
Construir um sistema de software automatizado significou configurar vários servidores com configuração de CPU dedicada, memória, armazenamento e outros recursos por muitos anos. Em seguida, formou-se uma equipe de administradores para gerenciar esses sistemas. Em seguida, a equipe de desenvolvimento assumiu a infraestrutura e começou a criar processos que conectam os servidores.
Esse processo pode ser complicado porque envolve muitos grupos diferentes trabalhando juntos em direção a um objetivo comum. Esses conflitos de interesse podem ser um problema.
Também pode ser bastante caro. Isso requer que você tenha administradores em sua folha de pagamento. Os servidores, que rodam continuamente, consomem recursos apesar de não serem utilizados.
Para manter o melhor desempenho ao longo do tempo, você precisa de uma solução de dimensionamento automático que dimensione automaticamente os recursos do servidor.
A plataforma de nuvem tem uma vantagem: permite criar uma arquitetura de ponta a ponta sem a necessidade de configuração de cluster de servidor. Do ponto de vista da administração, não há nada a manter.
Esta é uma opção econômica para startups e fases de projetos de produto mínimo viável (MVP). É um bom ponto de partida se for difícil prever futuras cargas de produção e atividade do usuário. É aqui que pode ser difícil determinar a configuração dos servidores de cluster.
