

Um plano de recuperação de desastres é a principal medida que uma organização deve ter antes que um evento incomum os atinja.
No setor de TI, começa criando um documento formal contendo planos, ações e procedimentos para lidar com o desastre e suas consequências.
Desastre é um evento que surge repentinamente sem aviso prévio e pode ser de diferentes tipos. E quando chega, indivíduos e organizações enfrentam dificuldades de vários tipos, incluindo questões financeiras e experiência do usuário.
Se ocorrer um ataque, você deve estar pronto para minimizar seus efeitos e restaurar suas operações mais rapidamente. É aqui que a preparação de um plano prático de recuperação de desastres o ajudará a reter ou evitar o desastre. Você também pode reduzir seus efeitos posteriores em termos de experiência do usuário, custo e tempo de inatividade.
Além disso, você deve manter seus planos, pessoas, estratégias, equipamentos e sistemas prontos para colocar tudo de volta em ação. Mas para isso, você deve entender a recuperação de desastres em profundidade.
Neste artigo, discutirei isso em detalhes, juntamente com as principais terminologias de recuperação de desastres, para que você possa revidar bravamente e sair mais forte em condições tão adversas.
Vamos começar!
últimas postagens
O que é um desastre?
Um desastre é um evento imprevisto que pode acontecer em qualquer lugar, inclusive no setor de TI. Ocorre naturalmente ou por pessoas e pode interferir nas operações de uma empresa e perturbar o tecido da infraestrutura.
Como resultado, uma organização e seus clientes, fornecedores, funcionários e parceiros são afetados. Ele pressiona a organização em termos de finanças, reputação do setor, confiança do cliente e perímetro de segurança.
Portanto, você deve estar pronto com antecedência para superar esse cenário. Para isso, você precisa recuperar todas as operações e dados instantaneamente. Em palavras simples, você deve preparar sua organização para recuperar tudo no menor intervalo possível para seus clientes.
Os desastres são de vários tipos, como ataques cibernéticos, sabotagem, ataques terroristas, ransomware ou ameaças físicas, furacões, terremotos, incêndios, inundações, acidentes industriais, falta de energia e muito mais.
O que você quer dizer com recuperação de desastres?

A recuperação de desastres é o processo de recuperar as operações normais após sofrer um desastre. Envolve retomar o acesso a hardware, software, equipamento, conectividade, rede, energia e dados. Você deve definir regras e procedimentos em um processo documentado para preparar sua organização antes de um desastre.
No entanto, se as instalações da sua organização forem destruídas, você deverá estender algumas das atividades trabalhando em comunicação, transporte, fornecimento, locais de trabalho e muito mais.
Por que o plano de recuperação de desastres é importante?
Elaborar um plano perfeito para a recuperação de um desastre, seja natural ou causado pelo homem, é essencial para todos os setores de TI. Certifique-se de ter o funcionário e as ferramentas certas no lugar certo para executar o plano sem problemas.
Vamos nos aprofundar no motivo pelo qual a recuperação de desastres é crucial.
Limitar Danos
Um desastre é imprevisível. Ninguém sabe quando vem e vai. Mas, você se prepara com antecedência para controlar os danos causados à sua infraestrutura.
Por exemplo, em áreas propensas a inundações, você pode colocar seus documentos e tipos de equipamentos essenciais no último andar para evitar danos.
Da mesma forma, faça backup de seus dados essenciais antes que ataques cibernéticos possam violar dados ou roubá-los.
Restaurando serviços
Se você preparar um plano sólido para se recuperar do desastre, restaurar todos os serviços à sua forma normal será rápido e fácil. Isso significa que em um curto intervalo de tempo, você pode recuperar quase todos os principais ativos e serviços.
Minimizar interrupção
Você não pode saber o que acontecerá amanhã ou na próxima etapa de uma operação. Mas, com um plano de recuperação perfeito, você não precisa se preocupar muito com as consequências. Sua infraestrutura pode continuar as operações com o mínimo de interrupção.
