
Imagine que você tem uma grande infraestrutura de vários tipos de dispositivos que precisa manter regularmente ou garantir que não sejam perigosos para o ambiente ao redor.
Uma maneira de conseguir isso é enviar regularmente pessoas a todos os locais para verificar se está tudo bem. Isso é de alguma forma factível, mas também leva muito tempo e recursos caros. E se a infraestrutura for grande o suficiente, talvez você não consiga cobri-la inteira em um ano.
Outra maneira é automatizar esse processo e permitir que os trabalhos na nuvem sejam verificados para você. Para que isso aconteça, você precisará fazer o seguinte:
👉 Um processo rápido de como obter fotos dos dispositivos. Isso ainda pode ser feito por pessoas, pois ainda é muito mais rápido fazer apenas uma foto, como fazer todos os processos de verificação do dispositivo. Também pode ser feito por fotos tiradas de carros ou mesmo drones, caso em que se torna um processo de coleta de fotos muito mais rápido e automatizado.
👉 Então você precisa enviar todas as fotos obtidas para um local dedicado na nuvem.
👉 Na nuvem, você precisa de um trabalho automatizado para pegar as fotos e processá-las por meio de modelos de aprendizado de máquina treinados para reconhecer danos ou anomalias no dispositivo.
👉 Por fim, os resultados devem estar visíveis aos usuários requeridos para que seja agendado o reparo dos aparelhos com problemas.
Vejamos como podemos detectar anomalias nas imagens na nuvem AWS. A Amazon tem alguns modelos de aprendizado de máquina pré-construídos que podemos usar para essa finalidade.
últimas postagens
Como criar um modelo para detecção de anomalias visuais
Para criar um modelo para detecção de anomalia visual, você precisará seguir várias etapas:
Etapa 1: Defina claramente o problema que deseja resolver e os tipos de anomalias que deseja detectar. Isso o ajudará a determinar o conjunto de dados de teste apropriado de que você precisará para treinar o modelo.
Passo 2: Colete um grande conjunto de dados de imagens representando condições normais e anômalas. Rotule as imagens para indicar quais são normais e quais contêm anomalias.
Passo 3: Escolha uma arquitetura de modelo que seja adequada para a tarefa. Isso pode envolver selecionar um modelo pré-treinado e ajustá-lo para seu caso de uso específico ou criar um modelo personalizado do zero.
Passo 4: Treine o modelo usando o conjunto de dados preparado e o algoritmo selecionado. Isso significa usar o aprendizado de transferência para alavancar modelos pré-treinados ou treinar o modelo do zero usando técnicas como redes neurais convolucionais (CNNs).
Como treinar um modelo de aprendizado de máquina
Fonte: aws.amazon.com
O processo de treinamento de modelos de machine learning da AWS para detecção de anomalias visuais geralmente envolve várias etapas importantes.
#1. Colete os dados
No início, você precisa coletar e rotular um grande conjunto de dados de imagens que representam condições normais e anômalas. Quanto maior o conjunto de dados, melhor e mais preciso o modelo pode ser treinado. Mas também envolve muito mais tempo dedicado ao treinamento do modelo.
Normalmente, você deseja ter cerca de 1.000 fotos em um conjunto de teste para ter um bom começo.
#2. Preparar os Dados
Os dados da imagem devem ser pré-processados primeiro para que os modelos de aprendizado de máquina possam capturá-los. O pré-processamento pode significar várias coisas, como:
- Limpar as imagens de entrada em subpastas separadas, corrigir metadados, etc.
- Redimensionar as imagens para atender aos requisitos de resolução do modelo.
- Distribuindo-os em pedaços menores de imagens para um processamento paralelo mais eficaz.
#3. Selecione o modelo
Agora escolha o modelo certo para fazer o trabalho certo. Escolha um modelo pré-treinado ou crie um modelo personalizado adequado para a detecção de anomalia visual no modelo.
#4. Avalie os resultados
Depois que o modelo processa seu conjunto de dados, você deve validar seu desempenho. Além disso, você deseja verificar se os resultados são satisfatórios para as necessidades. Isso pode significar, por exemplo, que os resultados estão corretos em mais de 99% dos dados de entrada.
#5. Implantar o modelo
Se estiver satisfeito com os resultados e desempenho, implante o modelo com uma versão específica no ambiente de conta da AWS para que os processos e serviços possam começar a usá-lo.
