A área da ciência de dados é ideal para aqueles que apreciam desvendar complexidades e encontrar informações valiosas em meio ao caos aparente.
É como procurar por agulhas em um palheiro, porém, os cientistas de dados não necessitam se sujar. Ao empregar ferramentas avançadas, com visualizações gráficas e analisando grandes conjuntos de números, eles se aprofundam em vastos volumes de dados, identificando insights cruciais com grande valor comercial.
Um profissional típico da ciência de dados deve ter em sua caixa de ferramentas ao menos um item de cada uma das seguintes categorias: bases de dados relacionais, bases de dados NoSQL, frameworks de big data, ferramentas de visualização, ferramentas de raspagem, linguagens de programação, IDEs e instrumentos de aprendizado profundo.
Bancos de Dados Relacionais
Uma base de dados relacional é uma compilação de dados organizados em tabelas com atributos. Essas tabelas podem ser interligadas, estabelecendo relações e restrições, criando assim um modelo de dados. Para interagir com bases de dados relacionais, é comum empregar uma linguagem chamada SQL (Linguagem de Consulta Estruturada).
Os aplicativos que gerenciam a estrutura e os dados dentro de bases de dados relacionais são conhecidos como RDBMS (Sistemas de Gerenciamento de Bancos de Dados Relacionais). Existem muitas dessas ferramentas, e as mais importantes têm recentemente direcionado sua atenção para o campo da ciência de dados, agregando funcionalidades para trabalhar com repositórios de big data e aplicar técnicas como análise de dados e aprendizado de máquina.
SQL Server
O RDBMS da Microsoft tem evoluído por mais de duas décadas, expandindo continuamente suas funcionalidades empresariais. Desde sua versão de 2016, o SQL Server disponibiliza um conjunto de serviços que inclui suporte para código R integrado. O SQL Server 2017 elevou o padrão ao renomear seus R Services para Machine Language Services e adicionar suporte para a linguagem Python (mais informações sobre essas duas linguagens adiante).
Com essas importantes adições, o SQL Server tem como alvo os cientistas de dados que podem não ter experiência com Transact SQL, a linguagem de consulta nativa do Microsoft SQL Server.
O SQL Server não é um produto gratuito. É possível adquirir licenças para instalá-lo em um Windows Server (o preço varia conforme o número de usuários simultâneos) ou utilizá-lo como um serviço pago, através da nuvem do Microsoft Azure. Aprender a utilizar o Microsoft SQL Server é acessível.
MySQL
No âmbito do software de código aberto, o MySQL é o líder em popularidade entre os RDBMSs. Apesar de ser atualmente propriedade da Oracle, ele permanece gratuito e de código aberto, sob os termos da Licença Pública Geral GNU. Muitos aplicativos web utilizam o MySQL como sua base de dados, devido à sua compatibilidade com o padrão SQL.
Sua popularidade é também atribuída à facilidade de instalação, à sua vasta comunidade de desenvolvedores, à extensa documentação e às ferramentas de terceiros, como o phpMyAdmin, que simplificam as tarefas diárias de gerenciamento. Embora o MySQL não possua funções nativas para realizar análise de dados, sua natureza aberta permite sua integração com praticamente qualquer ferramenta de visualização, relatórios e inteligência de negócios que você escolher.
PostgreSQL
Outra alternativa de RDBMS de código aberto é o PostgreSQL. Embora não seja tão popular quanto o MySQL, o PostgreSQL se destaca por sua flexibilidade, capacidade de expansão e suporte a consultas complexas, aquelas que vão além das instruções básicas como SELECT, WHERE e GROUP BY.
Essas características estão impulsionando seu crescimento em popularidade entre os cientistas de dados. Outro aspecto interessante é seu suporte a múltiplos ambientes, o que permite seu uso em ambientes de nuvem e on-premise, ou em uma combinação de ambos, comumente conhecidos como ambientes de nuvem híbrida.
O PostgreSQL consegue combinar o processamento analítico online (OLAP) com o processamento de transações online (OLTP), operando em um modo denominado processamento analítico/transacional híbrido (HTAP). Ele também é adequado para trabalhar com big data, graças à adição do PostGIS para dados geográficos e do JSON-B para documentos. O PostgreSQL também aceita dados não estruturados, permitindo que ele se encaixe em ambas as categorias: bancos de dados SQL e NoSQL.