Treinamento e Preparação

Uma infraestrutura de TI consiste em muitos funcionários trabalhando sob o mesmo teto. Todos devem saber sobre a recuperação para agir imediatamente conforme necessário e esperado em caso de emergência.
A preparação adequada também diminuirá os níveis de estresse de todos os associados à sua organização. Além disso, você pode treinar seus funcionários para tomar as ações necessárias se ocorrer um evento inesperado.
Terminologias de recuperação de desastres
Vamos começar com as terminologias para entender a recuperação de desastres de uma visão mais detalhada.
RTO
Objetivo de Tempo de Recuperação (RTO) é a quantidade de tempo que uma organização define de acordo com a natureza do negócio para tolerar desastres sem afetar o crescimento financeiro.
Ao definir o RTO, uma empresa deve verificar os tempos de inatividade que podem afetar sua organização de várias maneiras. Ele é usado para estudar estratégias viáveis para continuar suas operações de negócios mesmo após um desastre. Quando os clientes enfrentam problemas no aplicativo, eles perguntam quanto tempo um aplicativo levará para voltar à ação. A resposta é RTO para cada organização.
Exemplo: Suponha que você seja uma empresa de transações online como PayPal ou Pioneer enfrentando eventos imprevisíveis. Nesse caso, seu RTO será rápido o suficiente para recuperar a operação.
Em outras palavras, uma empresa define seu RTO para uma ou duas horas para evitar consequências na forma de finanças ou dados.
RPO
Objetivos de ponto de recuperação (RPO) é a perda de dados que uma infraestrutura de TI pode lidar em termos de tempo e quantidade de informações.
Confuso?
Veja um exemplo de um banco de dados que registra transações de um banco, incluindo transferências, agendamentos, pagamentos e muito mais. Quando ocorre um desastre, o banco de dados é recuperado em tempo real. A diferença entre o banco de dados no momento do desastre e a recuperação do banco de dados após um desastre é zero neste caso.
Para algumas empresas, é aceitável levar cerca de 24 horas para recuperar todas as informações do backup, mas às vezes pode ser catastrófico. É essencial definir sua infraestrutura de acordo com os requisitos de RPO. Isso inclui aumentar a frequência dos backups, adicionar um banco de dados em espera à sua arquitetura e muito mais.
Failover
Pense em uma situação em que você está viajando uma longa distância. De repente, você tem um pneu furado por algum motivo inesperado. Você agradece o pneu sobressalente disponível em seu veículo e as ferramentas para trocar o pneu defeituoso.
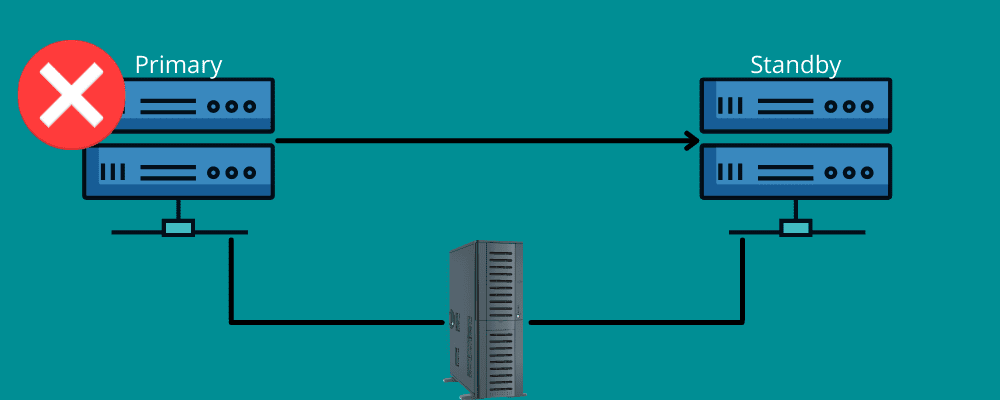
O failover funciona da mesma maneira.