#6. Monitorar e Melhorar
Deixe-o executar vários trabalhos de teste e conjuntos de dados de imagem e avalie constantemente se os parâmetros necessários para a exatidão da detecção ainda estão em vigor.
Caso contrário, treine novamente o modelo incluindo os novos conjuntos de dados em que o modelo forneceu os resultados incorretos.
Modelos de aprendizado de máquina da AWS
Agora, veja alguns modelos concretos que você pode aproveitar na nuvem da Amazon.
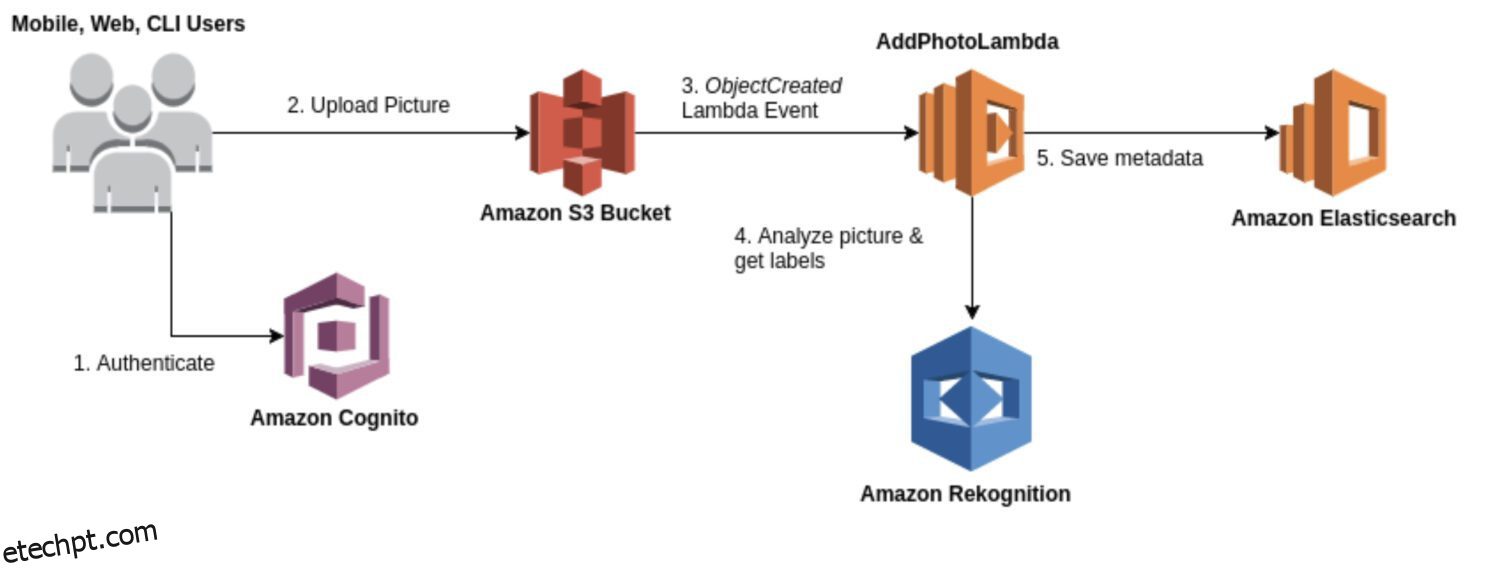
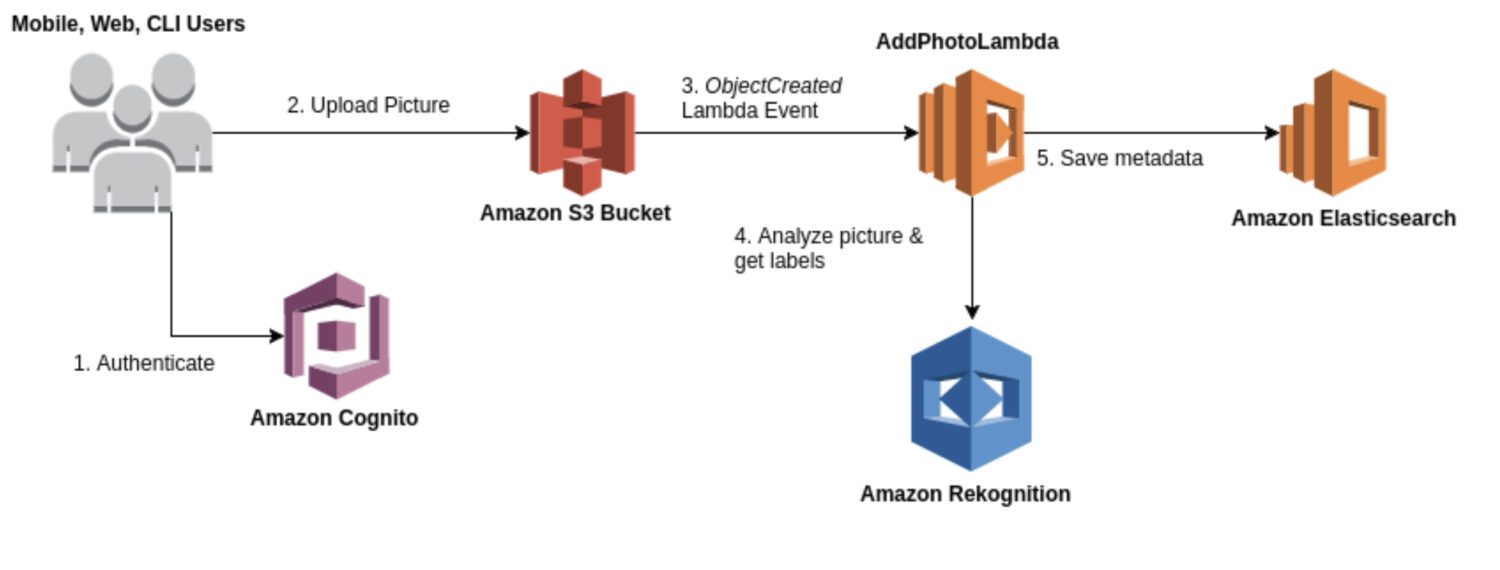
AWS Rekognition
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
O Rekognition é um serviço de análise de imagem e vídeo de propósito geral utilizável para vários casos de uso, como reconhecimento facial, detecção de objetos e reconhecimento de texto. Na maioria das vezes, você usará o modelo Rekognition para uma geração bruta inicial de resultados de detecção para formar um data lake de anomalias identificadas.
Ele fornece uma variedade de modelos pré-construídos que você pode usar sem treinamento. O Rekognition também oferece análise em tempo real de imagens e vídeos com alta precisão e baixa latência.
Aqui estão alguns casos de uso típicos em que o Rekognition é uma boa opção para detecção de anomalias:
- Tenha um caso de uso geral para detecção de anomalias, como detectar anomalias em imagens ou vídeos.
- Realize a detecção de anomalias em tempo real.
- Integre seu modelo de detecção de anomalias com serviços da AWS como Amazon S3, Amazon Kinesis ou AWS Lambda.
E aqui estão alguns exemplos concretos de anomalias que você pode detectar usando o Rekognition:
- Anomalias em rostos, como a detecção de expressões faciais ou emoções fora do intervalo normal.
- Objetos ausentes ou mal colocados em uma cena.
- Palavras com erros ortográficos ou padrões incomuns de texto.
- Condições de iluminação incomuns ou objetos inesperados em uma cena.
- Conteúdo impróprio ou ofensivo em imagens ou vídeos.
- Mudanças repentinas no movimento ou padrões inesperados de movimento.
