

Se você aprendeu algumas linguagens de programação de computador, pode ter ouvido o termo, análise de texto. Isso é usado para simplificar os valores de dados complexos do arquivo. O artigo ajuda você a saber como analisar o texto usando o idioma. Além disso, se você enfrentou um erro no texto de análise x, saberá como corrigir o erro de análise no artigo.

últimas postagens
Como analisar texto
Neste artigo, mostramos um guia completo para analisar texto de várias maneiras e também demos uma breve introdução à análise de texto.
O que é análise de texto?
Antes de mergulhar para aprender os conceitos de análise de texto usando qualquer código. É importante saber sobre o básico da linguagem e da codificação.
PNL ou Processamento de Linguagem Natural
Para analisar o texto, é utilizado o Processamento de Linguagem Natural ou NLP, que é um subcampo do domínio da Inteligência Artificial. A linguagem Python, que é uma das linguagens que pertencem à categoria, é usada para analisar texto.
Os códigos NLP permitem que os computadores entendam e processem linguagens humanas para torná-las adequadas para várias aplicações. Para aplicar técnicas de ML ou Machine Learning à linguagem, os dados de texto não estruturados devem ser convertidos em dados tabulares estruturados. Para completar a atividade de análise, a linguagem Python é usada para alterar os códigos do programa.
O que é análise de texto?
Analisar texto significa simplesmente converter os dados de um formato para outro. O formato no qual o arquivo é salvo deve ser analisado ou convertido em um arquivo em um formato diferente para permitir que o usuário o use em várias aplicações.
- Em outras palavras, o processo significa analisar a string ou um texto e converter em componentes lógicos alterando o formato do arquivo.
- Algumas regras da linguagem Python são utilizadas para completar esta tarefa de programação comum. Ao analisar o texto, a série de texto fornecida é dividida em componentes menores.
Quais são as razões para analisar o texto?
As razões pelas quais o texto deve ser analisado são fornecidas nesta seção e é um pré-requisito de conhecimento antes de saber como analisar o texto.
- Todos os dados informatizados não estarão no mesmo formato e podem diferir de acordo com várias aplicações.
- Os formatos de dados variam para vários aplicativos e um código incompatível levaria a esse erro.
- Não existe um programa de computador universal individual para selecionar os dados de todos os formatos de dados.
Método 1: por meio da classe DataFrame
A classe DataFrame da linguagem Python possui todas as funções necessárias para analisar texto. Esta biblioteca embutida abriga os códigos necessários para analisar dados de qualquer formato para outro formato.
Breve introdução da classe DataFrame
DataFrame Class é uma estrutura de dados rica em recursos, que é usada como uma ferramenta de análise de dados. Esta é uma poderosa ferramenta de análise de dados que pode ser usada para analisar dados com o mínimo de esforço.
- O código é lido no DataFrame do pandas para realizar a análise na linguagem Python.
- A classe vem com vários pacotes fornecidos pelos pandas que são usados pelos analistas de dados Python.
- A característica desta classe é uma abstração, um código no qual a funcionalidade interna da função está escondida dos usuários, da biblioteca NumPy. A biblioteca NumPy é uma biblioteca python que engloba os comandos e funções para trabalhar com arrays.
- A classe DataFrame pode ser usada para renderizar uma matriz bidimensional com vários índices de linha e coluna. Esses índices ajudam no armazenamento de dados multidimensionais e, portanto, são chamados de MultiIndex. Eles precisam ser alterados para saber como corrigir o erro de análise.
Os pandas da linguagem Python ajudam a realizar as operações SQL ou no estilo de banco de dados com a máxima perfeição para evitar erros na análise do texto x. Ele também contém algumas ferramentas de IO que ajudam na análise dos arquivos de CSV, MS Excel, JSON, HDF5 e outros formatos de dados.
Processo de análise de texto usando a classe DataFrame
Para saber como analisar texto, você pode usar o processo padrão usando a classe DataFrame fornecida nesta seção.
- Decifre o formato de dados dos dados de entrada.
- Decida os dados de saída dos dados, como CSV ou valor separado por vírgula.
- Escreva no código um tipo de dado primitivo como list ou dict.
Nota: Escrever o código em um DataFrame vazio pode ser tedioso e complexo. Os pandas permitem criar os dados na classe DataFrame a partir desses tipos de dados. Portanto, os dados no tipo de dados primitivo podem ser facilmente analisados para o formato de dados necessário.
- Analise os dados usando a ferramenta de análise de dados, pandas DataFrame, e imprima o resultado.