Isso significa que você precisa de uma conexão de backup durante o desastre. Em poucas palavras, failover significa ter redes e sistemas que você pode usar no momento de um desastre para transferir suas informações para o sistema de recuperação.
O failover garante que todos os seus serviços funcionem sem problemas, mesmo se houver falhas de infraestrutura ou de hardware. Dessa forma, você pode evitar que sua organização perca dados e receita e evite interrupções de serviço para seus usuários finais.
Você pode configurá-lo manualmente ou permitir que ele funcione automaticamente para mover os dados para o servidor em espera.
Failback
O failback de TI é uma operação simples em que a produção original volta ao seu local original (sistema) após o tratamento de um desastre. Durante o ataque, as empresas seguem uma operação de failover devido à qual todas as cargas de trabalho são transferidas para uma réplica de VM ou sistema de backup.
No entanto, você não pode simplesmente pular a próxima etapa de retornar. Ao recuperar tudo e voltar à ação, você precisa transferir todas as cargas de trabalho para suas VMs ou sistemas originais. Esse processo geral de retorno das cargas de trabalho ao local de trabalho ou sistema original é conhecido como failback. Isso significa que você está “voltando” após o ataque.
O failback também é usado para a manutenção programada de uma empresa. É verdade que o failback sempre ocorre após o failover. Em outras palavras, o failover é a primeira etapa e o failback é a segunda etapa na recuperação de dados essenciais. Ele pode ser configurado entre nuvem para nuvem, local para local, local para nuvem ou qualquer combinação destes.
RD
A Recuperação de Desastres (DR) é o processo em que você tem planos pré-criados para recuperar seus ativos dentro do prazo.
A DR permite que uma organização responda rapidamente e recupere todos os serviços de um evento inesperado. Também fornece documentação formal que contém instruções sobre como agir imediatamente em caso de incidentes imprevistos.
PCN
O Plano de Continuidade de Negócios (BCP) é um dos planos de recuperação de desastres mais aceitáveis que permite que a infraestrutura de TI crie estratégias para lidar com interrupções de TI em servidores, dispositivos móveis, computadores pessoais e redes.
O BCP é um pouco diferente da recuperação de desastres, pois ajuda uma organização a fazer planos para restabelecer o software corporativo e a produtividade para atender às principais necessidades de negócios.
Aqui, uma empresa cria um sistema de recuperação para superar ameaças potenciais, como ataques cibernéticos ou desastres naturais. Ele foi projetado para proteger ativos e garantir que todos os serviços voltem a funcionar rapidamente após a greve.
BCM

O Business Continuity Management (BCM) é um processo de gerenciamento de risco especialmente desenvolvido para atuar como um escudo contra ameaças aos processos de negócios. O BCM é o próximo passo do BCP, onde valida os planos de recuperação para garantir que todos na empresa respondam ao plano instantaneamente e recuperem todas as coisas essenciais.
O BCM atua como uma estrutura de gerenciamento para identificar riscos de infraestrutura quando enfrenta ameaças externas e/ou internas. Ele também garante que a estrutura funcione de forma eficiente com a ajuda de testes regulares para melhorar a previsibilidade, reduzir riscos e alinhar o plano para ataques futuros.
BIA
Business Impact Analysis (BIA) é o processo de análise da taxa de sobrevivência de um negócio, identificando sistemas, operações e processos cruciais. Ele fala sobre o efeito de um desastre em sua organização devido à interrupção em suas operações.
A BIA prevê as consequências antes que um ataque realmente aconteça para coletar informações importantes que podem ajudar a criar estratégias de recuperação poderosas. Também identifica o custo envolvido devido às falhas, como custo de reposição de equipamentos, perda de fluxo de caixa, lucros, salários e muito mais.
Ao criar um relatório de BIA, você deve considerar os processos cruciais envolvidos em seus negócios, o impacto das interrupções em diferentes áreas, duração aceitável, áreas toleráveis, custos financeiros e muito mais.