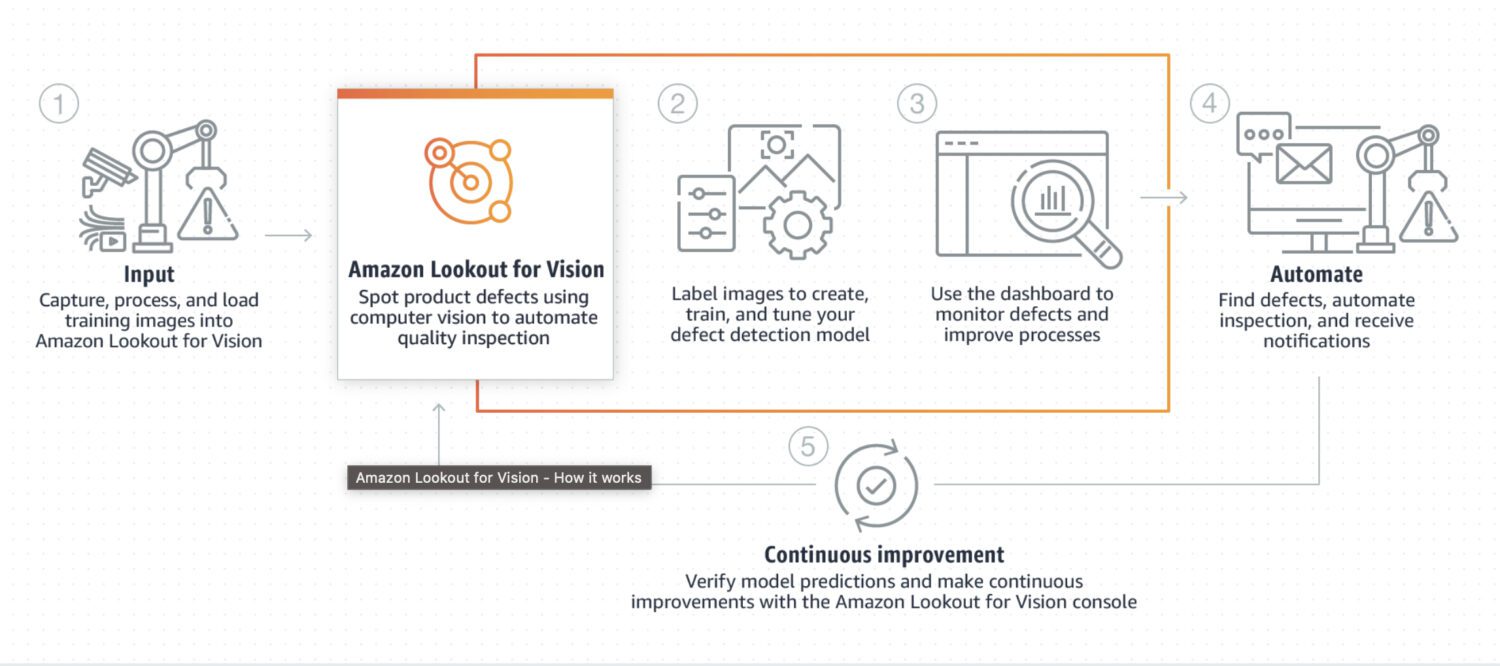
AWS Lookout for Vision
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
O Lookout for Vision é um modelo projetado especificamente para detecção de anomalias em processos industriais, como manufatura e linhas de produção. Normalmente, requer algum pré-processamento de código personalizado e pós-processamento de uma imagem ou algum recorte concreto da imagem, geralmente feito usando uma linguagem de programação Python. Na maioria das vezes, ele se especializa em alguns problemas muito especiais na imagem.
Requer treinamento personalizado em um conjunto de dados de imagens normais e anômalas para criar um modelo personalizado para detecção de anomalias. Não é tão focado em tempo real; em vez disso, ele é projetado para processamento em lote de imagens, com foco na exatidão e precisão.
Aqui estão alguns casos de uso típicos em que o Lookout for Vision é uma boa escolha se você precisar detectar:
- Defeitos em produtos fabricados ou identificação de falhas de equipamentos em uma linha de produção.
- Um grande conjunto de dados de imagens ou outros dados.
- Anomalia em tempo real em um processo industrial.
- Anomaly integrado com outros serviços da AWS, como Amazon S3 ou AWS IoT.
E aqui estão alguns exemplos concretos de anomalias que você pode detectar usando o Lookout for Vision:
- Defeitos em produtos manufaturados, como arranhões, amassados ou outras imperfeições, podem afetar a qualidade do produto.
- Falhas de equipamentos em uma linha de produção, como a detecção de máquinas quebradas ou com mau funcionamento, podem causar atrasos ou riscos à segurança.
- Os problemas de controle de qualidade em uma linha de produção incluem a detecção de produtos que não atendem às especificações ou tolerâncias exigidas.
- Os riscos de segurança em uma linha de produção incluem a detecção de objetos ou materiais que possam representar um risco para os trabalhadores ou equipamentos.
