
Uma matriz de confusão é uma ferramenta para avaliar o desempenho do tipo de classificação de algoritmos de aprendizado de máquina supervisionado.
últimas postagens
O que é uma Matriz de Confusão?
Nós, humanos, percebemos as coisas de forma diferente – até verdades e mentiras. O que pode parecer uma linha de 10 cm para mim pode parecer uma linha de 9 cm para você. Mas o valor real pode ser 9, 10 ou qualquer outra coisa. O que achamos é o valor previsto!
Como o cérebro humano pensa
Assim como nosso cérebro aplica nossa própria lógica para prever algo, as máquinas aplicam vários algoritmos (chamados de algoritmos de aprendizado de máquina) para chegar a um valor previsto para uma pergunta. Novamente, esses valores podem ser iguais ou diferentes do valor real.
Em um mundo competitivo, gostaríamos de saber se nossa previsão está certa ou não para entender nosso desempenho. Da mesma forma, podemos determinar o desempenho de um algoritmo de aprendizado de máquina por quantas previsões ele fez corretamente.
Então, o que é um algoritmo de aprendizado de máquina?
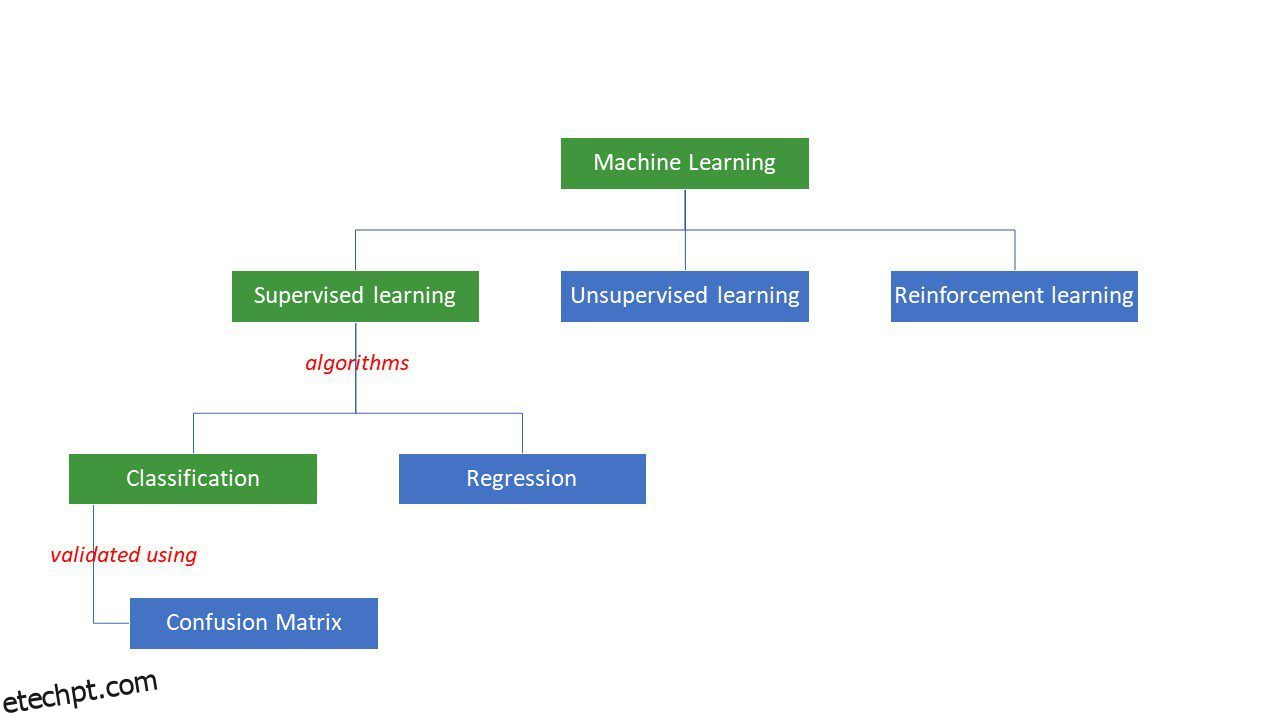
As máquinas tentam chegar a certas respostas para um problema aplicando certa lógica ou conjunto de instruções, chamados algoritmos de aprendizado de máquina. Os algoritmos de aprendizado de máquina são de três tipos – supervisionados, não supervisionados ou de reforço.
 Tipos de algoritmos de aprendizado de máquina
Tipos de algoritmos de aprendizado de máquina
Os tipos mais simples de algoritmos são supervisionados, onde já sabemos a resposta, e treinamos as máquinas para chegar a essa resposta treinando o algoritmo com muitos dados – da mesma forma que uma criança diferenciaria pessoas de diferentes faixas etárias por olhando para suas características uma e outra vez.