Opção I: Formato Padrão
O método padrão para formatar qualquer arquivo com um determinado formato de dados, como CSV, é explicado aqui.
- Salve o arquivo com os valores de dados localmente em seu PC. Por exemplo, você pode nomear o arquivo data.txt.
- Importe o arquivo em pandas com um nome específico e importe os dados para outra variável. Por exemplo, os pandas da linguagem são importados para o nome pd no código fornecido.
- A importação deve ter um código completo com o detalhe do nome do arquivo de entrada, a função e o formato do arquivo de entrada.
Nota: Aqui, a variável chamada res é usada para executar a função de leitura dos dados no arquivo data.txt usando os pandas importados em pd. O formato de dados do texto de entrada é especificado no formato CSV.
- Chame o tipo de arquivo nomeado e analise o texto analisado no resultado impresso. Por exemplo, o comando res após a execução da linha de comando ajudará na impressão do texto analisado.
Um código de exemplo para o processo explicado acima é fornecido abaixo e ajudará a entender como analisar o texto.
import pandas as pd res = pd.read_csv(‘data.txt’) res
Nesse caso, se você inserir os valores de dados no arquivo data.txt, como [1,2,3]ele seria analisado e exibido como 1 2 3.
Opção II: Método String
Se o texto fornecido ao código contiver apenas strings ou caracteres alfa, os caracteres especiais na string, como vírgulas, espaço, etc., podem ser usados para separar e analisar o texto. O processo é semelhante às operações de string internas comuns. Para descobrir como corrigir o erro de análise, você deve seguir o processo de análise do texto usando esta opção explicado abaixo.
- Os dados são extraídos da string e todos os caracteres especiais que separam o texto são anotados.
Por exemplo, no código abaixo, os caracteres especiais na string my_string, que são ‘,’ e ‘:’ são identificados. Este processo deve ser feito com cuidado para evitar erros na análise do texto x.
- O texto na string é dividido individualmente com base nos valores e na posição dos caracteres especiais.
Por exemplo, a string é dividida em valores de dados de texto com base nos caracteres especiais identificados usando o comando split.
- Os valores de dados da string são impressos sozinhos como o texto analisado. Aqui, a instrução print é usada para imprimir o valor dos dados analisados do texto.
O código de exemplo para o processo explicado acima é fornecido abaixo.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
Nesse caso, o resultado da string analisada seria exibido conforme mostrado abaixo.
Names: [‘Tech’, ‘computer’]
Para obter melhor clareza e saber como analisar o texto ao usar o texto da string, um loop for é utilizado e o código é modificado da seguinte maneira.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
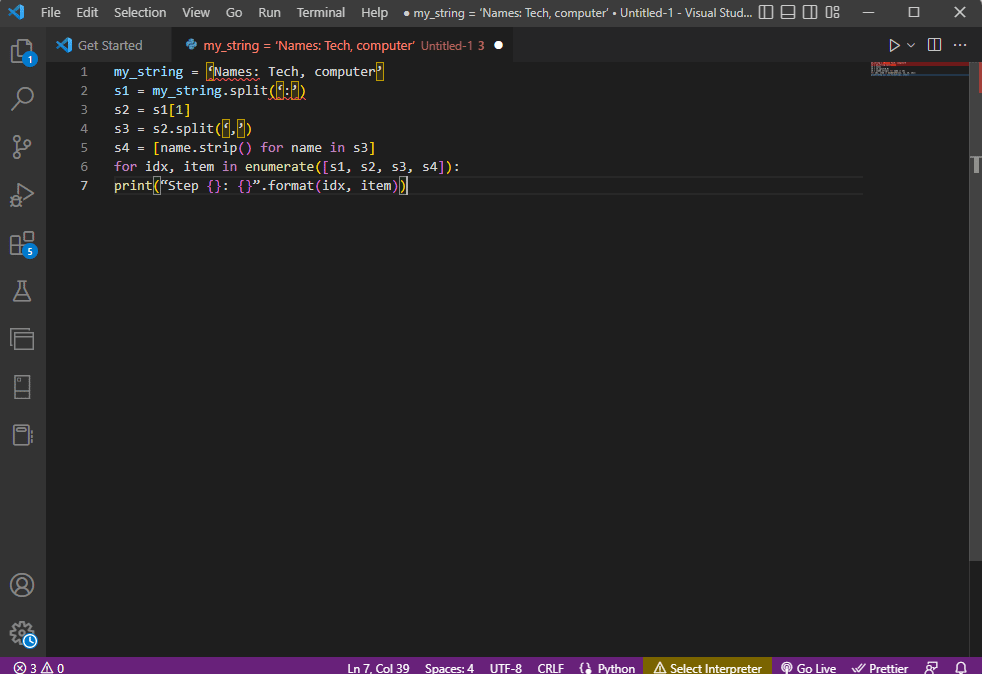
O resultado do texto analisado para cada uma dessas etapas é exibido conforme indicado abaixo. Você pode observar que, na Etapa 0, a string é separada com base no caractere especial : e os valores de dados de texto são separados com base no caractere em etapas posteriores.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Opção III: Analisando Arquivo Complexo
Na maioria dos casos, os dados do arquivo que precisam ser analisados contêm vários tipos de dados e valores de dados. Nesse caso, pode ser difícil analisar o arquivo usando os métodos explicados anteriormente.
