
No mundo orientado a dados de hoje, o método tradicional de coleta manual de dados está desatualizado. Um computador com conexão à internet em cada mesa tornou a web uma enorme fonte de dados. Assim, o método moderno mais eficiente e que economiza tempo para coleta de dados é a raspagem da web. E quando se trata de web scraping, Python tem uma ferramenta chamada Beautiful Soup. Neste post, vou orientá-lo nas etapas de instalação do Beautiful Soup para começar a raspagem na web.
Antes de instalar e trabalhar com o Beautiful Soup, vamos descobrir por que você deve fazer isso.
últimas postagens
O que é uma bela sopa?
Vamos fingir que você está pesquisando “o impacto do COVID na saúde das pessoas” e encontrou algumas páginas da web contendo dados relevantes. Mas e se eles não oferecerem uma opção de download com um único clique para emprestar seus dados? Aqui entra a bela sopa em jogo.
Beautiful Soup está entre o índice de bibliotecas Python para extrair os dados de sites direcionados. É mais confortável recuperar dados de páginas HTML ou XML.
Leonard Richardson trouxe a ideia de Beautiful Soup para raspar a web em 2004. Mas sua contribuição para o projeto continua até hoje. Ele orgulhosamente atualiza cada novo lançamento da Beautiful Soup em sua conta no Twitter.
Embora o Beautiful Soup para web scraping tenha sido desenvolvido usando o Python 3.8, ele também funciona perfeitamente com o Python 3 e o Python 2.4.
Frequentemente, os sites usam proteção captcha para resgatar seus dados das ferramentas de IA. Nesse caso, algumas alterações no cabeçalho ‘user-agent’ no Beautiful Soup ou usando APIs de resolução de Captcha podem imitar um navegador confiável e enganar a ferramenta de detecção.
No entanto, se você não tem tempo para explorar o Beautiful Soup ou deseja que a raspagem seja feita com eficiência e facilidade, não deixe de conferir esta API de raspagem da web, onde você pode apenas fornecer um URL e obter os dados em suas mãos.
Se você já é um programador, usar o Beautiful Soup para raspar não será assustador por causa de sua sintaxe direta para navegar em páginas da Web e extrair os dados desejados com base na análise condicional. Ao mesmo tempo, também é amigável para iniciantes.
Embora Beautiful Soup não seja para raspagem avançada, funciona melhor para raspar os dados de arquivos escritos em linguagens de marcação.
A documentação clara e detalhada é outro ponto importante que a Beautiful Soup conquistou.
Vamos encontrar uma maneira fácil de colocar uma bela sopa em sua máquina.
Como instalar o Beautiful Soup para Web Scraping?
Pip – Um gerenciador de pacotes Python sem esforço desenvolvido em 2008 agora é uma ferramenta padrão entre os desenvolvedores para instalar quaisquer bibliotecas ou dependências Python.
O Pip vem por padrão com a instalação de versões recentes do Python. Portanto, se você tiver alguma versão recente do Python instalada em seu sistema, está pronto para começar.
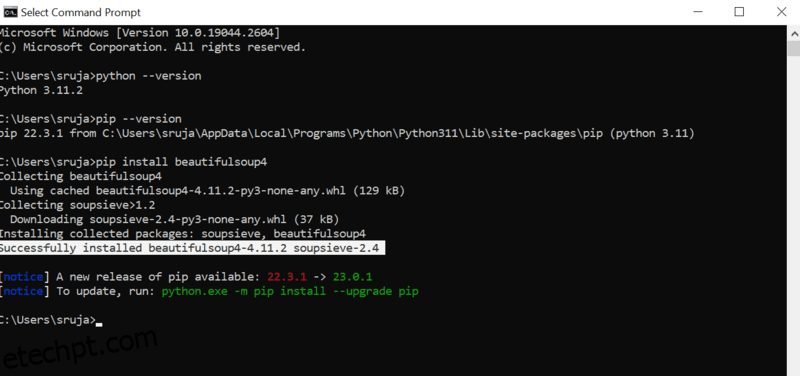
Abra o prompt de comando e digite o seguinte comando pip para instalar a bela sopa instantaneamente.
pip install beautifulsoup4
Você verá algo semelhante à captura de tela a seguir em sua tela.