- Anomalias em um processo de produção, como a detecção de mudanças inesperadas no fluxo de materiais ou produtos na linha de produção.
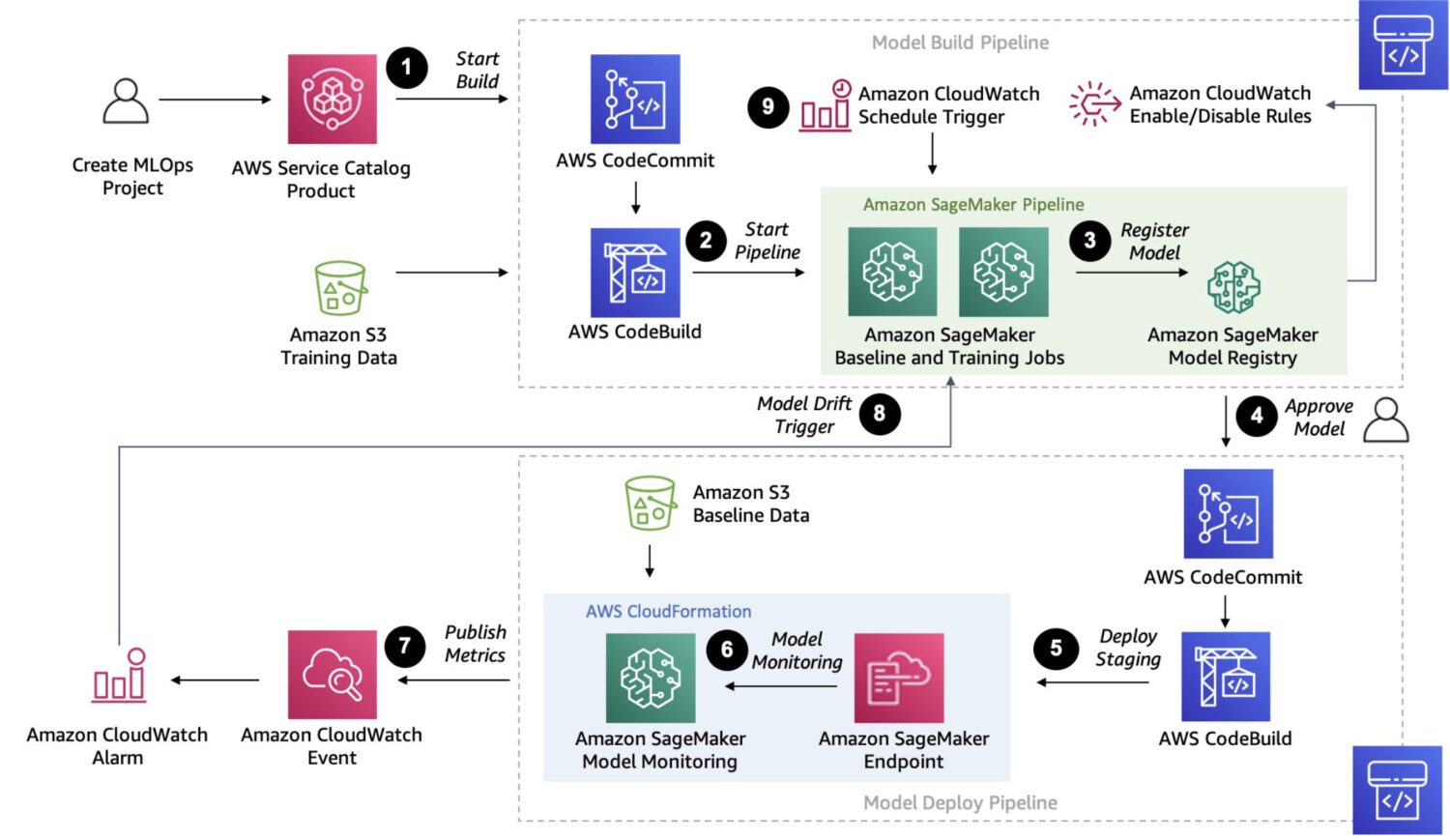
AWS Sagemaker
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
O Sagemaker é uma plataforma totalmente gerenciada para criar, treinar e implantar modelos personalizados de aprendizado de máquina.