Os recursos de analisar os dados complexos no arquivo são fazer com que os valores dos dados sejam exibidos em um formato tabular.
- O Título ou Metadados dos valores é impresso na parte superior do arquivo,
- As variáveis e campos são impressos na saída em forma de tabela e
- Os valores de dados formam uma chave composta.
Antes de se aprofundar em aprender a analisar texto neste método, é necessário aprender alguns conceitos básicos. A análise dos valores de dados é feita com base em expressões regulares ou Regex.
Padrões Regex
Para saber como corrigir o erro de análise, você deve garantir que os padrões regex nas expressões sejam adequados. O código para analisar os valores de dados das strings envolveria os padrões Regex comuns listados abaixo nesta seção.
-
‘d’: corresponde ao dígito decimal na string,
-
‘s’: corresponde ao caractere de espaço em branco,
-
‘w’: corresponde ao caractere alfanumérico,
-
‘+’ ou ‘*’ : executa uma correspondência gulosa combinando um ou mais caracteres nas strings,
-
‘a-z’: corresponde aos grupos de letras minúsculas nos valores de dados de texto,
-
‘A-Z’ ou ‘a-z’ : corresponde aos grupos de letras maiúsculas e minúsculas da string e
-
‘0-9’ : corresponde aos valores numéricos.
Expressões regulares
Os módulos de expressão regular são uma parte importante do pacote pandas na linguagem Python e um re errado pode levar a um erro na análise do texto x. É uma pequena linguagem incorporada dentro do Python para encontrar o padrão de string na expressão. Expressões Regulares ou Regex são strings com sintaxe especial. Ele permite que o usuário combine padrões em outras strings com base nos valores nas strings.
O Regex é criado com base no tipo de dados e no requisito da expressão na string, como ‘String = (.*)n. O regex é usado antes do padrão em cada expressão. Os símbolos usados nas expressões regulares estão listados abaixo e ajudarão a saber como analisar o texto.
-
. : para recuperar qualquer caractere dos dados,
-
* : usa zero ou mais dados da expressão anterior,
-
(.*): para agrupar uma parte da expressão regular entre parênteses,
-
n : Cria um novo caractere de linha no final da linha no código,
-
d : cria um valor integral curto no intervalo de 0 a 9,
-
+ : usa um ou mais dados da expressão anterior e
-
| : crie uma instrução lógica; usado para ou expressões.
Objetos Regex
O RegexObject é um valor de retorno para a função de compilação e é usado para retornar um MatchObject se a expressão corresponder ao valor de correspondência.
1. MatchObject
Como o valor booleano do MatchObject é sempre True, você pode usar uma instrução if para identificar as correspondências positivas no objeto. No caso de usar a instrução if, o grupo referido pelo índice é usado para descobrir a correspondência do objeto na expressão.
-
group() retorna um ou mais subgrupos de correspondência,
-
group(0) retorna a correspondência inteira,
-
group(1) retorna o primeiro subgrupo entre parênteses e
- Ao nos referirmos a vários grupos, devemos usar uma extensão específica do python. Esta extensão é usada para especificar o nome do grupo no qual a correspondência deve ser encontrada. A extensão específica é fornecida dentro do grupo entre parênteses. Por exemplo, a expressão (?P
regex1) se referiria ao grupo específico com o nome group1 e verificaria a correspondência na expressão regular, regex1. Para aprender como corrigir o erro de análise, você deve verificar se o grupo está apontado corretamente.
2. Métodos de MatchObject
Ao descobrir como analisar o texto, é importante saber que o MatchObject possui dois métodos básicos, conforme listado abaixo. Se o MatchObject for encontrado na expressão especificada, ele retornará sua instância, caso contrário, retornará None.
- O método match(string) é usado para encontrar as correspondências da string no início da expressão regular e
- O método search(string) é usado para varrer a string para encontrar a localização de uma correspondência na expressão regular.