A automatização de processos por meio de serviços em nuvem serverless é o diferencial da arquitetura serverless. Ele conecta serviços e produz resultados semelhantes aos servidores de cluster tradicionais.
Este é um exemplo de construção de tal arquitetura usando apenas serviços nativos da AWS.
últimas postagens
Escolhendo o fluxo sem servidor de serviços
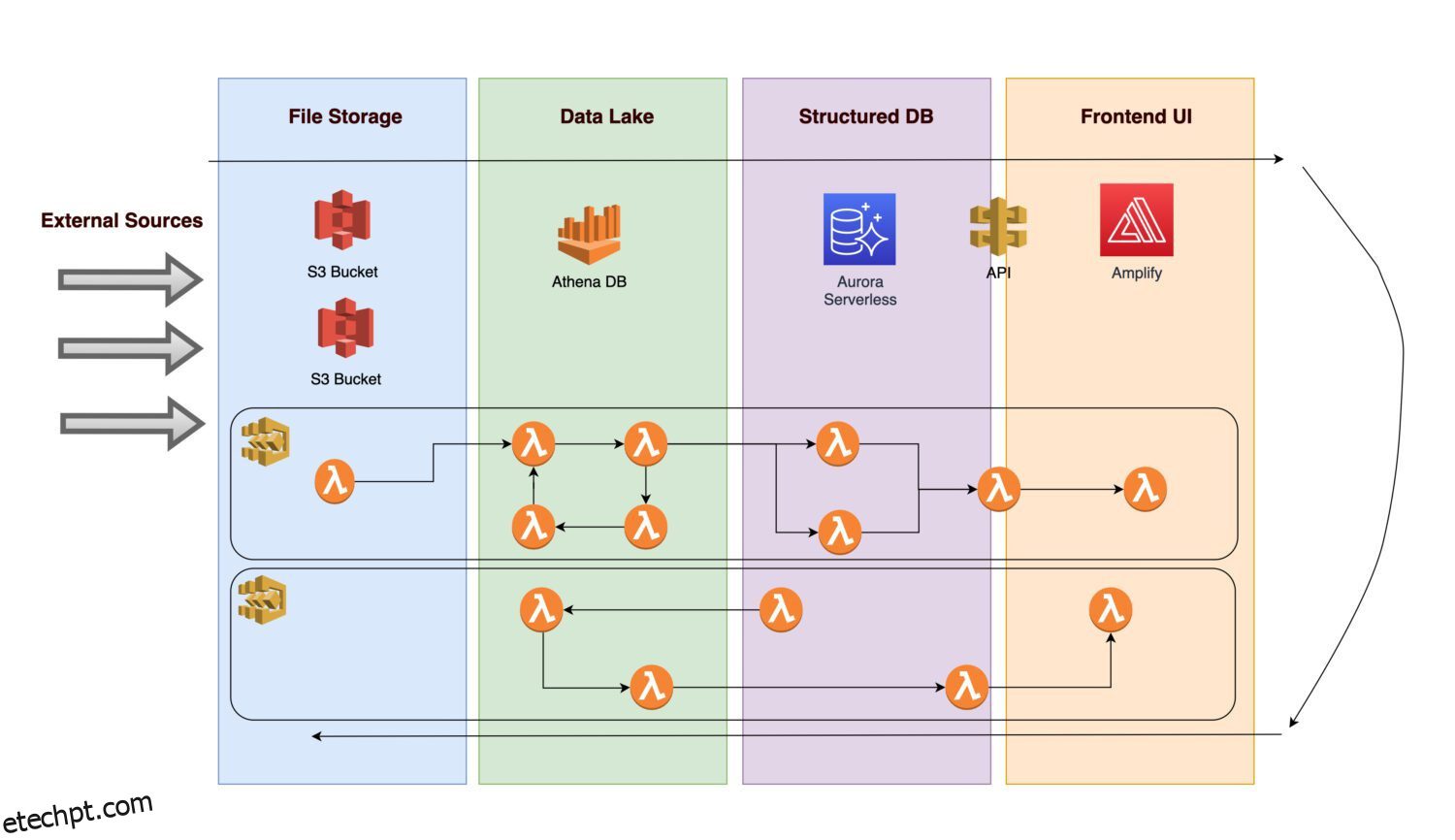
Imagine que você gostaria de criar uma plataforma para coletar vários dados e imagens (ou fotos) da infraestrutura de alguns ativos concretos (pode ser qualquer ativo de manufatura ou utilitário).
- Para possibilitar análises futuras, é necessário que os dados recebidos sejam primeiro ingeridos.
- Depois de aplicar as regras de negócios, um procedimento de back-end salva as saídas calculadas como informações normalizadas em um banco de dados relacional.
- Um front-end de aplicativo que exibe dados limpos normalizados permite que os usuários visualizem os resultados.
Vamos examinar quais componentes a arquitetura pode incluir.
Blocos AWS S3
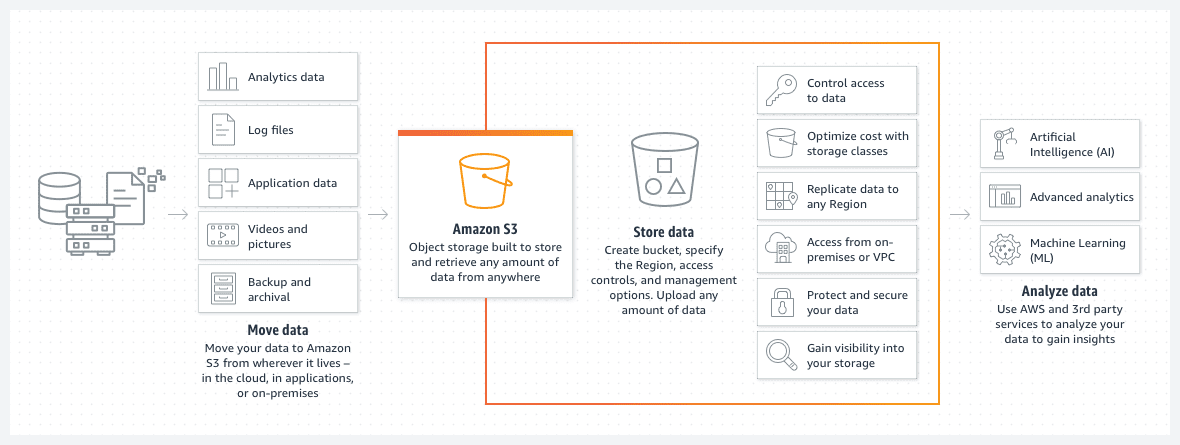 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Os baldes do Amazon S3 são uma ótima maneira de armazenar arquivos ou imagens na nuvem AWS. O preço do armazenamento no bucket S3 é notavelmente baixo. Além disso, a introdução de uma política de ciclo de vida do bucket do S3 reduz ainda mais esse preço.
