

Prepare-se para saber tudo sobre o futuro da próxima geração de bancos de dados, ou seja, bancos de dados sem servidor!
Qualquer banco de dados que siga os princípios fundamentais da computação sem servidor é um banco de dados sem servidor. O Serverless Database foi criado para cargas de trabalho imprevisíveis e que podem mudar rapidamente.
Serverless não significa que nenhum servidor é necessário. Isso significa que os servidores subjacentes não precisam ser gerenciados, provisionados ou pagos por você.
Você paga pelos recursos que usa com base nas capacidades de CPU e RAM e no nível de atividade.
últimas postagens
Como funciona o banco de dados sem servidor
O modelo de banco de dados sem servidor depende da separação de processamento e armazenamento. Você precisa criar um endpoint e definir as capacidades mínima e máxima.
Crédito da imagem: Simform
Em seguida, você pode emitir consultas para o endpoint. Esse proxy atua como um link para um grande número de recursos de banco de dados. Isso permite que suas conexões permaneçam intactas, mesmo que as operações de dimensionamento ocorram nos bastidores.
Separar o armazenamento do processamento tem outra vantagem. É possível reduzir o processamento para zero e você só precisa pagar pelo armazenamento. O dimensionamento pode ser feito em apenas 5 segundos, dependendo da aplicação. Você também tem acesso a um conjunto de recursos “quentes” prontos para ajudá-lo em suas necessidades.
Banco de dados sem servidor: vantagens

Eficiência de custos
Um número fixo de servidores é mais caro do que um banco de dados sem servidor e leva mais tempo para comprar. Pode ser mais barato do que configurar um grupo de dimensionamento automático e também é mais econômico porque o empacotamento de recursos da máquina o torna mais eficiente.
Isso inclui licenciamento, instalação, manutenção, suporte e aplicação de patches. Você é cobrado apenas pelo tempo e memória usados para executar seu código.
Escalabilidade automatizada
Os desenvolvedores não precisam configurar ou configurar nenhuma política ou sistema de dimensionamento automático para obter dimensionamento sem servidor com base na carga de trabalho. Tudo isso recai sobre o provedor de nuvem, que deve atender às demandas reais com os poderes de desempenho adequados.
Implantações e atualizações rápidas
A infraestrutura sem servidor elimina a necessidade de fazer upload de código para servidores e definir configurações de back-end para criar um aplicativo funcional. É fácil para os desenvolvedores fazer upload de pequenos trechos de código e, em seguida, lançar um novo produto. Os desenvolvedores podem carregar os dois códigos de uma só vez e uma função por vez.
Isso facilita atualizar, corrigir, corrigir ou adicionar novos recursos rapidamente a um aplicativo. Os desenvolvedores podem fazer pequenas alterações em um aplicativo em vez de atualizar o aplicativo inteiro.
Maior produtividade
Você obterá mais do seu sistema serverless se gastar menos tempo nele, se esforçar menos em áreas onde a interação é necessária e contratar uma equipe de profissionais com o tamanho ideal para obter melhores resultados.
Banco de dados sem servidor: Desvantagens
Problemas de partida a frio
O manuseio de partidas a frio é um dos aspectos mais importantes e desafiadores nesse campo. Um banco de dados sem servidor que não está sendo usado simplesmente ficará ocioso para conservar recursos e evitar desempenho desnecessário.
O sistema “acorda” e precisa de tempo para reiniciar todos os seus processos. Você pode experimentar atrasos e tempos de resposta lentos se for a primeira pessoa a tocar no sistema na inicialização a frio.
Dificuldade em testar e depurar aplicativos
O modelo sem servidor apresenta outro desafio. É difícil replicar um ambiente sem servidor para testar e monitorar o desempenho do código antes que ele entre no ar. Isso se deve em parte ao fato de que os desenvolvedores não têm acesso aos serviços de back-end do provedor de nuvem.
Para depurar sistemas complexos de forma profunda e eficiente, você não pode usar um criador de perfil ou um depurador. Você tem a opção de experimentar ferramentas de terceiros cada vez mais disponíveis no mercado.
Mais monitoramento
As soluções sem servidor exigem que você coloque mais ênfase no monitoramento e na indicação de problemas de desempenho ou uso excessivo de recursos. Isso se deve em grande parte ao fato de que as soluções em nuvem raramente são de código aberto.