Funções de expressão regular
Funções Regex são linhas de código que são usadas para executar uma determinada função conforme especificado pelo usuário a partir do conjunto de valores de dados adquiridos.
Nota: Para escrever as funções, strings brutas são usadas para as expressões regulares para evitar erros na análise do texto x. Isso é feito adicionando o subscrito r antes de cada padrão na expressão.
As funções comuns usadas nas expressões são explicadas abaixo.
1. re.findall()
Esta função retorna todos os padrões na string se uma correspondência for encontrada e retorna uma lista vazia se nenhuma correspondência for encontrada. Por exemplo, a função, string = re.findall(‘[aeiou]’, regex_filename) é usado para encontrar a ocorrência da vogal no nome do arquivo.
2. re.split()
Esta função é usada para dividir a string no caso de uma correspondência com um caractere especificado, como espaço. Caso nenhuma correspondência seja encontrada, ele retorna uma string vazia.
3. re.sub()
A função substitui o texto correspondente pelo conteúdo da variável de substituição fornecida. Ao contrário de outras funções, se nenhum padrão for encontrado, a string original será retornada.
4. re.pesquisar()
Uma das funções básicas para ajudar a aprender a analisar texto é a função de pesquisa. Ele ajuda a pesquisar o padrão na string e retornar o objeto de correspondência. Se a pesquisa falhar na identificação da correspondência, nenhum valor será retornado.
5. re.compilar (padrão)
Essa função é usada para compilar padrões de expressão regular em um RegexObject, que foi discutido anteriormente.
Outros requerimentos
Os requisitos listados são um recurso adicional usado por programadores avançados na análise de dados.
- Para visualizar a expressão regular, o regexper é usado e
- Para testar a expressão regular, regex101 é usado.
Processo de análise de texto
O método para analisar o texto nesta opção complexa é descrito abaixo.
- O primeiro passo é entender o formato de entrada lendo o conteúdo do arquivo. Por exemplo, as funções with open e read() são usadas para abrir e ler o conteúdo do arquivo chamado sample. O arquivo de amostra possui o conteúdo do arquivo file.txt; para aprender a corrigir o erro de análise, o arquivo deve ser lido completamente.
- O conteúdo do arquivo é impresso para analisar os dados manualmente para descobrir os metadados dos valores. Aqui, a função print() é usada para imprimir o conteúdo do arquivo de amostra.
- Os pacotes de dados necessários para analisar o texto são importados para o código e um nome é dado à classe para posterior codificação. Aqui, as expressões regulares e os pandas são importados.
- As expressões regulares necessárias para o código são definidas no arquivo incluindo o padrão regex e a função regex. Isso permite que o objeto de texto ou corpus pegue o código para análise de dados.
- Para saber como analisar o texto, você pode consultar o código de exemplo fornecido aqui. A função compile() é usada para compilar a string do grupo stringname1 do arquivo filename. A função para verificar correspondências na regex é usada pelo comando ief_parse_line(line),
- O analisador de linha para o código é escrito usando o def_parse_file(filepath), no qual a função definida verifica todas as correspondências de regex na função especificada. Aqui, o método regex search() procura a chave rx no arquivo filename e retorna a chave e a correspondência da primeira regex correspondente. Qualquer problema com a etapa pode levar a um erro na análise do texto x.
- O próximo passo é escrever um Analisador de Arquivos usando a função de analisador de arquivos, que é def_parse_file(filepath). Uma lista vazia é criada para coletar os dados do código, pois data = []a correspondência é verificada em cada linha por match = _parse_line(line) e os dados do valor exato são retornados com base no tipo de dados.
- Para extrair o número e o valor da tabela, é usado o comando line.strip().split(‘,’). O comando row{} é usado para criar um dicionário com a linha de dados. O comando data.append(row) é usado para compreender os dados e analisá-los em um formato tabular.
O comando data = pd.DataFrame(data) é usado para criar um DataFrame pandas a partir dos valores dict. Alternativamente, você pode usar os seguintes comandos para a respectiva finalidade, conforme indicado abaixo.
-
data.set_index([‘string’, ‘integer’]inplace=True) para definir o índice da Tabela.
-
data = data.groupby(level=data.index.names).first() para consolidar e remover nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) para atualizar a pontuação de float para valor inteiro.
A etapa final para saber como analisar o texto é testar o analisador usando a instrução if, atribuindo os valores a uma variável data e imprimindo-a usando o comando print(data).
O código de exemplo para a explicação acima é fornecido aqui.