Essa política moverá automaticamente os arquivos mais antigos para diferentes classes de buckets do S3, como um arquivo ou acesso profundo ao arquivo. As classes também diferem pela velocidade do tempo de acesso, mas para dados antigos, isso será menos problemático. Serve principalmente para acessar os dados arquivados em caso de um evento urgente, e não para necessidades de operações padrão.
- Você pode organizar seus dados em subpastas.
- Você deve definir restrições de permissões apropriadas.
- Adicione tags aos buckets para torná-los fáceis de identificar e para possível uso nas políticas dinâmicas de bucket do S3.
- O bucket não tem servidor por design. É simplesmente um espaço de armazenamento para seus dados.
Um bucket S3 é sem servidor por design. É simplesmente um espaço de armazenamento para seus dados.
Banco de dados AWS Athena
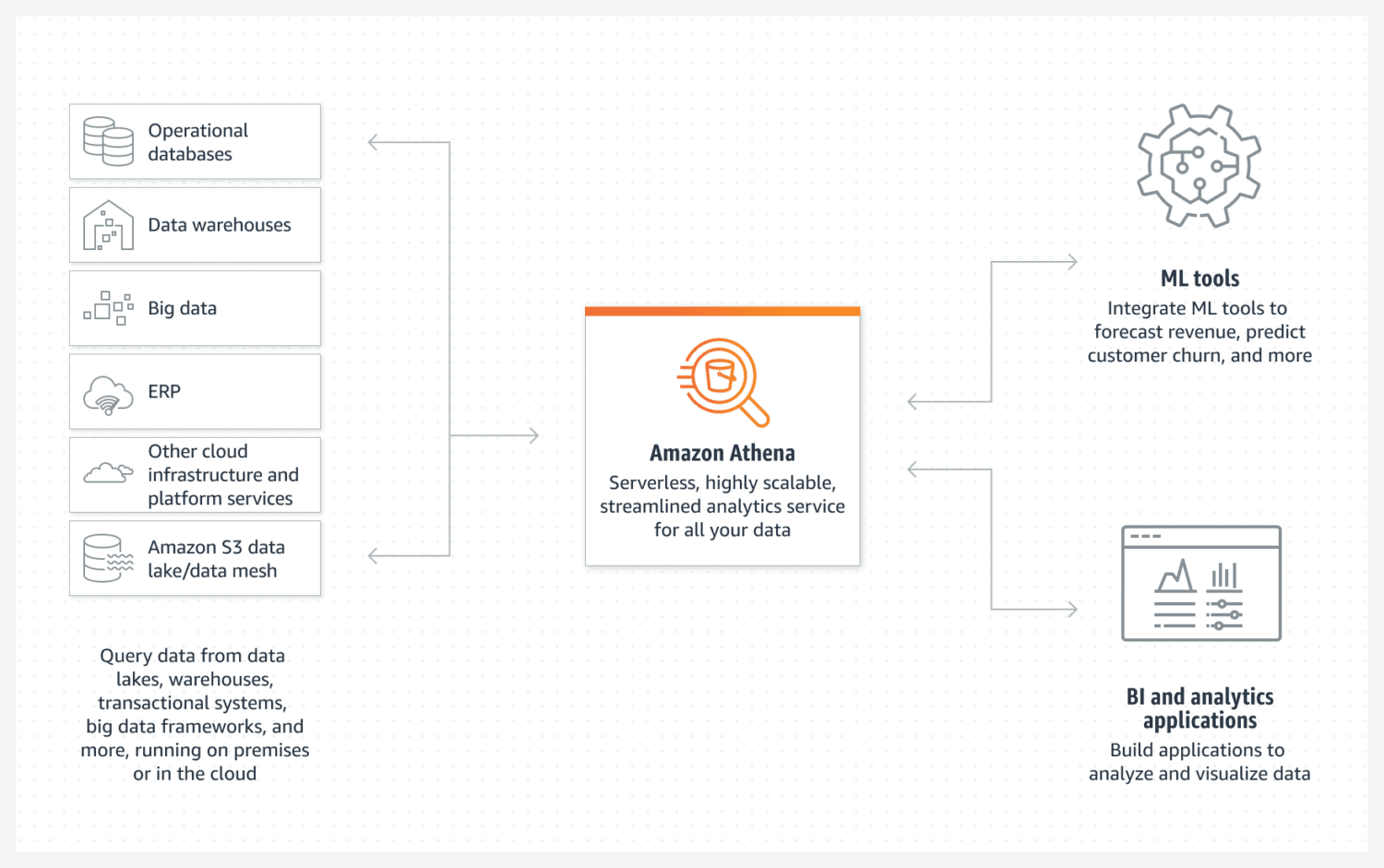 Fonte: aws.amazon.com
Fonte: aws.amazon.com
O Athena facilita a criação de um data lake básico da AWS. É um banco de dados sem servidores que utiliza um balde S3 para armazenar seus dados. A organização dos dados é mantida por formatos de arquivos estruturados, como parquet ou arquivos de valores separados por vírgula (CSV). O bucket do S3 contém os arquivos e o Athena se refere a eles sempre que os processos selecionam os dados do banco de dados.