Bancos de Dados NoSQL
Também conhecido como banco de dados não relacional, este tipo de repositório de dados oferece acesso mais rápido a estruturas de dados que não são tabulares. Alguns exemplos dessas estruturas incluem gráficos, documentos, colunas largas e pares chave-valor, entre outras. Os armazenamentos de dados NoSQL podem priorizar outros benefícios, como disponibilidade, particionamento e velocidade de acesso, em detrimento da consistência dos dados.
Como não há SQL em armazenamentos de dados NoSQL, a única maneira de consultar este tipo de banco de dados é através de linguagens de baixo nível, e não existe uma linguagem tão amplamente aceita quanto SQL. Além disso, não existem especificações padronizadas para NoSQL. Por esta razão, alguns bancos de dados NoSQL estão começando a adicionar suporte para scripts SQL.
MongoDB
O MongoDB é um sistema de banco de dados NoSQL popular, que armazena dados em formato de documentos JSON. Seu foco está na escalabilidade e na flexibilidade para armazenar dados de forma não estruturada. Isso implica que não há uma lista fixa de campos que deva ser observada em todos os elementos armazenados. Além disso, a estrutura dos dados pode ser alterada ao longo do tempo, o que, em um banco de dados relacional, implicaria em um alto risco de afetar as aplicações em execução.

A tecnologia no MongoDB permite indexação, consultas ad-hoc e agregação, que fornecem uma base sólida para a análise de dados. A natureza distribuída do banco de dados proporciona alta disponibilidade, dimensionamento e distribuição geográfica sem a necessidade de ferramentas complexas.
Redis
Esta é outra opção de código aberto na área de NoSQL. Basicamente, trata-se de um armazenamento de estrutura de dados que opera na memória e, além de oferecer serviços de banco de dados, também funciona como memória cache e agente de mensagens.

Ele suporta uma variedade de estruturas de dados não convencionais, incluindo hashes, índices geoespaciais, listas e conjuntos ordenados. É adequado para ciência de dados devido ao seu alto desempenho em tarefas com uso intensivo de dados, como calcular interseções de conjuntos, classificar listas extensas ou gerar classificações complexas. O motivo do excelente desempenho do Redis é sua operação na memória. Ele pode ser configurado para persistir os dados seletivamente.
Frameworks de Big Data
Imagine que você precisa analisar os dados gerados pelos usuários do Facebook durante um mês. Estamos falando de fotos, vídeos, mensagens, tudo isso. Considerando que mais de 500 terabytes de dados são adicionados diariamente à rede social por seus usuários, é difícil mensurar o volume representado por um mês inteiro de seus dados.
Para manipular essa imensa quantidade de dados de maneira eficaz, você precisa de uma estrutura adequada, capaz de computar estatísticas em uma arquitetura distribuída. Existem dois frameworks que lideram o mercado: Hadoop e Spark.
Hadoop
Como um framework de big data, o Hadoop lida com as complexidades associadas à recuperação, processamento e armazenamento de grandes volumes de dados. O Hadoop opera em um ambiente distribuído, composto por clusters de computadores que processam algoritmos simples. Existe um algoritmo de orquestração, chamado MapReduce, que divide tarefas extensas em pequenas partes e, em seguida, distribui essas pequenas tarefas entre os clusters disponíveis.

O Hadoop é recomendado para repositórios de dados de nível empresarial que necessitam de acesso rápido e alta disponibilidade, tudo isso a um custo reduzido. No entanto, é necessário um administrador Linux com profundo conhecimento de Hadoop para manter a estrutura em funcionamento.
Spark
O Hadoop não é o único framework disponível para manipulação de big data. Outro grande nome nesta área é o Spark. O mecanismo Spark foi projetado para superar o Hadoop em termos de velocidade de análise e facilidade de uso. Aparentemente, ele atingiu esse objetivo: algumas comparações indicam que o Spark funciona até 10 vezes mais rápido que o Hadoop ao trabalhar em disco e 100 vezes mais rápido quando opera na memória. Além disso, requer um número menor de máquinas para processar a mesma quantidade de dados.

Além da velocidade, outro benefício do Spark é o suporte ao processamento de fluxo. Este tipo de processamento de dados, também chamado de processamento em tempo real, envolve entrada e saída contínua de dados.
Ferramentas de Visualização
Uma piada comum entre cientistas de dados é que, se você “torturar” os dados por tempo suficiente, eles confessarão o que você precisa saber. Neste caso, “torturar” significa manipular os dados transformando-os e filtrando-os para melhor visualizá-los. É aqui que as ferramentas de visualização de dados entram em cena. Essas ferramentas recebem dados pré-processados de diversas fontes e mostram suas verdades reveladas em formatos gráficos e compreensíveis.