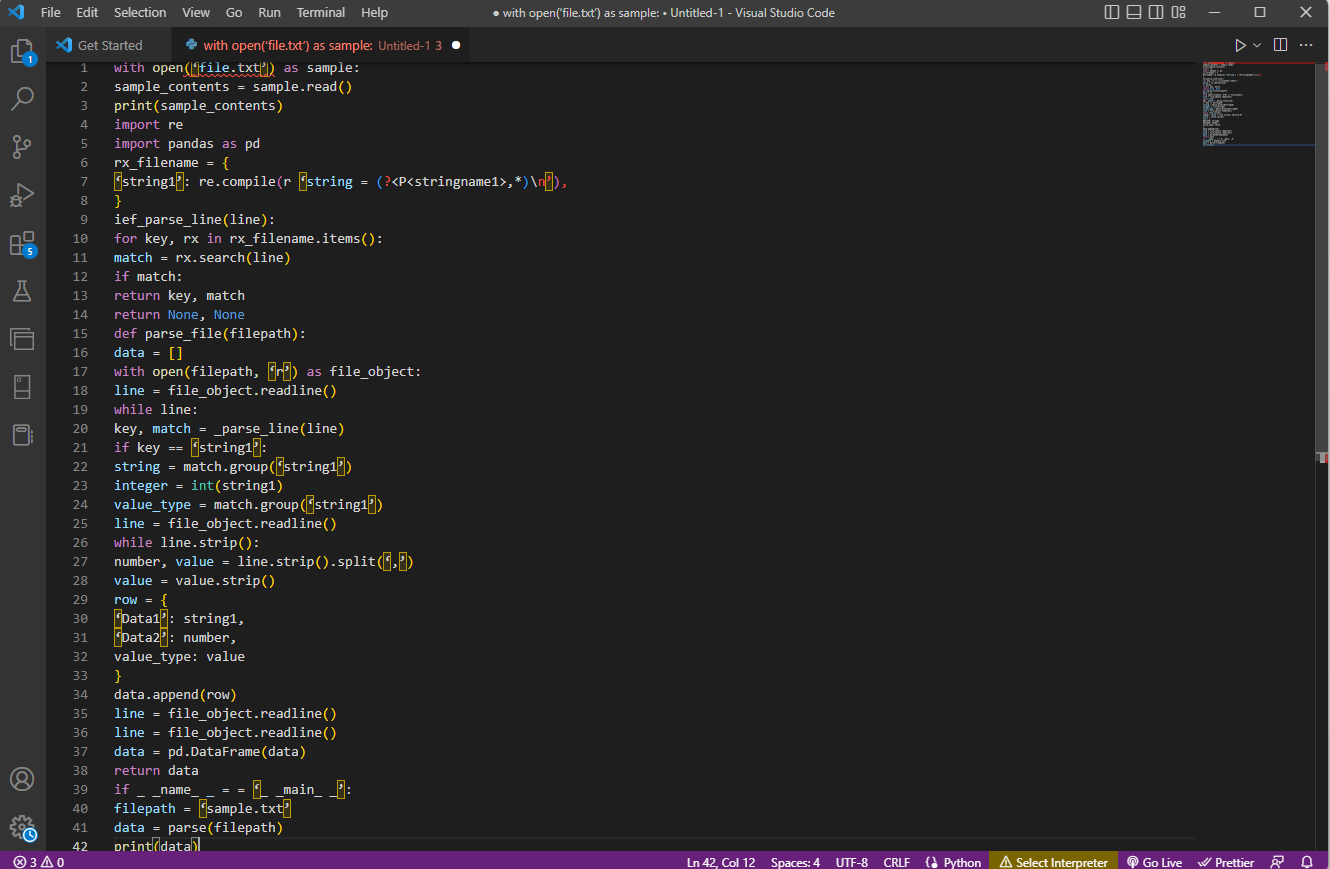
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Método 2: por meio da tokenização de palavras
O processo de conversão de um texto ou corpus em tokens ou partes menores com base em certas regras é chamado de Tokenização. Para aprender a corrigir o erro de análise, é importante analisar os comandos de tokenização de palavras no código. Semelhante ao regex, regras próprias podem ser criadas neste método e auxilia nas tarefas de pré-processamento de texto, como mapeamento de partes da fala. Além disso, atividades como encontrar e combinar palavras comuns, limpar texto e preparar os dados para técnicas avançadas de análise de texto, como análise de sentimentos, são realizadas nesse método. Se a tokenização for imprópria, pode ocorrer um erro no texto de análise x.