Esteja ciente de que o Athena não oferece suporte a várias funcionalidades consideradas padrão, por exemplo, instruções de atualização. É por isso que você precisa olhar para o Athena como uma opção muito simples.
No entanto, ele suporta indexação e particionamento. Ele também pode escalar horizontalmente com muita facilidade, pois isso é tão complexo quanto adicionar novos baldes à infraestrutura. Para criação de data lake simples, mas funcional, isso ainda pode ser suficiente na maioria dos casos.
Para um bom desempenho, selecionar o melhor design de dados com foco no uso futuro é essencial. É fundamental ter muita clareza sobre a forma como deseja selecionar os dados. É difícil recriar tabelas posteriormente, uma vez que elas já existem e estão preenchidas com muitos dados.
O Athena DB é uma ótima opção e uma boa opção para seu objetivo se você deseja criar um pool de dados simples e imutável que seja fácil de escalar horizontalmente ao longo do tempo.
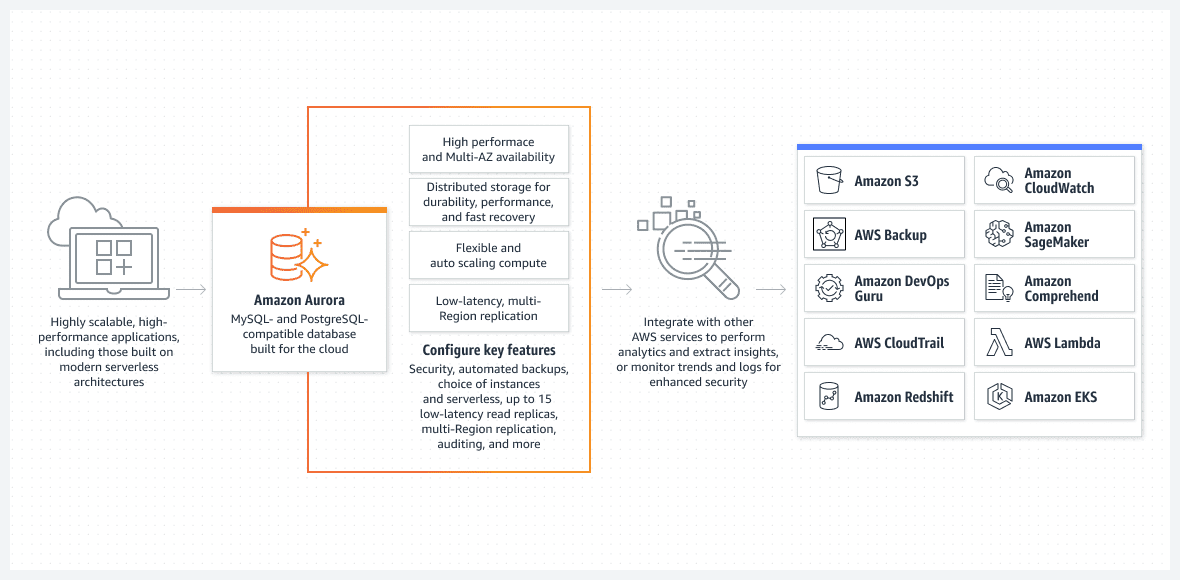
Banco de dados AWS Aurora
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
O Athena DB se destaca no armazenamento de dados não selecionados. Afinal, é assim que você deseja armazenar seu conteúdo original para maximizar sua reutilização futura. No entanto, é lento fornecer resultados selecionados para um aplicativo front-end.