Existem centenas de ferramentas que se encaixam nesta categoria. Quer goste ou não, a mais utilizada é o Microsoft Excel e suas ferramentas de gráficos. Os gráficos do Excel são acessíveis a qualquer pessoa que use o Excel, mas têm funcionalidade limitada. O mesmo se aplica a outros aplicativos de planilhas, como o Google Sheets e o LibreOffice. No entanto, estamos falando aqui de ferramentas mais específicas, especialmente adaptadas para inteligência de negócios (BI) e análise de dados.
Power BI
Recentemente, a Microsoft lançou seu aplicativo de visualização Power BI. Ele pode receber dados de diversas fontes, como arquivos de texto, bancos de dados, planilhas e muitos serviços de dados online, incluindo Facebook e Twitter, e usá-los para gerar painéis com gráficos, tabelas, mapas e vários outros objetos de visualização. Os objetos do painel são interativos, o que significa que você pode clicar em uma série de dados em um gráfico para selecioná-la e utilizá-la como filtro para os demais objetos no painel.
O Power BI é uma combinação de um aplicativo para desktop do Windows (parte do pacote Office 365), um aplicativo Web e um serviço online para publicar os painéis na Web e compartilhá-los com seus usuários. O serviço permite que você crie e gerencie permissões para conceder acesso aos painéis apenas a determinadas pessoas.
Tableau
O Tableau é outra opção para criar painéis interativos a partir de uma combinação de várias fontes de dados. Ele também oferece uma versão para desktop, uma versão web e um serviço online para compartilhar os painéis que você cria. Ele funciona de forma intuitiva, “com a maneira como você pensa” (segundo a própria empresa), e é fácil de usar para pessoas não técnicas, o que é aprimorado por meio de muitos tutoriais e vídeos online.
Alguns dos recursos mais notáveis do Tableau são seus conectores de dados ilimitados, seus dados ativos e na memória e seus designs otimizados para dispositivos móveis.
QlikView
O QlikView oferece uma interface de usuário clara e direta para auxiliar os analistas a descobrir novas informações em dados existentes por meio de elementos visuais facilmente compreensíveis para todos.
Esta ferramenta é conhecida por ser uma das plataformas de inteligência de negócios mais flexíveis. Ela fornece um recurso denominado Pesquisa Associativa, que ajuda você a se concentrar nos dados mais importantes, economizando o tempo que levaria para encontrá-los por conta própria.
Com o QlikView, você pode colaborar com colegas em tempo real, realizando análises comparativas. Todos os dados relevantes podem ser agrupados em um aplicativo, com recursos de segurança que restringem o acesso aos dados.
Ferramentas de Raspagem
Nos primórdios da internet, os rastreadores da web começaram a navegar pelas redes, coletando informações em seu caminho. Com a evolução da tecnologia, o termo “web crawling” mudou para “web scraping”, mas o significado permanece o mesmo: extrair automaticamente informações de sites. Para fazer web scraping, você utiliza processos automatizados, ou bots, que saltam de uma página da web para outra, extraindo dados delas e exportando-os para diferentes formatos ou inserindo-os em bancos de dados para análise posterior.
Abaixo, apresentamos um resumo das características de três dos raspadores de web mais populares disponíveis atualmente.
Octoparse
O raspador web Octoparse oferece algumas funcionalidades interessantes, incluindo ferramentas internas para obter informações de sites que não facilitam o trabalho dos bots de raspagem. Trata-se de um aplicativo para desktop que não exige codificação, com uma interface amigável que permite visualizar o processo de extração por meio de um designer gráfico de fluxo de trabalho.
Juntamente com o aplicativo autônomo, o Octoparse oferece um serviço baseado em nuvem para acelerar o processo de extração de dados. Os usuários podem experimentar um ganho de velocidade de 4x a 10x ao usar o serviço de nuvem em vez do aplicativo de desktop. Se você optar pela versão para desktop, poderá usar o Octoparse gratuitamente. No entanto, se preferir usar o serviço em nuvem, terá que escolher um dos planos pagos.
Content Grabber
Se você está procurando uma ferramenta de raspagem com muitos recursos, deve considerar o Content Grabber. Ao contrário do Octoparse, para usar o Content Grabber, é necessário ter conhecimentos avançados de programação. Em contrapartida, você obtém edição de scripts, interfaces de depuração e outras funcionalidades avançadas. Com o Content Grabber, você pode usar linguagens .Net para escrever expressões regulares. Assim, você não precisa gerar as expressões usando uma ferramenta integrada.