Biblioteca NTlk
O processo conta com a ajuda da popular biblioteca de ferramentas de linguagem chamada nltk, que possui um rico conjunto de funções para realizar muitos trabalhos de NLP. Estes podem ser baixados através do Pip ou Pip Installs Packages. Para saber como analisar texto, você pode usar o pacote base da distribuição Anaconda que inclui a biblioteca por padrão.
Formas de tokenização
As formas comuns desse método são tokenização de palavras e tokenização de sentenças. Devido ao token de nível de palavra, o primeiro imprime uma palavra apenas uma vez, enquanto o último imprime a palavra no nível de sentença.
Processo de análise de texto
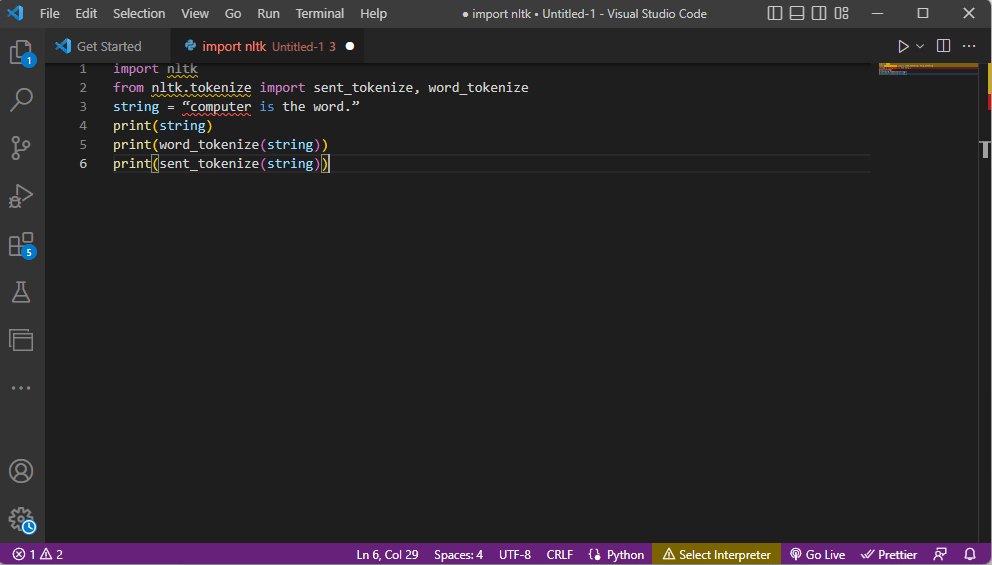
- A biblioteca do kit de ferramentas ntlk é importada e os formulários de tokenização são importados da biblioteca.
- Uma string é fornecida e os comandos para executar a tokenização são fornecidos.
- Enquanto a string é impressa, a saída seria computador é a palavra.
- No caso de tokenização de palavras ou word_tokenize(), cada palavra na frase é impressa individualmente dentro do ” e é separada por uma vírgula. A saída para o comando seria o ‘computador’, ‘é’, ‘o’, ‘palavra’, ‘.’
- No caso de tokenização de frases ou sent_tokenize(), as frases individuais são colocadas dentro do ” e a repetição de palavras é permitida. A saída para o comando seria ‘computador é a palavra.’
O código que explica as etapas para tokenização acima é fornecido aqui.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Método 3: por meio da classe DocParser
Semelhante à classe DataFrame, a classe DocParser pode ser usada para analisar o texto no código. A classe permite que você chame a função de análise com o caminho do arquivo.
Processo de análise de texto
Para saber como analisar texto usando a classe DocParser, siga as instruções abaixo.
- A função get_format(filename) é usada para extrair a extensão do arquivo, retorná-la para uma variável definida para a função e passá-la para a próxima função. Por exemplo, p1 = get_format(filename) extrairia a extensão do arquivo filename, definiria para a variável p1 e passaria para a próxima função.
- Uma estrutura lógica com outras funções é construída usando as instruções e funções if-elif-else.
- Se a extensão do arquivo for válida e a estrutura for lógica, a função get_parser será usada para analisar os dados no caminho do arquivo e retornar o objeto string ao usuário.
Nota: Para saber como corrigir o erro de análise, esta função deve ser implementada corretamente.
- A análise dos valores de dados é feita com a extensão de arquivo do arquivo. A implementação concreta da classe, que são parse_txt ou parse_docx, é usada para gerar objetos string a partir das partes do tipo de arquivo fornecido.
- A análise pode ser feita para arquivos de outras extensões legíveis, como parse_pdf, parse_html e parse_pptx.
- Os valores de dados e a interface podem ser importados para aplicativos com instruções de importação e instanciar um objeto DocParser. Isso pode ser feito analisando arquivos na linguagem Python, como parse_file.py. Esta operação deve ser feita com cuidado para evitar erros na análise do texto x.