Bloqueio do fornecedor
Ao migrar para outro provedor, escolher um modelo sem servidor pode apresentar problemas. Isso se deve ao fato de cada provedor ter fluxos de trabalho e recursos diferentes.
Recursos do banco de dados sem servidor
Os bancos de dados sem servidor oferecem alguns dos recursos mais interessantes, como:
#1. Arquitetura multilocatário
Os bancos de dados sem servidor oferecem a vantagem de poder usar um único recurso de pool que pode ser usado para vários projetos em sua organização. Isso é uma grande vantagem para os desenvolvedores, pois eles não precisam criar fontes de dados isoladas para aplicativos específicos.
A arquitetura multilocatário torna isso possível. Os desenvolvedores podem definir, configurar e implantar vários aplicativos em um único cluster de banco de dados.
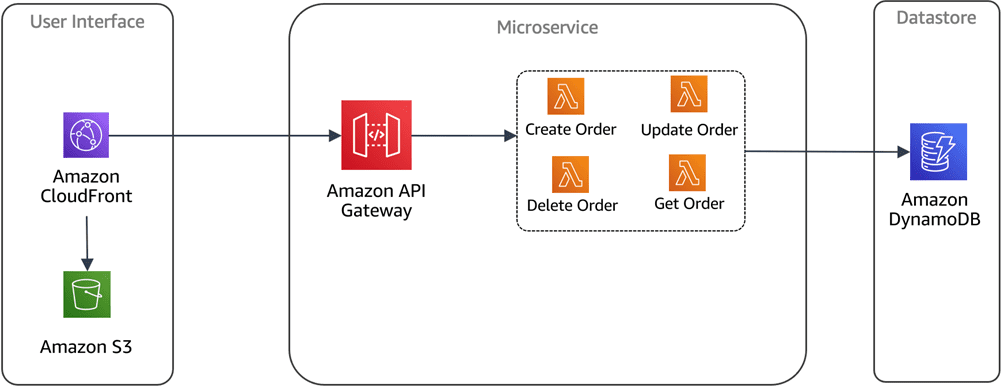 Crédito da imagem: AWS
Crédito da imagem: AWS
#2. Distribuição geográfica
Como a maioria das empresas opera globalmente, é essencial que os dados estejam disponíveis em todo o mundo. A experiência em tempo real pode ser aprimorada pela proximidade dos data centers. Um ponto de falha também é eliminado, portanto, a possibilidade de uma interrupção é muito improvável.
Os bancos de dados sem servidor permitem que você replique vários conjuntos de dados em todo o mundo sem nenhuma ferramenta adicional ou desenvolvimento personalizado.
#3. Pouca ou nenhuma administração manual do servidor
Sem servidor é um nome impróprio. É uma coleção de servidores que foram separados e automatizados para facilitar seu gerenciamento. Todas as tarefas manuais, como provisionamento, planejamento de capacidade, dimensionamento, manutenção, atualizações e assim por diante, ainda são executadas nos bastidores. Eles são muito fáceis de usar e requerem pouca ou nenhuma intervenção manual.
#4. Faturamento baseado no consumo
O banco de dados sem servidor, pois suas cobranças são baseadas no uso, é o mais econômico. O armazenamento não é necessário. Você só paga pelo que usa. Se quiser evitar estouros no orçamento, você pode definir um limite de gastos.
Bancos de dados sem servidor relacionais x não relacionais

Os dados da era digital podem ser classificados em dados operacionais e analíticos. Vamos dar uma olhada em algumas opções de banco de dados diferentes que os desenvolvedores buscam e ver como elas se comparam.
A maioria das empresas requer sistemas OLTP (operacional) e OLAP (analítico) para armazenar seus dados. Eles podem usar um banco de dados relacional ou não relacional para dar suporte às suas necessidades de negócios.
Banco de dados relacional sem servidor
Um banco de dados relacional é um tipo de banco de dados que organiza e coleta dados de acordo com relacionamentos predefinidos entre os principais pontos de dados. Ele organiza os dados para que vários usuários possam localizar e classificar os dados sem alterar a categorização lógica dos dados.
Elimina a duplicação de dados em processos de armazenamento. Linguagem de consulta estruturada é a interface de programa de aplicativo (API) para um banco de dados relacional.