A ferramenta oferece uma API (Interface de Programação de Aplicativos) que você pode usar para adicionar recursos de raspagem aos seus aplicativos de desktop e web. Para usar esta API, os desenvolvedores precisam obter acesso ao serviço Content Grabber Windows.
ParseHub
Este raspador pode lidar com uma extensa variedade de tipos de conteúdo, incluindo fóruns, comentários aninhados, calendários e mapas. Ele também consegue lidar com páginas que contêm autenticação, JavaScript, Ajax e muito mais. O ParseHub pode ser usado como um aplicativo Web ou como um aplicativo para desktop, que pode ser executado no Windows, macOS X e Linux.
Assim como o Content Grabber, é aconselhável ter algum conhecimento de programação para aproveitar ao máximo o ParseHub. Ele possui uma versão gratuita, limitada a 5 projetos e 200 páginas por execução.
Linguagens de Programação
Assim como a linguagem SQL, mencionada anteriormente, é projetada especificamente para trabalhar com bancos de dados relacionais, existem outras linguagens criadas com foco específico na ciência de dados. Essas linguagens permitem que os desenvolvedores escrevam programas que lidam com análises massivas de dados, como estatísticas e aprendizado de máquina.
O SQL também é considerado uma habilidade importante que os desenvolvedores devem ter para fazer ciência de dados, mas isso ocorre porque muitas organizações ainda possuem muitos dados em bancos de dados relacionais. As linguagens de ciência de dados “verdadeiras” são R e Python.
Python

O Python é uma linguagem de programação de alto nível, interpretada e de uso geral, adequada para o desenvolvimento rápido de aplicações. Possui uma sintaxe simples e fácil de aprender, o que permite uma curva de aprendizado rápida e redução nos custos de manutenção do programa. Existem muitas razões pelas quais ela é a linguagem preferida para a ciência de dados. Para citar algumas: potencial de script, verbosidade, portabilidade e desempenho.
Essa linguagem é um bom ponto de partida para cientistas de dados que planejam experimentar muito antes de começar o trabalho real e árduo de processamento de dados e que desejam desenvolver aplicativos completos.
R
A linguagem R é utilizada principalmente para o processamento de dados estatísticos e gráficos. Embora não seja destinada ao desenvolvimento de aplicativos completos, como seria o caso do Python, o R se tornou muito popular nos últimos anos devido ao seu potencial para mineração de dados e análise de dados.

Graças a uma crescente biblioteca de pacotes disponíveis gratuitamente, que expandem sua funcionalidade, o R é capaz de realizar todos os tipos de trabalho de processamento de dados, incluindo modelagem linear/não linear, classificação, testes estatísticos, etc.
Não é uma linguagem fácil de aprender, mas uma vez que você se familiarize com sua filosofia, estará realizando computação estatística como um profissional.
IDEs
Se você está pensando seriamente em se dedicar à ciência de dados, precisará escolher cuidadosamente um ambiente de desenvolvimento integrado (IDE) que atenda às suas necessidades, pois você e seu IDE passarão muito tempo trabalhando juntos.
Um IDE ideal deve reunir todas as ferramentas que você precisa em seu trabalho diário como programador: um editor de texto com realce de sintaxe e preenchimento automático, um depurador eficiente, um navegador de objetos e acesso fácil a ferramentas externas. Além disso, ele deve ser compatível com a linguagem de sua preferência, portanto, é uma boa ideia escolher seu IDE depois de saber qual linguagem você usará.
Spyder
Este IDE genérico é voltado principalmente para cientistas e analistas que também precisam codificar. Para deixá-los confortáveis, ele não se limita à funcionalidade de IDE – ele também fornece ferramentas para exploração/visualização de dados e execução interativa, como pode ser encontrado em um pacote científico. O editor no Spyder suporta várias linguagens e adiciona um navegador de classe, divisão de janela, salto para definição, autocompletar código e até mesmo uma ferramenta de análise de código.
O depurador ajuda a rastrear cada linha de código interativamente e um criador de perfil ajuda a encontrar e eliminar ineficiências.
PyCharm
Se você programa em Python, é provável que seu IDE de escolha seja o PyCharm. Ele possui um editor de código inteligente com pesquisa inteligente, conclusão de código e detecção e correção de erros. Com apenas um clique, você pode pular do editor de código para qualquer janela relacionada ao contexto, incluindo teste, supermétodo, implementação, declaração e muito mais. O PyCharm suporta o Anaconda e vários pacotes científicos, como NumPy e Matplotlib, para citar apenas dois deles.