Árvore de chamadas
Uma árvore de chamadas é um processo de curadoria de uma lista de funcionários para chamar durante uma emergência. É um procedimento que segue uma estrutura em forma de árvore.
Por exemplo, durante um desastre, uma pessoa entrará em contato com um pequeno grupo de membros com uma mensagem urgente, esses membros da equipe ligarão para cada grupo separadamente. Dessa forma, todos os funcionários serão informados durante a ameaça e iniciarão seu trabalho atribuído para recuperar todas as funções e processos a tempo. Fazer uma lista é simples, mas implementá-la em tempo real cria confusão.
Você deve realizar atividades de chamadas regulares para preparar todos os membros da equipe de emergência para ficarem alertas. Testes regulares também podem ajudar a identificar números alterados ou ausentes que podem afetar gravemente o desempenho.
Uma árvore de chamadas contém informações a serem usadas durante uma emergência para fornecer instruções. Também pode ser feito manualmente, mas as pessoas usam a automação para acelerar o processo e notificar os membros no mundo digital de hoje.
Centro de Comando/Centro de Controle
É uma instalação virtual ou física especialmente preparada para comandar ou controlar os planos de recuperação durante uma crise. Ele se comunica com a equipe para gerenciar os sistemas e funções durante o desastre.
Tradicionalmente, a infraestrutura depende do centro de comando que lida com crises sem uma abordagem adequada. Atualmente, as organizações projetaram perfeitamente seu centro de controle, o que torna a resposta imediata à competência essencial.
Uma vez que detecta um desastre, o centro de comando dirige-se rapidamente para a fase de recuperação. Além disso, serve como ponto de denúncia no caso de serviços, imprensa, entregas e muito mais. Também reúne pessoas de várias disciplinas durante esses cenários.
Resposta a incidentes

A resposta a incidentes é um tipo de resposta dada para lidar com um ataque. Isso é feito com a ajuda dos procedimentos e pessoal corretos para preservar a segurança da rede e dos dados efetivamente no momento certo.
Se uma organização tiver um plano de incidente antes do evento inesperado, ela poderá proteger seus dados contra ameaças em tempo real. Os especialistas em resposta a incidentes estão sempre atentos aos problemas e agem naturalmente durante um incidente. Eles tomam certas medidas para evitar violações de segurança, garantindo que não pulem uma única etapa durante a recuperação de desastres.
No início, você deve determinar os dados críticos e armazená-los na nuvem ou em qualquer local remoto para garantir a segurança. Atenda às necessidades atuais de infraestrutura e ameaças cibernéticas em evolução, atualizando regularmente os planos de resposta a incidentes.
Cópia de segurança
As soluções de backup ajudam uma infraestrutura de TI a manter cópias de dados e armazená-los com segurança no momento certo. Se você enfrentar corrupção de banco de dados, exclusão acidental de todos os dados ou qualquer outro problema, você deve estar pronto com o backup para restaurar os dados instantaneamente e continuar com os serviços.

Envolve replicar os arquivos e armazená-los em um local seguro para acessar todos os dados facilmente após um evento incomum. Ajudará se você fizer backup de seus dados em vários locais para garantir que possa restaurá-los mesmo que um site falhe.
Resiliência
A capacidade de comunidades, estados, organizações e indivíduos de resistir ou resistir a um desastre sem comprometer os serviços e sistemas é conhecida como resiliência a desastres.
Uma organização deve estar preparada para reter uma grande quantidade de estresse devido aos perigos. Certifique-se de ter os recursos para minimizar suas perdas com um melhor planejamento, em vez de esperar que alguém venha resgatá-lo. Isso o ajudará a acomodar os desastres e a recuperar com eficiência sua infraestrutura de TI.
