
O Reddit oferece feeds JSON para cada subreddit. Veja como criar um script Bash que baixa e analisa uma lista de postagens de qualquer subreddit de sua preferência. Isso é apenas uma coisa que você pode fazer com os feeds JSON do Reddit.
últimas postagens
Instalando Curl e JQ
Vamos usar curl para buscar o feed JSON do Reddit e jq para analisar os dados JSON e extrair os campos que queremos dos resultados. Instale essas duas dependências usando apt-get no Ubuntu e outras distribuições Linux baseadas em Debian. Em outras distribuições Linux, use a ferramenta de gerenciamento de pacotes da sua distribuição.
sudo apt-get install curl jq
Busque alguns dados JSON do Reddit
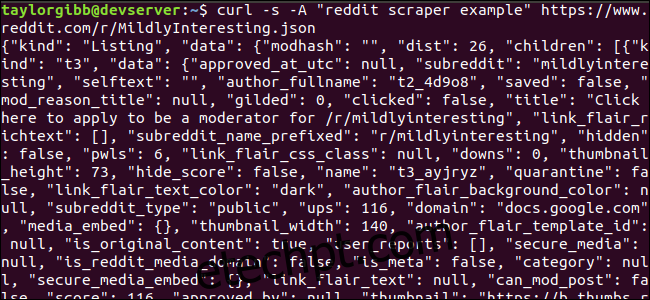
Vamos ver como é o feed de dados. Use curl para buscar as últimas postagens do Moderadamente interessante subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Observe como as opções usadas antes do URL: -s força o curl a ser executado no modo silencioso para que não vejamos nenhuma saída, exceto os dados dos servidores do Reddit. A próxima opção e o parâmetro a seguir, -A “exemplo de raspador de reddit”, define uma string de agente de usuário personalizada que ajuda o Reddit a identificar o serviço que está acessando seus dados. Os servidores Reddit API aplicam limites de taxa com base na string do agente do usuário. Definir um valor personalizado fará com que o Reddit segmente nosso limite de taxa longe de outros chamadores e reduza a chance de obtermos um erro HTTP 429 Limite de taxa excedido.
A saída deve preencher a janela do terminal e ser parecida com isto:
Existem muitos campos nos dados de saída, mas estamos apenas interessados em Título, Link permanente e URL. Você pode ver uma lista exaustiva de tipos e seus campos na página de documentação da API do Reddit: https://github.com/reddit-archive/reddit/wiki/JSON
Extração de dados da saída JSON
Queremos extrair Título, Link permanente e URL dos dados de saída e salvá-los em um arquivo delimitado por tabulação. Podemos usar ferramentas de processamento de texto como sed e grep, mas temos outra ferramenta à nossa disposição que entende estruturas de dados JSON, chamada jq. Para nossa primeira tentativa, vamos usá-lo para imprimir e codificar com cores a saída. Usaremos a mesma chamada de antes, mas desta vez, canalize a saída por meio de jq e instrua-o a analisar e imprimir os dados JSON.
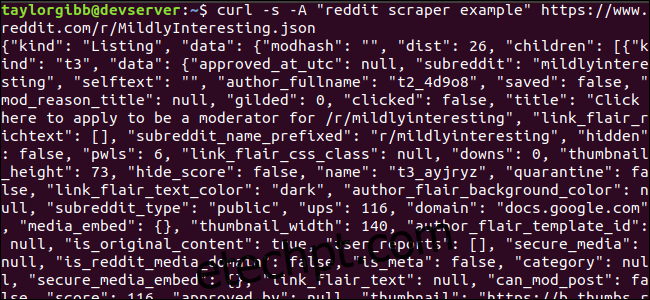
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Observe o período após o comando. Esta expressão simplesmente analisa a entrada e a imprime como está. A saída parece bem formatada e codificada por cores:
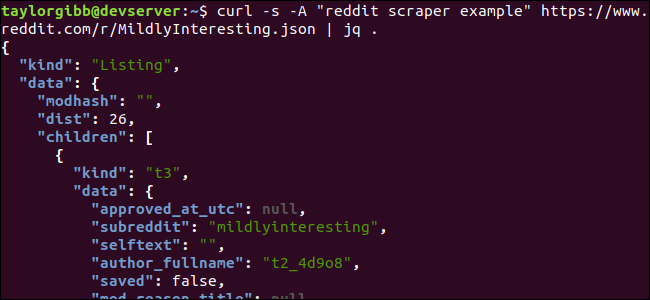
Vamos examinar a estrutura dos dados JSON que recebemos do Reddit. O resultado raiz é um objeto que contém duas propriedades: tipo e dados. O último contém uma propriedade chamada children, que inclui uma matriz de postagens para este subreddit.