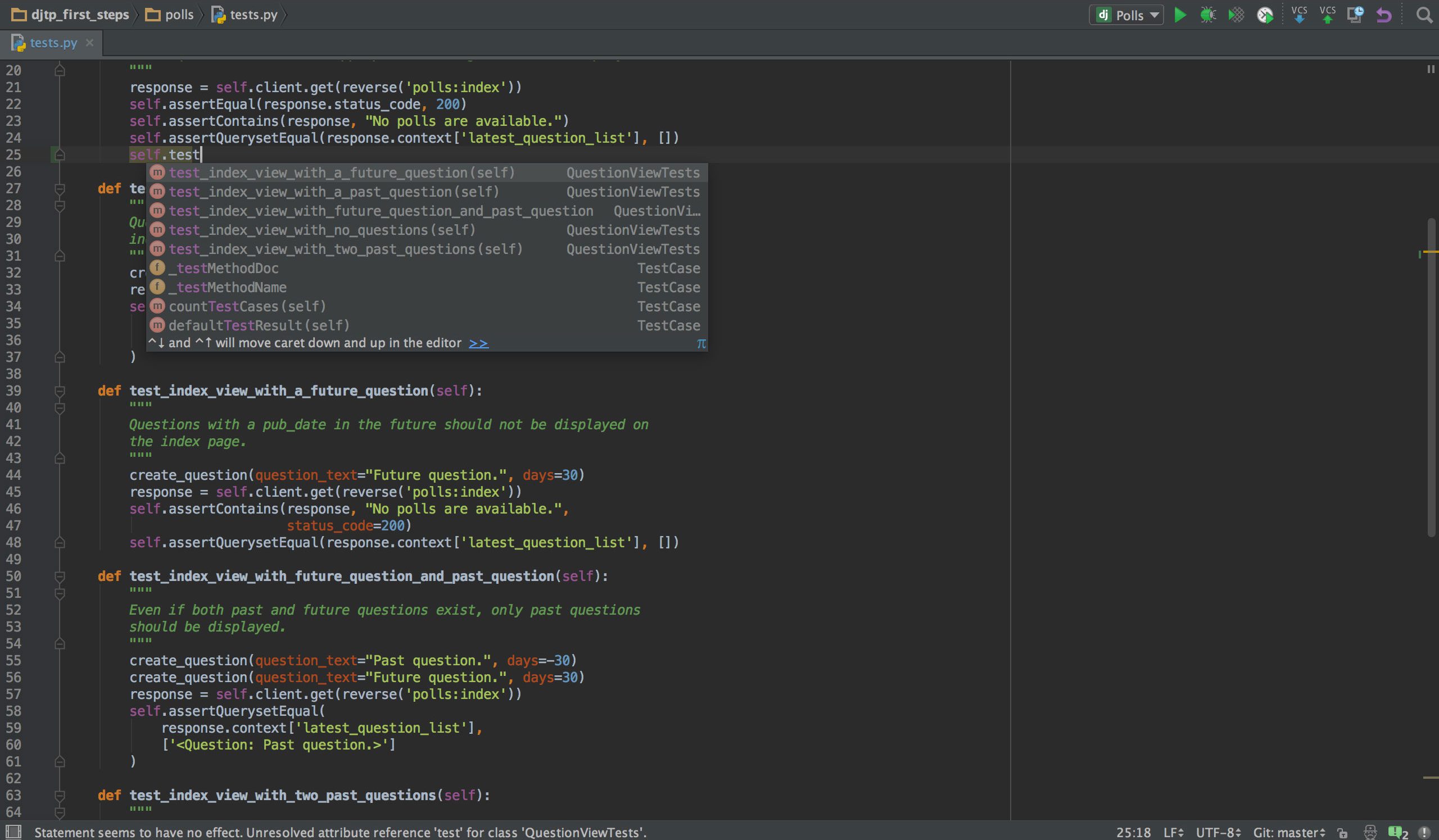
Ele oferece integração com os mais importantes sistemas de controle de versão, e também com um test runner, um profiler e um debugger. Para completar, ele também se integra com Docker e Vagrant para fornecer desenvolvimento e conteinerização entre plataformas.