Aqui, o principal objetivo é preservar e restaurar as funções e estruturas essenciais no momento certo, sempre que necessário. Para se tornar uma organização resiliente a desastres, você deve se preparar com antecedência e ter a capacidade de antecipar riscos, ajustar-se a mudanças, compartilhar e aprender, integrar vários setores e gerenciar níveis de risco.
SLA

O Service Level Agreement (SLA) é um plano de desastre no qual você menciona aos usuários finais o tempo que pode levar para restaurar os serviços durante uma emergência.
O SLA garante aos clientes que seus dados estão seguros e não comprometidos ou compartilhados com terceiros. É o único ponto de contato com os problemas do usuário final.
Toda infraestrutura de TI oferece garantia sobre SLA para seus clientes. Portanto, certifique-se de se comunicar com seus usuários finais com antecedência.
SPOF
Um ponto único de falha (SPOF) é um equipamento, um indivíduo, recurso ou aplicativo ao qual muitos outros sistemas ou aplicativos estão conectados.
Se tal equipamento ou recurso ficar inativo, todas as partes essenciais conectadas ao sistema caem com ele. Assim, todo o processo e operação do negócio serão afetados.
Portanto, você deve ter uma estratégia para lidar com esse problema para manter sua organização funcionando. A primeira coisa que você pode fazer é identificar aquele único equipamento ou sistema que pode impactar mais. Em seguida, execute uma análise de impacto nos negócios e obtenha uma pontuação de avaliação de risco para estar ciente das cenas que vão acontecer. Cave e encontre-os antes do evento.
Depois de listar todos os SPOF, classifique-os de acordo com o processo de recuperação. Coloque cada um dos SPOF em três categorias diferentes:
- Recupere de forma fácil e direta com menos tempo e orçamento.
- A recuperação seria difícil, mas um processo confiável poderia ser desenvolvido para restaurar.
- Nada pode ser feito para recuperar uma vez que ele cai.
Você pode agir em conformidade com base na categoria.
Recuperação do sistema
Durante uma falha de hardware, você deve executar um processo de recuperação para recuperar o sistema ou servidor específico para sua forma original. E para recuperar todo o sistema, você precisa estar pronto com os requisitos de recuperação, backups, compatibilidade de firmware e compatibilidade de hardware.
A recuperação do sistema é um processo que redefine a máquina para suas configurações anteriores ou para o mesmo estado em que era nova. Isso eliminará todas as infecções de vírus devido a softwares ou aplicativos instalados em seu sistema.
Esse processo inclui o planejamento de recuperação de uma infraestrutura de TI que define e segue determinados procedimentos para garantir a disponibilidade dos dados contra interrupções naturais ou provocadas pelo homem.
Restauração do sistema
A restauração do sistema é uma ferramenta de recuperação que permite restaurar determinados arquivos e informações ao estado anterior no momento certo.
Com a restauração do sistema, você pode recuperar chaves de registro, programas instalados, drivers, arquivos do sistema e muito mais para a versão anterior. Isso atua como um salva-vidas em muitos desastres.
Plano de teste
Refere-se a um documento que armazena informações sobre uma estratégia de teste, estimativas, recursos, prazos, objetivos e cronogramas. Ele funciona como um blueprint que executa testes para garantir a segurança de hardware e software.
Isso inclui vários testes de acordo com os procedimentos e etapas planejados para gerenciar os efeitos posteriores do desastre. Realize os testes regulares para preparar você e sua organização para não pular uma única etapa durante o curso da ação. Dessa forma, uma infraestrutura de TI pode entender as deficiências e estar pronta para a luta.
Conclusão
Ninguém sabe quando um desastre vai acontecer. Portanto, medidas de segurança e proteção adequadas são essenciais para todos os negócios.
As terminologias de recuperação de desastres ajudarão você a entender como responder a ataques e desastres. Também o ajudará a se preparar com antecedência para proteger sua infraestrutura durante um evento inesperado. Você poderá criar uma estratégia eficaz de recuperação de desastres em tempo real para economizar milhões de dólares e reter a confiança do cliente.