Cada item da matriz é um objeto que também contém dois campos chamados tipo e dados. As propriedades que queremos obter estão no objeto de dados. jq espera uma expressão que possa ser aplicada aos dados de entrada e produza a saída desejada. Deve descrever o conteúdo em termos de sua hierarquia e associação a um array, bem como a forma como os dados devem ser transformados. Vamos executar todo o comando novamente com a expressão correta:
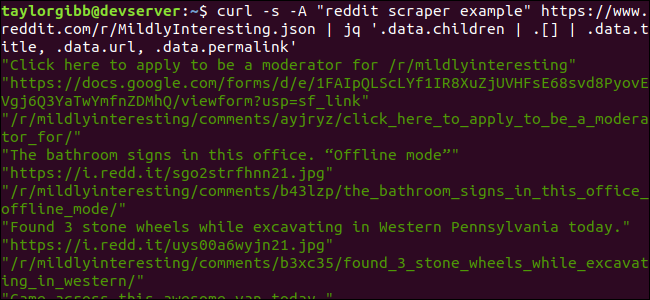
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
A saída mostra Título, URL e Link permanente, cada um em sua própria linha:
Vamos mergulhar no comando jq que chamamos:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Existem três expressões neste comando separadas por dois símbolos de barra vertical. Os resultados de cada expressão são passados para a próxima para avaliação posterior. A primeira expressão filtra tudo, exceto a matriz de listagens do Reddit. Essa saída é canalizada para a segunda expressão e forçada para uma matriz. A terceira expressão atua em cada elemento da matriz e extrai três propriedades. Mais informações sobre jq e sua sintaxe de expressão podem ser encontradas em manual oficial do jq.
Juntando tudo em um script
Vamos colocar a chamada API e o pós-processamento JSON juntos em um script que irá gerar um arquivo com os posts que queremos. Adicionaremos suporte para buscar postagens de qualquer subreddit, não apenas de / r / MildlyInteresting.
Abra seu editor e copie o conteúdo deste trecho em um arquivo chamado scrape-reddit.sh
#!/bin/bash
if [ -z "$1" ]
then
echo "Please specify a subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Este script verificará primeiro se o usuário forneceu um nome de subreddit. Caso contrário, ele sai com uma mensagem de erro e um código de retorno diferente de zero.
Em seguida, ele armazenará o primeiro argumento como o nome do subreddit e criará um nome de arquivo com carimbo de data onde a saída será salva.
A ação começa quando curl é chamado com um cabeçalho customizado e a URL do subreddit para raspar. A saída é canalizada para jq, onde é analisada e reduzida a três campos: Título, URL e Link permanente. Essas linhas são lidas, uma de cada vez, e salvas em uma variável usando o comando read, tudo dentro de um loop while, que continuará até que não haja mais linhas para ler. A última linha do bloco while interno ecoa os três campos, delimitados por um caractere de tabulação e, em seguida, canaliza-o através do comando tr para que as aspas duplas possam ser removidas. A saída é então anexada a um arquivo.
Antes de podermos executar este script, devemos garantir que ele tenha recebido permissões de execução. Use o comando chmod para aplicar essas permissões ao arquivo:
chmod u+x scrape-reddit.sh
E, por último, execute o script com um nome de subreddit:
./scrape-reddit.sh MildlyInteresting
Um arquivo de saída é gerado no mesmo diretório e seu conteúdo será semelhante a este:
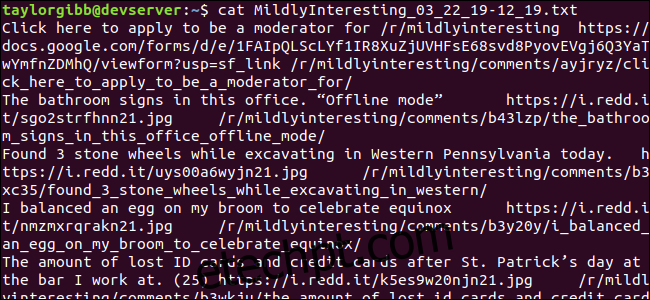
Cada linha contém os três campos que buscamos, separados por um caractere de tabulação.
Indo além
Reddit é uma mina de ouro de conteúdo e mídia interessantes, e tudo é facilmente acessado usando sua API JSON. Agora que você tem uma maneira de acessar esses dados e processar os resultados, pode fazer coisas como:
Obtenha as últimas manchetes de / r / WorldNews e envie-as para o seu desktop usando notificar-enviar
Integre as melhores piadas de / r / DadJokes na mensagem do dia do seu sistema
Obtenha a melhor imagem de hoje em / r / aww e transforme-a no plano de fundo da sua área de trabalho
Tudo isso é possível usando os dados fornecidos e as ferramentas que você possui em seu sistema. Feliz hackeamento!