É uma solução muito mais robusta. Na verdade, ele fornece uma maneira de conectar e executar vários processos de várias etapas em uma cadeia de trabalhos, um após o outro, da mesma forma que o AWS Step Functions pode fazer.
Mas como o Sagemaker usa instâncias EC2 ad-hoc para seu processamento, não há limite de 15 minutos para o processamento de um único trabalho, como no caso das funções lambda da AWS no AWS Step Functions.
Você também pode fazer o ajuste automático do modelo com o Sagemaker, que é definitivamente um recurso que o torna uma opção de destaque. Por fim, o Sagemaker pode implantar o modelo sem esforço em um ambiente de produção.
Aqui estão alguns casos de uso típicos em que o SageMaker é uma boa opção para detecção de anomalias:
- Um caso de uso específico não coberto por modelos ou APIs pré-construídos e se você precisar criar um modelo personalizado para atender às suas necessidades específicas.
- Se você tiver um grande conjunto de dados de imagens ou outros dados. Modelos pré-construídos requerem algum pré-processamento nesses casos, mas o Sagemaker pode fazer isso sem ele.
- Se você precisar realizar a detecção de anomalias em tempo real.
- Se você precisar integrar seu modelo com outros serviços da AWS, como Amazon S3, Amazon Kinesis ou AWS Lambda.
E aqui estão algumas detecções de anomalias típicas que o Sagemaker é capaz de realizar:
- Detecção de fraude em transações financeiras, por exemplo, padrões de gastos incomuns ou transações fora do intervalo normal.
- Segurança cibernética no tráfego de rede, como padrões incomuns de transferência de dados ou conexões inesperadas com servidores externos.
- Diagnóstico médico em imagens médicas, como detecção de tumores.
- Anomalias no desempenho do equipamento, como detecção de mudanças de vibração ou temperatura.
- Controle de qualidade nos processos de fabricação, como detecção de defeitos em produtos ou identificação de desvios dos padrões de qualidade esperados.
- Padrões incomuns de uso de energia.
Como incorporar os modelos na arquitetura sem servidor
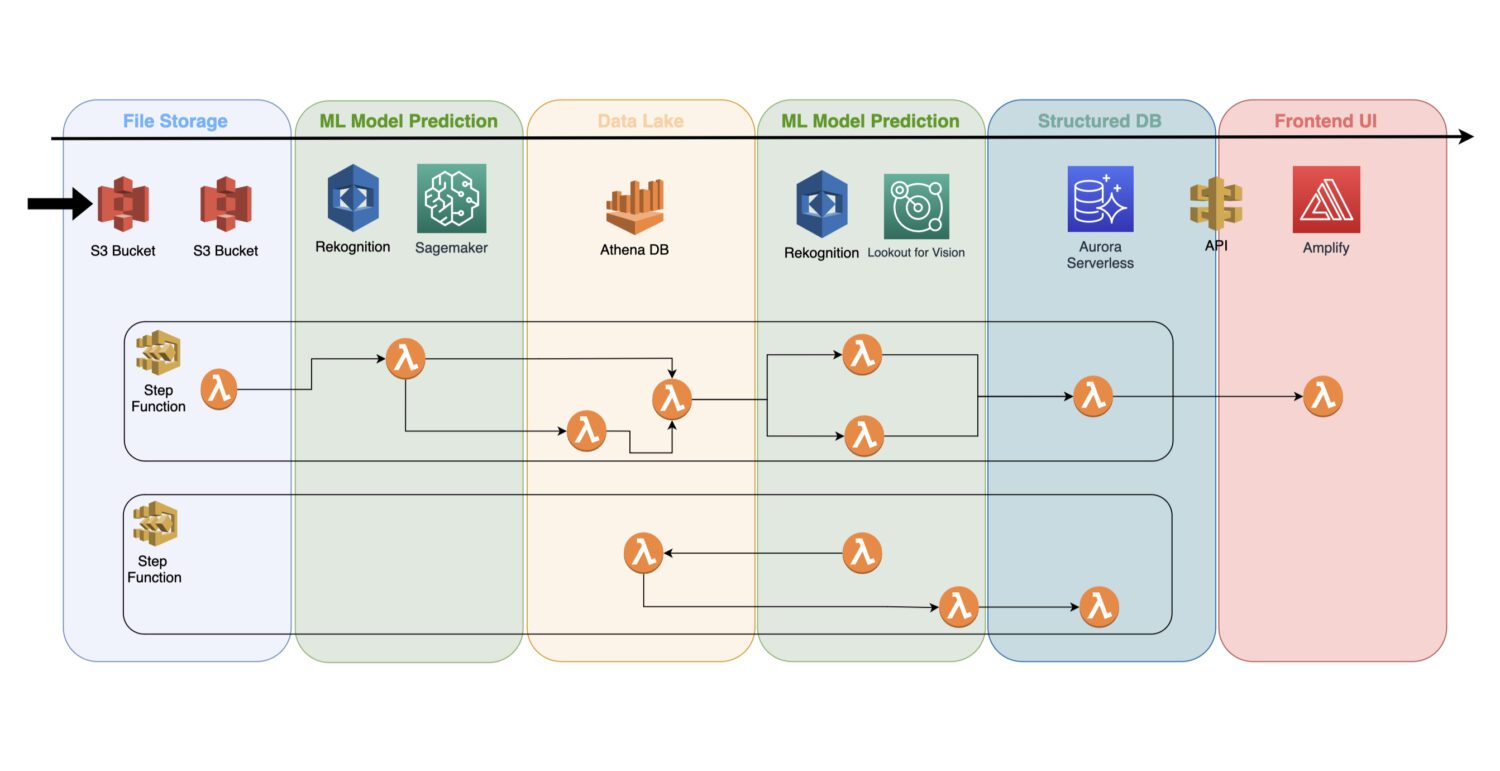
Um modelo de aprendizado de máquina treinado é um serviço de nuvem que não usa nenhum servidor de cluster em segundo plano; portanto, pode ser facilmente incluído em uma arquitetura sem servidor existente.
A automação é feita por meio de funções lambda da AWS, conectadas a um trabalho de várias etapas dentro de um serviço AWS Step Functions.
