespa podem ser combinadas com consultas estruturadas para fornecer resultados realmente precisos.
- IA/ML sem dores de cabeça: O Vespa vem com modelos de ML pré-treinados e de alta qualidade. Você não precisa contratar 20 cientistas de dados para limpar e usar seus dados.
- Plug-ins personalizados: Existe um conjunto completo de APIs que ajudam os desenvolvedores a criar plug-ins Java personalizados, caso precisem alterar o funcionamento do mecanismo.
O Vespa é enorme, sem dúvida, então ele é a escolha certa para equipes que já estão em um nível um pouco mais avançado – seja em tamanho da equipe, capacidade tecnológica, orçamentos de infraestrutura, volumes diários de dados ou qualquer outra coisa. Para esse segmento, o Vespa terá um ótimo desempenho e é altamente recomendado.
Ambar
Para algumas empresas, os dados de pesquisa ainda não são transformados e armazenados perfeitamente como documentos JSON; em vez disso, eles são uma bagunça no verdadeiro sentido da palavra – uma coleção caótica de todos os tipos de documentos como Word, PDF, arquivos HTML etc. Se você é uma dessas empresas e pensou que não há esperança para você, bem, diga olá ao Ambar!

A melhor característica do Ambar é a grande variedade de tipos de arquivos com os quais ele pode trabalhar:
- Formatos de arquivo do MS Office (.docx, .xlsx etc.), incluindo PowerPoint, Visio e Publisher!
- Formatos de arquivo OpenOffice
- Documentos PDF com OCR automático aplicado para extrair informações.
- Imagens
- Formatos de arquivo de e-mail, como PST (olá, usuários do Outlook!)
- Mensagens de e-mail com anexos
E as vantagens não param por aí. O Ambar consegue trabalhar com arquivos grandes (mais de 30 MB), arquivos ZIP e multi-threading para utilização total da CPU e resultados mais rápidos. Então, se você tem anos de documentos armazenados em algum disco em um servidor esquecido, está na hora de trazê-los de volta e alimentá-los no Ambar!
Conclusão
A pesquisa 🔎 é poderosa, a pesquisa é mágica e a pesquisa está em todos os lugares!
Pode até ser magia negra, mas hoje não há razão para que todos (com alguma ajuda de um desenvolvedor, claro) não possam aproveitar seus benefícios. De empresas a indivíduos e governos, os mecanismos de pesquisa desta lista fornecem uma proposta de esforço quase nulo com benefícios e impacto exponenciais.
Não hesite em adquirir um servidor na nuvem e instalar o software de pesquisa listado acima que você deseja experimentar.