Uma das melhores opções, principalmente do ponto de vista da configuração fácil de executar, é o banco de dados Aurora rodando no modo serverless.
O Aurora está longe de ser um banco de dados básico. É uma das soluções de banco de dados relacional nativas mais avançadas da AWS. É também uma solução de banco de dados relacional nativa altamente complexa que melhora a cada versão.
O Aurora é único porque pode ser executado no modo serverless, destacando-se de outros serviços relacionais. É assim que o modo funciona:
- Para configurar o cluster Aurora, use o console AWS. Você precisará especificar os níveis padrão de CPU e RAM, bem como o intervalo máximo da funcionalidade de dimensionamento automático. Isso afetará o desempenho que o cluster do Aurora pode adicionar ou remover dinamicamente. Com base na utilização atual do banco de dados, a AWS decide aumentar ou diminuir a escala.
- O cluster do Aurora não será iniciado a menos que o usuário ou processo inicie uma solicitação real. Por exemplo, quando o processamento em lote programado é iniciado. Ou se o aplicativo executar uma chamada de API de back-end para recuperar dados de um banco de dados. O banco de dados abrirá automaticamente e permanecerá ativo por um tempo pré-determinado após a conclusão dos processos de solicitação.
- O cluster do Aurora será encerrado automaticamente se não houver mais trabalho no banco de dados.
Para enfatizar mais uma vez, o Aurora DB sem servidor é executado apenas quando precisa fazer um trabalho real. O cluster iniciado automaticamente será desligado novamente se não estiver processando nenhum trabalho. O trabalho real é o que você paga e não o seu tempo ocioso.
O Aurora sem servidor é totalmente gerenciado pela AWS e não requer um administrador.
AWS Amplify
Amplify oferece uma plataforma sem servidor para a implantação rápida de aplicativos front-end feitos com bibliotecas JavaScript e React. Não há necessidade de configurar servidores de cluster. Use o console da AWS para implantar o código diretamente ou use um pipeline DevOps automatizado.
Você pode chamar APIs de back-end para acessar dados armazenados em bancos de dados. Essas chamadas permitem que você acesse os dados reais no aplicativo front-end. A principal otimização de desempenho no back-end deve ser feita pela equipe. Você pode reduzir ainda mais a possibilidade de resposta lenta na interface do usuário se projetar instruções de seleção efetivas diretamente dentro das chamadas de API.