Normalmente, você precisa de detecção inicial logo após coletar as imagens e seu pré-processamento no balde S3. É aí que você irá gerar a detecção de anomalias atômicas nas imagens de entrada e salvar os resultados em um data lake, por exemplo, representado pelo banco de dados Athena.
Em alguns casos, essa detecção inicial não é suficiente para seu caso de uso concreto. Você pode precisar de outra detecção mais detalhada. Por exemplo, o modelo inicial (por exemplo, Reconhecimento) pode detectar algum problema no dispositivo, mas não é possível identificar com segurança que tipo de problema é esse.
Para isso, você pode precisar de outro modelo com capacidades diferentes. Nesse caso, você pode executar o outro modelo (por exemplo, Lookout for Vision) no subconjunto de imagens em que o modelo inicial identificou o problema.
Essa também é uma boa maneira de economizar alguns custos, pois você não precisa executar o segundo modelo em um conjunto completo de fotos. Em vez disso, você o executa apenas no subconjunto significativo.
As funções do AWS Lambda cobrirão todo esse processamento usando o código Python ou Javascript interno. Depende apenas da natureza dos processos e de quantas funções lambda da AWS você precisará incluir em um fluxo. O limite de 15 minutos para a duração máxima de uma chamada AWS lambda determinará quantas etapas esse processo precisa conter.
Palavras Finais
Trabalhar com modelos de aprendizado de máquina em nuvem é um trabalho muito interessante. Se você olhar pela perspectiva das competências e tecnologias, descobrirá que precisa ter uma equipe com uma grande variedade de competências.
A equipe precisa entender como treinar um modelo, seja ele pré-construído ou criado do zero. Isso significa que muita matemática ou álgebra está envolvida no equilíbrio entre a confiabilidade e o desempenho dos resultados.
Você também precisa de algumas habilidades avançadas de codificação Python ou Javascript, banco de dados e habilidades SQL. E depois que todo o trabalho de conteúdo estiver concluído, você precisará de habilidades de DevOps para conectá-lo a um pipeline que o tornará um trabalho automatizado pronto para implantação e execução.
Definir a anomalia e treinar o modelo é uma coisa. Mas é um desafio integrar tudo em uma equipe funcional que possa processar os resultados dos modelos e salvar os dados de maneira eficaz e automatizada para atendê-los aos usuários finais.
A seguir, confira tudo sobre reconhecimento facial para empresas.