Os algoritmos de ML supervisionados são de dois tipos – classificação e regressão.
Os algoritmos de classificação classificam ou classificam os dados com base em algum conjunto de critérios. Por exemplo, se você deseja que seu algoritmo agrupe clientes com base em suas preferências alimentares – aqueles que gostam de pizza e aqueles que não gostam de pizza, você usaria um algoritmo de classificação como árvore de decisão, floresta aleatória, Bayes ingênuo ou SVM (Suporte Máquina Vetorial).
Qual desses algoritmos faria o melhor trabalho? Por que você deve escolher um algoritmo sobre o outro?
Digite a matriz de confusão….
Uma matriz de confusão é uma matriz ou tabela que fornece informações sobre a precisão de um algoritmo de classificação na classificação de um conjunto de dados. Bem, o nome não é para confundir humanos, mas muitas previsões incorretas provavelmente significam que o algoritmo estava confuso😉!
Assim, uma matriz de confusão é um método de avaliação do desempenho de um algoritmo de classificação.
Como?
Digamos que você aplicou algoritmos diferentes ao nosso problema binário mencionado anteriormente: classificar (segregar) as pessoas com base no fato de gostarem ou não de pizza. Para avaliar o algoritmo que tem os valores mais próximos da resposta correta, você usaria uma matriz de confusão. Para um problema de classificação binária (like/dislike, true/false, 1/0), a matriz de confusão fornece quatro valores de grade, a saber:
- Verdadeiro Positivo (TP)
- Verdadeiro Negativo (TN)
- Falso Positivo (FP)
- Falso Negativo (FN)
Quais são as quatro grades em uma matriz de confusão?
Os quatro valores determinados usando a matriz de confusão formam as grades da matriz.
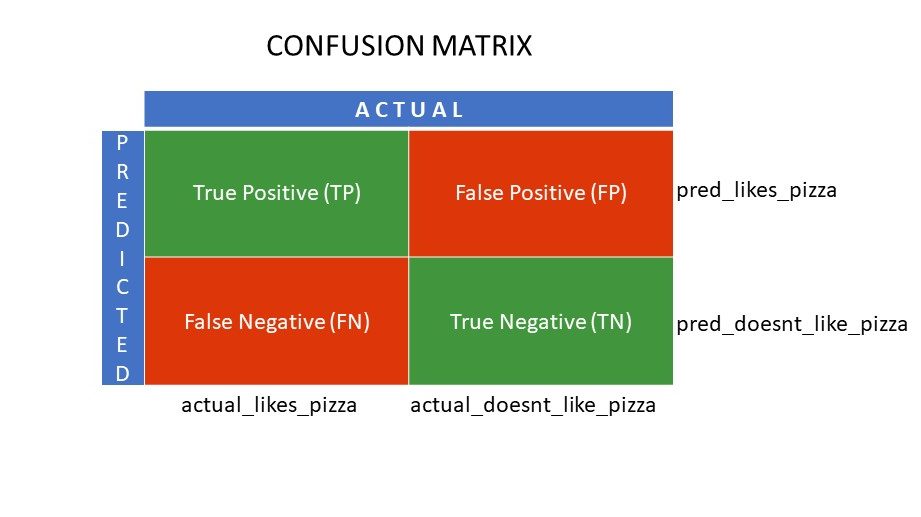 Matrizes de confusão
Matrizes de confusão
Verdadeiro Positivo (TP) e Verdadeiro Negativo (TN) são os valores corretamente previstos pelo algoritmo de classificação,
- TP representa quem gosta de pizza, e o modelo os classificou corretamente,
- TN representa aqueles que não gostam de pizza, e o modelo os classificou corretamente,
Falso Positivo (FP) e Falso Negativo (FN) são os valores que são preditos erroneamente pelo classificador,
- FP representa aqueles que não gostam de pizza (negativo), mas o classificador previu que eles gostam de pizza (erradamente positivo). FP também é chamado de erro tipo I.
- FN representa aqueles que gostam de pizza (positivo), mas o classificador previu que não (erroneamente negativo). FN também é chamado de erro tipo II.
Para entender melhor o conceito, vamos pegar um cenário da vida real.
Digamos que você tenha um conjunto de dados de 400 pessoas que foram submetidas ao teste Covid. Agora, você obteve os resultados de vários algoritmos que determinaram o número de pessoas Covid positivas e Covid negativas.