Método 4: Através da ferramenta Parse Text
A ferramenta de texto Parse é usada para extrair dados específicos de variáveis e mapeá-los para outras variáveis. Isso é independente de quaisquer outras ferramentas usadas em uma tarefa e a ferramenta BPA Platform é usada para consumir e gerar variáveis. Use o link fornecido aqui para acessar o Ferramenta de análise de texto online e use as respostas dadas anteriormente sobre como analisar o texto.
Método 5: por meio de TextFieldParser (Visual Basic)
O TextFieldParser utilizou objetos para analisar e processar arquivos muito grandes que são estruturados e delimitados. A largura e a coluna de texto, como arquivos de log ou informações do banco de dados legado, podem ser usadas neste método. O método de análise é semelhante à iteração do código em um arquivo de texto e é usado principalmente para extrair campos de texto semelhantes aos métodos de manipulação de strings. Isso é feito para tokenizar strings e campos delimitados de várias larguras usando o delimitador definido, como vírgula ou espaço de tabulação.
Funções para analisar texto
As seguintes funções podem ser usadas para analisar o texto neste método.
- Para definir um delimitador, o SetDelimiters é usado. Por exemplo, o comando testReader.SetDelimiters (vbTab) é usado para definir o espaço de tabulação como delimitador.
- Para definir uma largura de campo para um valor inteiro positivo para uma largura de campo fixa de arquivos de texto, você pode usar o comando testReader.SetFieldWidths (integer).
- Para testar o tipo de campo do texto, você pode usar o seguinte comando testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Métodos para encontrar MatchObject
Existem dois métodos básicos para localizar o MatchObject no código ou no texto analisado.
- O primeiro método é definir o formato e percorrer o arquivo usando o método ReadFields. Este método ajudaria no processamento de cada linha do código.
- O método PeekChars é usado para verificar cada campo individualmente antes de lê-lo, definir vários formatos e reagir.
Em ambos os casos, se um campo não corresponder ao formato especificado ao executar a análise ou ao descobrir como analisar o texto, uma exceção MalformedLineException será retornada.
Dica profissional: como analisar texto através do MS Excel
Como um método final e simples para analisar o texto, você pode usar o MS Excel app como um analisador para criar arquivos delimitados por tabulações e vírgulas. Isso ajudaria na verificação cruzada com o resultado analisado e ajudaria a encontrar como corrigir o erro de análise.