RStudio
Para os cientistas de dados que preferem a equipe R, o IDE escolhido deve ser o RStudio, devido a seus muitos recursos. Você pode instalá-lo em um desktop com Windows, macOS ou Linux, ou executá-lo em um navegador da Web se não quiser instalá-lo localmente. Ambas as versões oferecem vantagens como realce de sintaxe, recuo inteligente e conclusão de código. Há um visualizador de dados integrado que é útil quando você precisa navegar por dados tabulares.
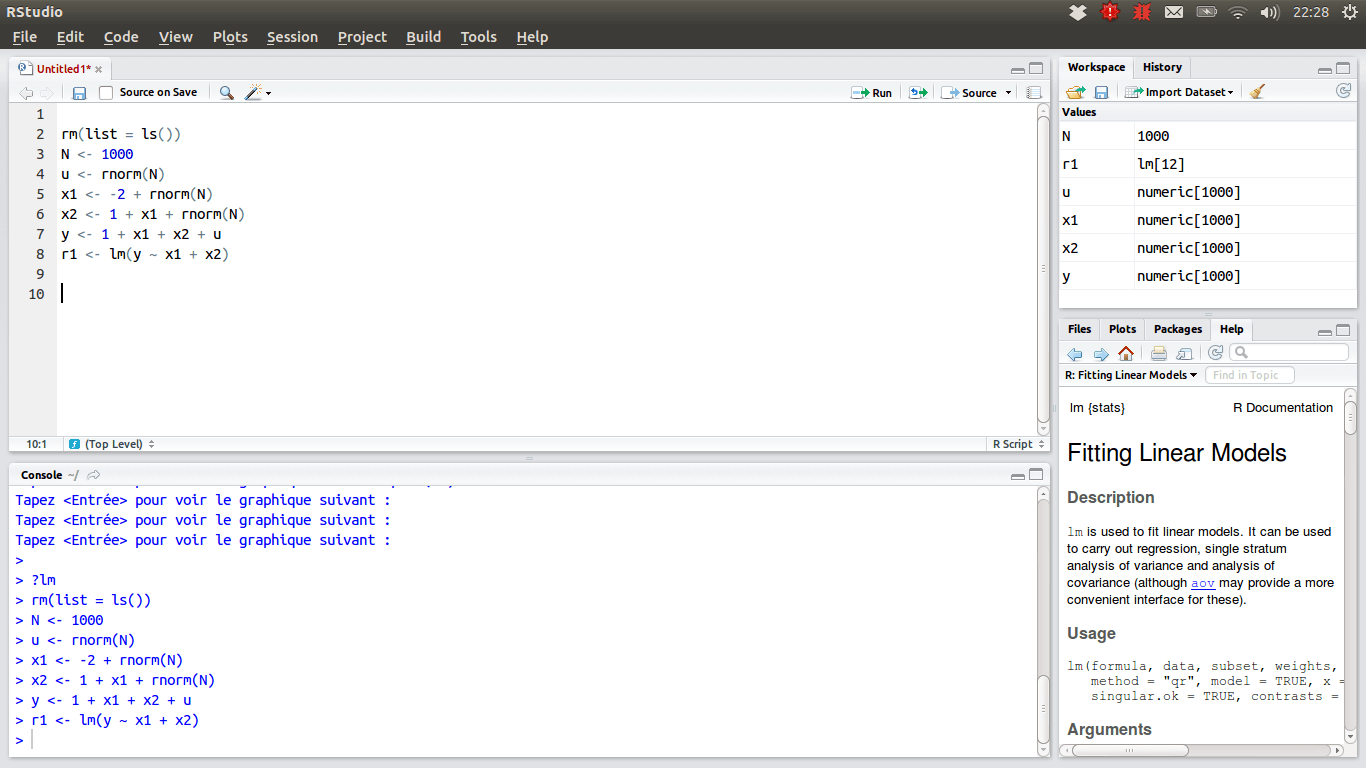
O modo de depuração permite visualizar como os dados estão sendo atualizados dinamicamente ao executar um programa ou script passo a passo. Para controle de versão, o RStudio integra suporte para SVN e Git. Uma boa vantagem é a possibilidade de criar gráficos interativos, com as bibliotecas Shiny e outras.
Sua caixa de ferramentas pessoal
Neste ponto, você deve ter uma visão completa das ferramentas que você deve conhecer para se destacar em ciência de dados. Além disso, esperamos ter fornecido informações suficientes para decidir qual é a opção mais adequada em cada categoria de ferramenta. Agora, a decisão é sua. A ciência de dados é uma área promissora para desenvolver uma carreira. Mas se você quiser ter sucesso, precisa acompanhar as mudanças nas tendências e tecnologias, que acontecem quase diariamente.