Certifique-se de ter atualizado o instalador do PIP para a versão mais recente para evitar erros comuns.
O comando para atualizar o instalador do pip para a versão mais recente é:
pip install --upgrade pip
Cobrimos com sucesso metade do terreno neste post.
Agora você tem o Beautiful Soup instalado em sua máquina, então vamos nos aprofundar em como usá-lo para web scraping.
Como importar e trabalhar com Beautiful Soup para Web Scraping?
Digite o seguinte comando em seu IDE python para importar uma bela sopa para o script python atual.
from bs4 import BeautifulSoup
Agora o Beautiful Soup está em seu arquivo Python para usar para raspagem.
Vejamos um exemplo de código para aprender como extrair os dados desejados com o belo Soup.
Podemos dizer ao beautiful Soup para procurar tags HTML específicas no site de origem e coletar os dados presentes nessas tags.
Neste artigo, usarei o marketwatch.com, que atualiza os preços das ações em tempo real de várias empresas. Vamos extrair alguns dados deste site para se familiarizar com a biblioteca Beautiful Soup.
Importe o pacote “requests” que nos permitirá receber e responder a solicitações HTTP e “urllib” para carregar a página da Web a partir de seu URL.
from urllib.request import urlopen import requests
Salve o link da página da Web em uma variável para que você possa acessá-lo facilmente mais tarde.
url="https://www.marketwatch.com/investing/stock/amzn"
A próxima seria usar o método “urlopen” da biblioteca “urllib” para armazenar a página HTML em uma variável. Passe a URL para a função “urlopen” e salve o resultado em uma variável.
page = urlopen(url)
Crie um objeto Beautiful Soup e analise a página da Web desejada usando “html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')
Agora, todo o script HTML da página da Web de destino é armazenado na variável ‘soup_obj’.
Antes de prosseguir, vamos examinar o código-fonte da página de destino para saber mais sobre o script HTML e as tags.
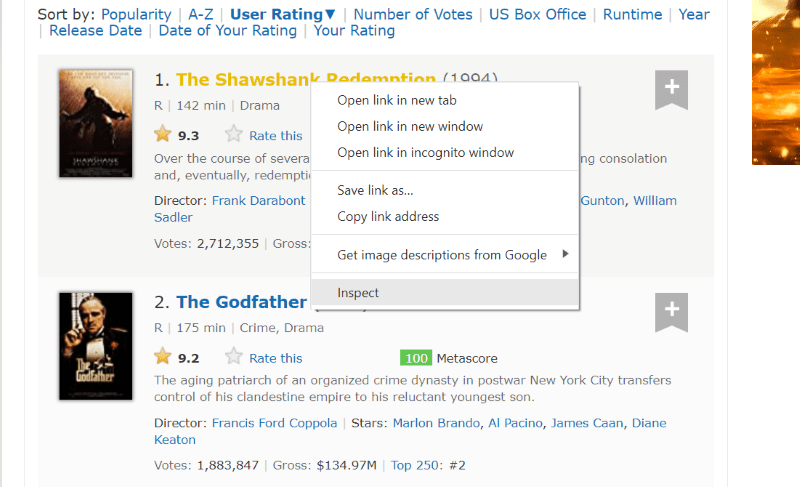
Clique com o botão direito do mouse em qualquer lugar da página da Web com o mouse. Em seguida, você encontrará uma opção de inspeção, conforme exibido abaixo.