Aqui estão as duas matrizes de confusão para comparação:
Ao olhar para ambos, você pode ficar tentado a dizer que o primeiro algoritmo é mais preciso. Mas, para obter um resultado concreto, precisamos de algumas métricas que possam medir a exatidão, precisão e muitos outros valores que comprovem qual algoritmo é melhor.
Métricas usando matriz de confusão e seu significado
As principais métricas que nos ajudam a decidir se o classificador fez as previsões corretas são:
#1. Recordação/Sensibilidade
Recall ou Sensibilidade ou Taxa de Verdadeiro Positivo (TPR) ou Probabilidade de Detecção é a razão das previsões positivas corretas (TP) para o total de positivos (ou seja, TP e FN).
R = TP/(TP + FN)
Recall é a medida de resultados positivos corretos retornados do número de resultados positivos corretos que poderiam ter sido produzidos. Um valor mais alto de Recall significa que há menos falsos negativos, o que é bom para o algoritmo. Use Recall quando conhecer os falsos negativos é importante. Por exemplo, se uma pessoa tem vários bloqueios no coração e o modelo mostra que está absolutamente bem, pode ser fatal.
#2. Precisão
A precisão é a medida dos resultados positivos corretos de todos os resultados positivos previstos, incluindo os verdadeiros e falsos positivos.
Pr = TP/(TP + FP)
A precisão é muito importante quando os falsos positivos são importantes demais para serem ignorados. Por exemplo, se uma pessoa não tem diabetes, mas o modelo mostra isso e o médico prescreve certos medicamentos. Isso pode levar a efeitos colaterais graves.
#3. Especificidade
Especificidade ou Taxa de Negativo Verdadeiro (TNR) são resultados negativos corretos encontrados em todos os resultados que poderiam ter sido negativos.
S = TN/(TN + FP)
É uma medida de quão bem seu classificador está identificando os valores negativos.
#4. Precisão
Precisão é o número de previsões corretas do número total de previsões. Portanto, se você encontrou 20 valores positivos e 10 negativos corretamente de uma amostra de 50, a precisão do seu modelo será 30/50.
Precisão A = (TP + TN)/(TP + TN + FP + FN)
#5. Prevalência
A prevalência é a medida do número de resultados positivos obtidos de todos os resultados.
P = (TP + FN)/(TP + TN + FP + FN)
#6. Pontuação F
Às vezes, é difícil comparar dois classificadores (modelos) usando apenas Precision e Recall, que são apenas meios aritméticos de uma combinação das quatro grades. Nesses casos, podemos usar o F Score ou F1 Score, que é a média harmônica – que é mais precisa porque não varia muito para valores extremamente altos. Uma pontuação F mais alta (máximo 1) indica um modelo melhor.
Pontuação F = 2*Precisão*Recordar/ (Recordar + Precisão)
Quando é vital cuidar de falsos positivos e falsos negativos, a pontuação F1 é uma boa métrica. Por exemplo, quem não é covid positivo (mas o algoritmo mostrou) não precisa ser isolado desnecessariamente. Da mesma forma, aqueles que são positivos para Covid (mas o algoritmo disse que não são) precisam ser isolados.
#7. Curvas ROC
Parâmetros como Accuracy e Precision são boas métricas se os dados estiverem balanceados. Para um conjunto de dados desequilibrado, uma alta precisão pode não significar necessariamente que o classificador é eficiente. Por exemplo, 90 de 100 alunos em um lote sabem espanhol. Agora, mesmo que seu algoritmo diga que todos os 100 sabem espanhol, sua precisão será de 90%, o que pode dar uma imagem errada sobre o modelo. Em casos de conjuntos de dados desequilibrados, métricas como ROC são determinantes mais eficazes.
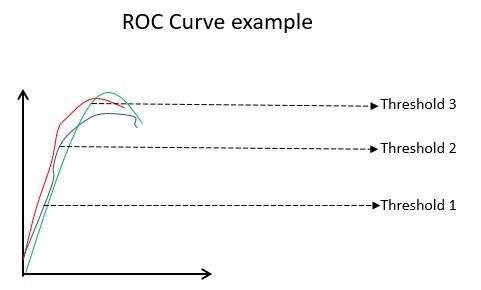 Exemplo de curva ROC
Exemplo de curva ROC
A curva ROC (Receiver Operating Characteristic) exibe visualmente o desempenho de um modelo de classificação binária em vários limites de classificação. É um gráfico de TPR (True Positive Rate) contra FPR (False Positive Rate), que é calculado como (1-Especificidade) em diferentes valores de limite. O valor mais próximo de 45 graus (canto superior esquerdo) no gráfico é o valor limite mais preciso. Se o limite for muito alto, não teremos muitos falsos positivos, mas teremos mais falsos negativos e vice-versa.