1. Selecione os valores de dados no arquivo de origem e pressione as teclas Ctrl + C juntas para copiar o arquivo.
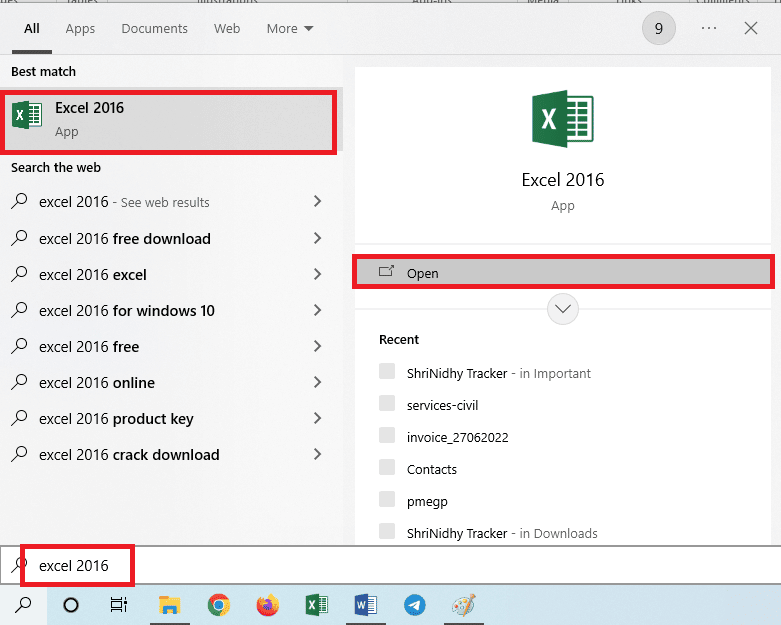
2. Abra o aplicativo Excel usando a barra de pesquisa do Windows.
3. Clique na célula A1 e pressione as teclas Ctrl + V simultaneamente para colar o texto copiado.
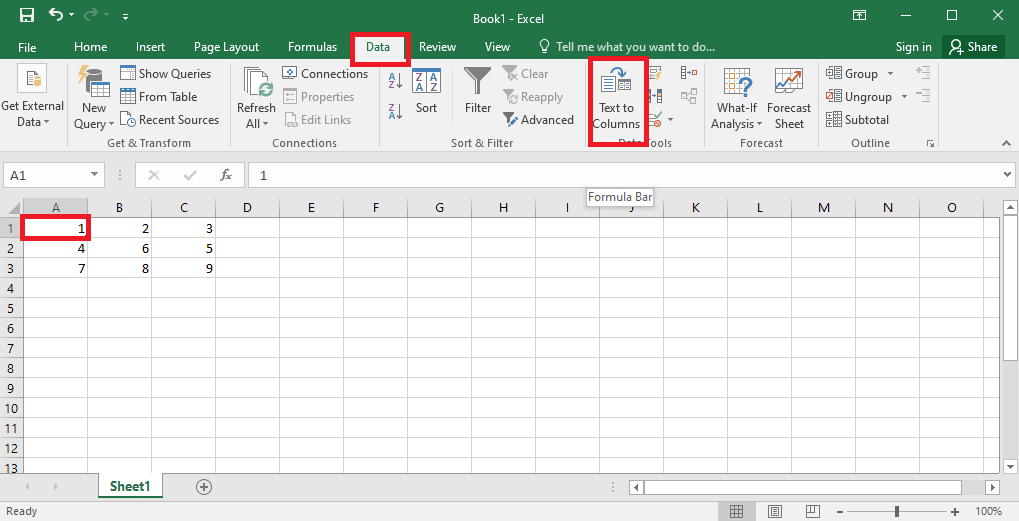
4. Selecione a célula A1, navegue até a guia Dados e clique na opção Texto para colunas na seção Ferramentas de dados.
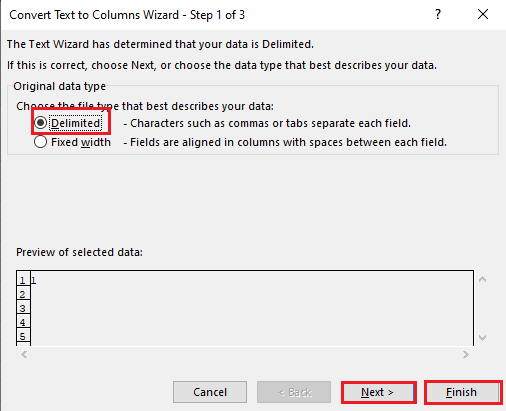
5A. Selecione a opção Delimitado se uma vírgula ou espaço de tabulação for usado como separador e clique nos botões Avançar e Concluir.
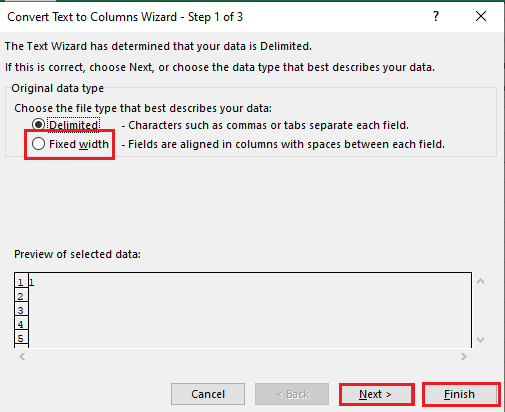
5B. Selecione a opção Largura fixa, atribua um valor para o separador e clique nos botões Avançar e Concluir.
Como corrigir erro de análise
Erro no texto de análise x pode ocorrer em dispositivos Android como Erro de análise: houve um problema ao analisar o pacote. Isso geralmente ocorre quando o aplicativo não é instalado na Google Play Store ou durante a execução de um aplicativo de terceiros.
O texto de erro x pode ocorrer se a lista de vetores de caracteres estiver em loop e outras funções formarem um modelo linear para calcular os valores dos dados. A mensagem de erro é Error in parse(text = x, keep.source = FALSE):
Você pode ler o artigo sobre como corrigir o erro de análise no Android para aprender as causas e os métodos para corrigir o erro.
Além das soluções no guia, você pode tentar as seguintes correções.
- Baixando novamente o arquivo .apk ou restaurando o nome do arquivo.
- Restaurar alterações no arquivo Androidmanifest.xml, se você tiver habilidades de programação em nível de especialista.
***
O artigo ajuda a ensinar como analisar texto e aprender a corrigir erros de análise. Deixe-nos saber qual método ajudou a corrigir o erro no texto de análise x e qual método de análise é o preferido. Por favor, compartilhe suas sugestões e dúvidas na seção de comentários abaixo.