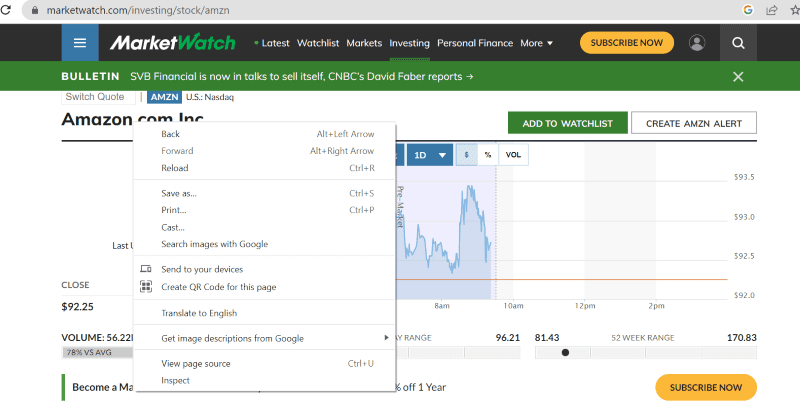
Clique em inspecionar para visualizar o código-fonte.
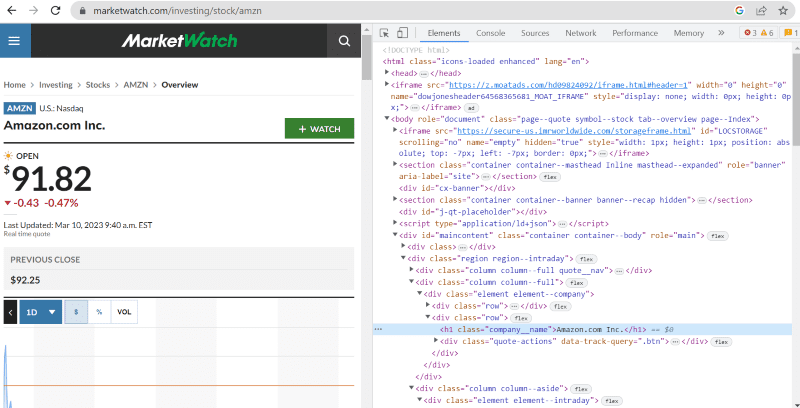
No código-fonte acima, você encontra tags, classes e informações mais específicas sobre cada elemento visível na interface do site.
O método “find” no beautiful Soup nos permite procurar as tags HTML solicitadas e recuperar os dados. Para fazer isso, damos o nome da classe e as tags ao método que extrai dados específicos.
Por exemplo, “Amazon.com Inc.” mostrado na página da web tem o nome da classe: ‘company__name’ marcado como ‘h1’. Podemos inserir essas informações no método ‘find’ para extrair o trecho HTML relevante em uma variável.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Vamos gerar o script HTML armazenado na variável “nome” e o texto necessário na tela.
print(name) print(name.text)

Você pode testemunhar os dados extraídos impressos na tela.
Web Raspe o site da IMDb
Muitos de nós procuramos classificações de filmes no site do IMBb antes de assistir a um filme. Esta demonstração fornecerá uma lista dos filmes mais bem avaliados e ajudará você a se acostumar com a bela Soup for web scraping.
Etapa 1: importe as belas bibliotecas de sopas e solicitações.
from bs4 import BeautifulSoup import requests
Etapa 2: vamos atribuir a URL que queremos extrair a uma variável chamada ‘url’ para facilitar o acesso no código.
O pacote “requests” é usado para obter a página HTML da URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Etapa 3: No trecho de código a seguir, analisaremos a página HTML da URL atual para criar um objeto de Beautiful Soup.
soup_obj = BeautifulSoup(url.text, 'html.parser')
A variável “soup_obj” agora contém todo o script HTML da página desejada, conforme a imagem a seguir.
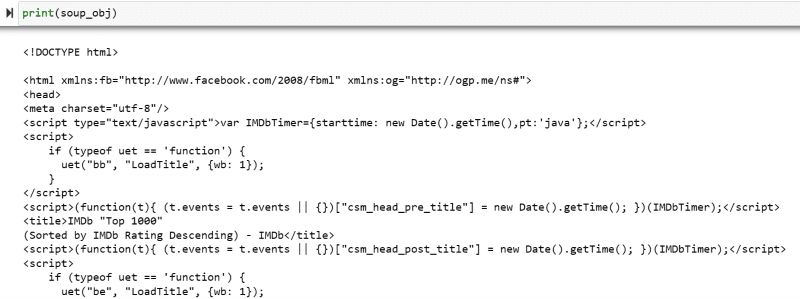
Vamos inspecionar o código-fonte da página da Web para encontrar o script HTML dos dados que queremos extrair.