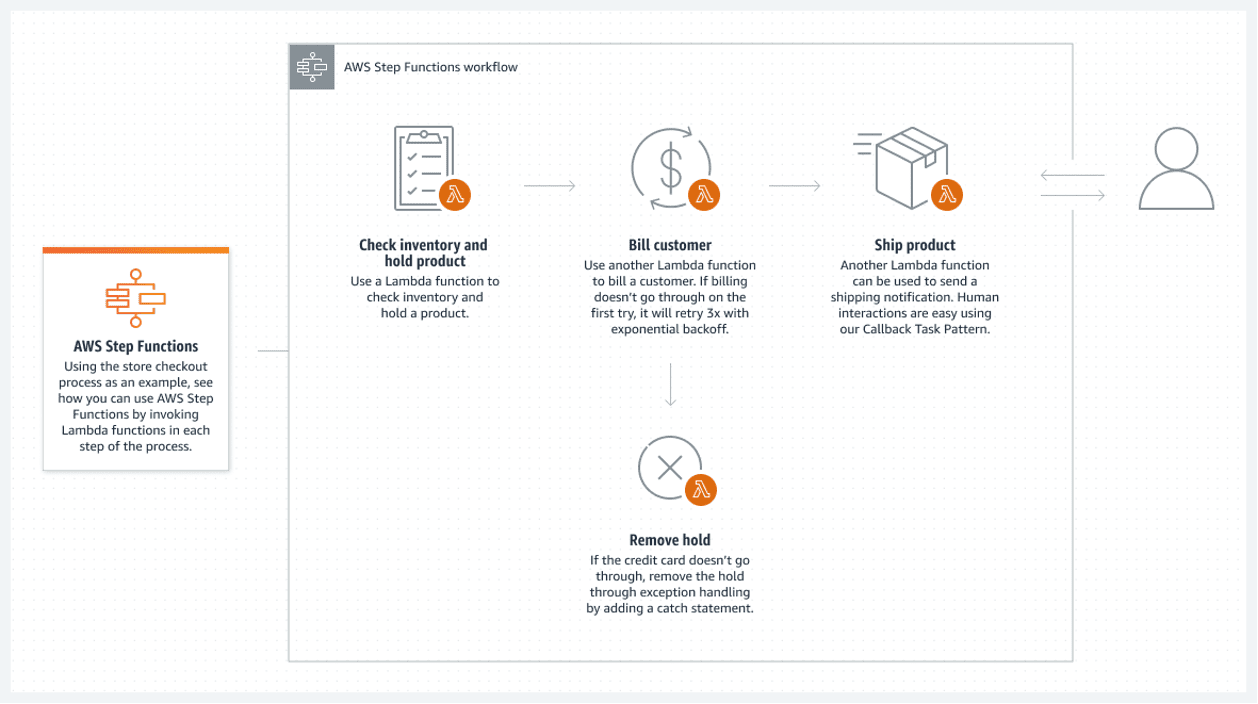
Funções de etapas da AWS
 Fonte: aws.amazon.com
Fonte: aws.amazon.com
Embora todos os principais componentes de um sistema sejam sem servidor, isso não garante uma arquitetura totalmente sem servidor. Isso só é possível se todos os processos em lote entre os componentes forem sem servidor.
As funções AWS Step fornecem a melhor solução na nuvem AWS. Uma lista conectada de funções do AWS Lambda compõe a função de etapa. Essas funções criam um fluxograma com estados iniciais e finais claros. Uma função lambda, geralmente escrita nas linguagens Python ou Node JS, é um pedaço de código executável que processa o que for necessário.
Veja a seguir um exemplo de como você pode executar uma função de etapa:
Esse fluxo sem servidor tem uma grande desvantagem: cada função lambda pode ser executada por no máximo 15 minutos. Portanto, dividir o fluxo em funções lambda menores pode tornar isso menos problemático.
É possível chamar várias funções lambda simultaneamente em uma etapa, o que basicamente significa paralelizar uma etapa com vários lambdas executados simultaneamente. Apenas espere que todo o processamento lambda paralelo termine antes de continuar. Em seguida, prossiga para o próximo processamento lambda.
Palavras Finais
A arquitetura sem servidor oferece uma oportunidade única de criar uma plataforma de nuvem que cobre todo o cenário do sistema. Esta plataforma é escalável horizontalmente e tem baixos custos operacionais ao fazê-lo.
É a solução perfeita para projetos com orçamento limitado. É uma excelente opção de exploração, normalmente quando ninguém conhece a realidade da carga de produção. Isso é especialmente importante depois de ter integrado com êxito todos os usuários. É possível que as equipes de projeto ainda tenham uma visão geral de como o sistema funciona. Você pode ter todos esses benefícios e ainda não precisa aceitar compromissos.
Essa cobertura não será adequada para todos os casos, principalmente aqueles que envolvem alto uso de CPU. No entanto, a nuvem AWS está em constante evolução em termos de casos de uso sem servidor. Geralmente, é uma boa ideia realizar uma pesquisa completa antes de decidir sobre a opção sem servidor para seu próximo projeto de nuvem AWS.
A seguir, confira os melhores bancos de dados sem servidor para aplicativos modernos.