Geralmente, quando a curva ROC para vários modelos é plotada, aquele que possui a maior Área Sob a Curva (AUC) é considerado o melhor modelo.
Vamos calcular todos os valores métricos para nossas matrizes de confusão do Classificador I e Classificador II:
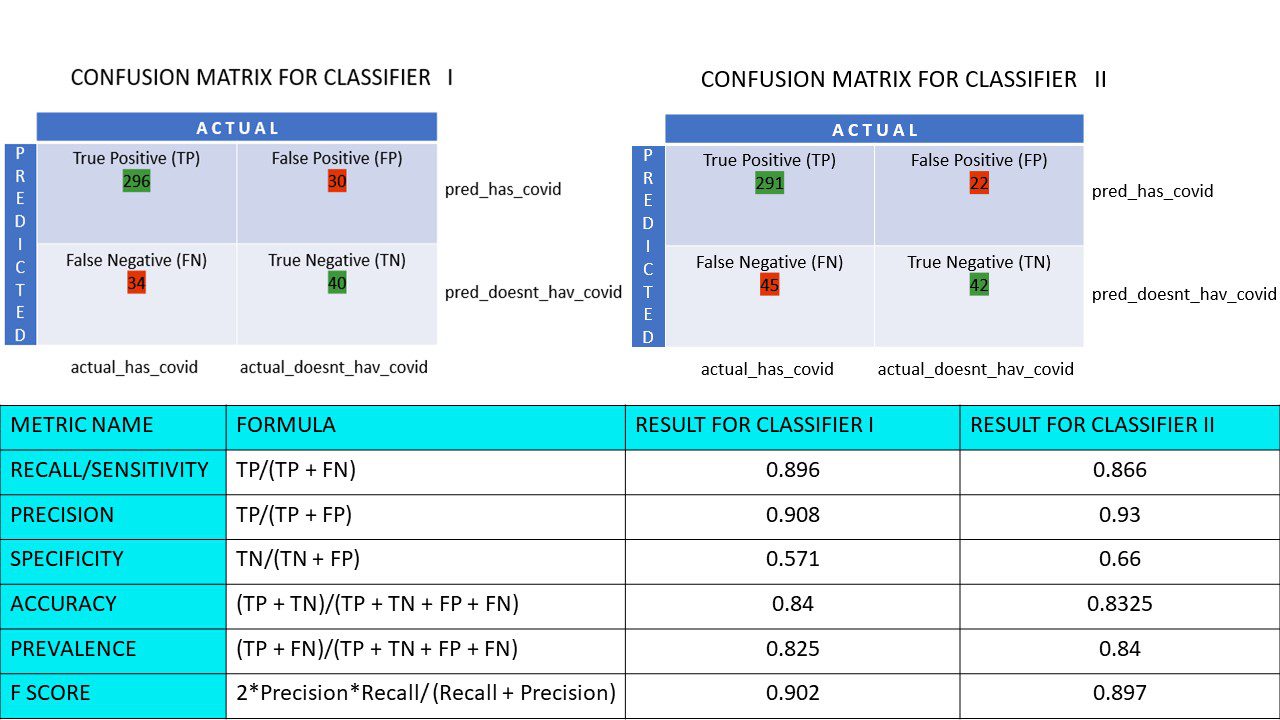 Comparação de métrica para os classificadores 1 e 2 da pesquisa de pizza
Comparação de métrica para os classificadores 1 e 2 da pesquisa de pizza
Vemos que a precisão é maior no classificador II, enquanto a precisão é ligeiramente maior no classificador I. Com base no problema em questão, os tomadores de decisão podem selecionar os classificadores I ou II.
N x N matriz de confusão
Até agora, vimos uma matriz de confusão para classificadores binários. E se houvesse mais categorias do que apenas sim/não ou gostar/não gostar. Por exemplo, se o seu algoritmo fosse classificar imagens das cores vermelho, verde e azul. Esse tipo de classificação é chamado de classificação multiclasse. O número de variáveis de saída também decide o tamanho da matriz. Então, neste caso, a matriz de confusão será 3×3.
 Matriz de confusão para um classificador multiclasse
Matriz de confusão para um classificador multiclasse
Resumo
Uma matriz de confusão é um ótimo sistema de avaliação, pois fornece informações detalhadas sobre o desempenho de um algoritmo de classificação. Funciona bem para classificadores binários e multiclasse, onde há mais de 2 parâmetros a serem atendidos. É fácil visualizar uma matriz de confusão e podemos gerar todas as outras métricas de desempenho como F Score, precisão, ROC e exatidão usando a matriz de confusão.
Você também pode ver como escolher algoritmos de ML para problemas de regressão.