Passe o cursor sobre o elemento da página da web que você deseja extrair. Em seguida, clique com o botão direito do mouse e vá com a opção inspecionar para visualizar o código-fonte desse elemento específico. Os visuais a seguir irão guiá-lo melhor.
A classe ‘lister-list’ contém todos os dados relacionados ao filme com melhor classificação como subdivisões em tags div sucessivas.
No script HTML de cada cartão de filme, na classe ‘lister-item mode-advanced’, temos uma tag ‘h3’ que armazena o nome do filme, classificação e ano de lançamento, conforme destacado na imagem abaixo.
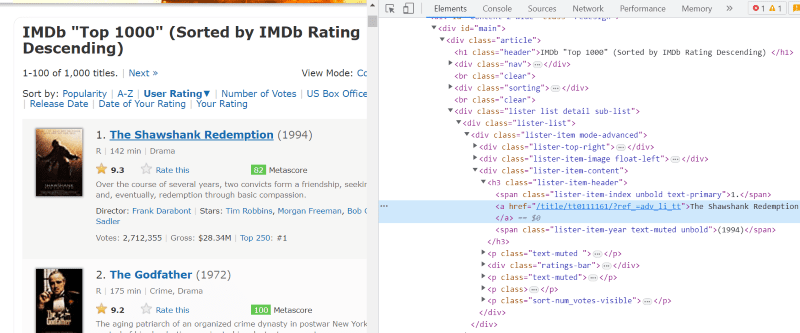
Nota: O método “find” no beautiful Soup procura a primeira tag que corresponda ao nome de entrada dado a ela. Ao contrário de “find”, o método “find_all” procura todas as tags que correspondem à entrada fornecida.
Passo 4: Você pode usar os métodos “find” e “find_all” para salvar o script HTML do nome, classificação e ano de cada filme em uma variável de lista.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
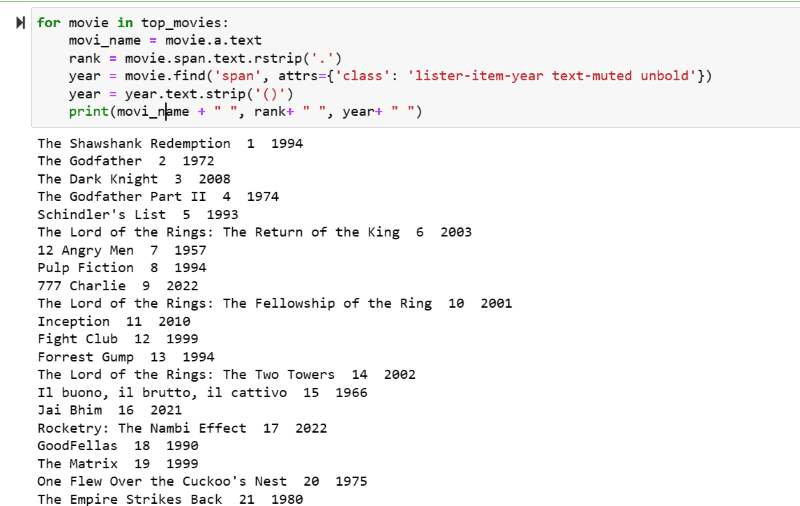
Etapa 5: Percorra a lista de filmes armazenados na variável: “top_movies” e extraia o nome, a classificação e o ano de cada filme em formato de texto de seu script HTML usando o código abaixo.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
Na captura de tela de saída, você pode ver a lista de filmes com seu nome, classificação e ano de lançamento.
Você pode facilmente mover os dados impressos para uma planilha do Excel com algum código python e usá-lo para sua análise.
Palavras Finais
Este post orienta você na instalação do Beautiful Soup para web scraping. Além disso, os exemplos de raspagem que mostrei devem ajudá-lo a começar com o Beautiful Soup.
Como você está interessado em como instalar o Beautiful Soup para web scraping, eu recomendo fortemente que você verifique este guia compreensível para saber mais sobre web scraping usando Python.