Este sistema apresenta os dados em formato tabular. Esta tabela representa uma entidade, como um produto ou aplicativo móvel. Cada linha é o valor real e cada linha possui um identificador exclusivo que é uma instância desse tipo de entidade. É por isso que os registros são chamados.
As colunas, por outro lado, contêm os atributos dos dados. Eles são o valor real da entidade. O acesso aos dados é possível sem a necessidade de reorganizar a tabela do banco de dados.
Banco de dados sem servidor NoSQL (não relacional)
Os bancos de dados não relacionais (NoSQL) têm maior probabilidade de serem distribuídos do que os bancos de dados SQL. Pode ser usado com um grande número de bancos de dados. As empresas precisam usar recursos modernos, como bancos de dados NoSQL, para criar aplicativos nativos da nuvem.
Os bancos de dados sem servidor NoSQL são usados em aplicativos da Web em tempo real. Eles são simples em design e podem lidar rapidamente com grandes quantidades de dados com escala horizontal. Isso é ideal para situações em que o esquema não é claro e altas taxas de ingestão podem ser necessárias.
Os bancos de dados sem servidor NoSQL são muito populares, pois armazenam grandes quantidades de dados de várias formas, incluindo gráficos, documentos, pares de chave/valor e estruturas de dados orientadas a colunas. Isso torna mais fácil para os desenvolvedores modificar a estrutura de dados.
Por que alguém deve usar bancos de dados sem servidor?
Bancos de dados sem servidor são uma ótima opção para equipes pequenas que não têm equipe suficiente para gerenciar e dimensionar bancos de dados tradicionais. Bancos de dados sem servidor requerem pouca infraestrutura e manutenção. Isso significa que sua equipe precisará gastar menos tempo mantendo o sistema. Também é fácil criar novas tabelas e testar novos recursos usando um banco de dados sem servidor.
Por fim, custos. Os bancos de dados sem servidor permitem que você pague apenas pelo que usar, sem precisar configurar e ajustar os custos como os bancos de dados tradicionais. Bancos de dados sem servidor são ótimos para desenvolvedores e equipes que precisam lançar novos recursos rapidamente.
Casos de uso de banco de dados sem servidor

#1. Novos Aplicativos
Alguns minutos de uso ao longo de uma semana ou dia. Se você possui um blog com pouco tráfego e quer pagar apenas pelo tempo que algum usuário acessa seu site, esta é uma opção. Você paga por segundo pelos recursos do banco de dados que usa.
#2. Redimensionamento elástico para transmissão de vídeo ao vivo
A transmissão de vídeo ao vivo é possibilitada pela arquitetura sem servidor. Vários membros da audiência podem interagir em cenários de transmissão de vídeo ao vivo. O host pode estar conectado a vários microfones simultaneamente. Um host pode conectar vários membros da platéia ou amigos à tela e, em seguida, sintetizar a imagem em um cenário que é apresentado aos espectadores da transmissão ao vivo.
#3. Aplicativos usados com pouca frequência
Se você tem um aplicativo do qual se orgulha e não sabe como será recebido, e porque não deseja que o aplicativo falhe, este método é para você. Basta criar um endpoint e o banco de dados sem servidor será dimensionado automaticamente para atender às necessidades do seu aplicativo.
#4. Internet das Coisas (IoT)
A IoT pode ser descrita como um termo que descreve dispositivos encontrados em residências hoje que podem se conectar à internet para executar várias funções. O FaaS está sendo cada vez mais usado por esses dispositivos para realizar suas tarefas. Eles só enviam e recebem dados quando um evento os aciona.
As empresas economizam dinheiro por não terem que pagar mais pelo poder de computação que não estão usando. O FaaS possibilita escalar rápida e automaticamente, para que os desenvolvedores não precisem se preocupar com padrões de uso imprevisíveis.
Conclusão
Esses cenários mostram que a arquitetura sem servidor traz muitos benefícios para desenvolvedores e empresas. Bancos de dados sem servidor podem melhorar sua velocidade de computação e resiliência, reduzindo o tempo e o custo de dimensionamento e recursos. Existem muitos tipos de bancos de dados sem servidor, relacionais e não relacionais. No entanto, todos eles têm o mesmo objetivo: escalar sob demanda sem adicionar ônus de gerenciamento e reduzir custos em apenas