

Os dados se tornaram cada vez mais importantes para criar modelos de aprendizado de máquina, testar aplicativos e obter insights de negócios.
No entanto, para conformidade com os muitos regulamentos de dados, muitas vezes é guardado e estritamente protegido. O acesso a esses dados pode levar meses para obter as aprovações necessárias. Como alternativa, as empresas podem usar dados sintéticos.
últimas postagens
O que são dados sintéticos?
Crédito da foto: Twinify
Dados sintéticos são dados gerados artificialmente que se assemelham estatisticamente ao antigo conjunto de dados. Ele pode ser usado com dados reais para oferecer suporte e melhorar os modelos de IA ou pode ser usado como um substituto.
Como não pertence a nenhum titular de dados e não contém informações de identificação pessoal ou dados confidenciais, como números de previdência social, pode ser usado como uma alternativa de proteção de privacidade aos dados reais de produção.
Diferenças entre dados reais e sintéticos
- A diferença mais crucial está em como os dois tipos de dados são gerados. Dados reais vêm de assuntos reais cujos dados foram coletados durante pesquisas ou quando eles usaram seu aplicativo. Por outro lado, os dados sintéticos são gerados artificialmente, mas ainda se assemelham ao conjunto de dados original.
- A segunda diferença está nos regulamentos de proteção de dados que afetam dados reais e sintéticos. Com dados reais, os sujeitos devem ser capazes de saber quais dados sobre eles são coletados e por que são coletados, e há limites para como podem ser usados. No entanto, esses regulamentos não se aplicam mais a dados sintéticos porque os dados não podem ser atribuídos a um sujeito e não contêm informações pessoais.
- A terceira diferença está nas quantidades de dados disponíveis. Com dados reais, você só pode ter tanto quanto os usuários lhe dão. Por outro lado, você pode gerar quantos dados sintéticos desejar.
Por que você deve considerar o uso de dados sintéticos
- É relativamente mais barato produzir porque você pode gerar conjuntos de dados muito maiores, semelhantes ao conjunto de dados menor que você já possui. Isso significa que seus modelos de aprendizado de máquina terão mais dados para treinar.
- Os dados gerados são rotulados e limpos automaticamente para você. Isso significa que você não precisa gastar tempo fazendo o trabalho demorado de preparar os dados para aprendizado de máquina ou análise.
- Não há problemas de privacidade, pois os dados não são de identificação pessoal e não pertencem a um titular de dados. Isso significa que você pode usá-lo e compartilhá-lo livremente.
- Você pode superar o viés da IA garantindo que as classes minoritárias sejam bem representadas. Isso ajuda você a criar uma IA justa e responsável.
Como gerar dados sintéticos
Embora o processo de geração varie dependendo de qual ferramenta você está usando, geralmente o processo começa com a conexão de um gerador a um conjunto de dados existente. Depois disso, você identifica os campos de identificação pessoal em seu conjunto de dados e os rotula para exclusão ou ofuscação.
O gerador então começa a identificar os tipos de dados das colunas restantes e os padrões estatísticos nessas colunas. A partir daí, você pode gerar quantos dados sintéticos precisar.
Normalmente, você pode comparar os dados gerados com o conjunto de dados original para ver como os dados sintéticos se assemelham aos dados reais.
Agora, exploraremos as ferramentas para geração de dados sintéticos para treinar modelos de aprendizado de máquina.
Principalmente IA

Principalmente AI tem um gerador de dados sintéticos alimentado por AI que aprende com os padrões estatísticos do conjunto de dados original. A IA então gera personagens fictícios que se adaptam aos padrões aprendidos.
Com o Mostly AI, você pode gerar bancos de dados inteiros com integridade referencial. Você pode sintetizar todos os tipos de dados para ajudá-lo a criar melhores modelos de IA.
Synthesized.io

Synthesized.io é usado por empresas líderes para suas iniciativas de IA. Para usar o synthese.io, especifique os requisitos de dados em um arquivo de configuração YAML.
Em seguida, você cria um trabalho e o executa como parte de um pipeline de dados. Ele também possui um nível gratuito muito generoso que permite que você experimente e veja se ele atende às suas necessidades de dados.
YData

Com o YData, você pode gerar dados tabulares, de série temporal, transacionais, multitabelas e relacionais. Isso permite que você evite os problemas associados à coleta, compartilhamento e qualidade de dados.
Ele vem com uma IA e SDK para interagir com sua plataforma. Além disso, eles têm um nível gratuito generoso que você pode usar para demonstrar o produto.
Gretel AI

Gretel AI oferece APIs para gerar quantidades ilimitadas de dados sintéticos. Gretel tem um gerador de dados de código aberto que você pode instalar e usar.
Alternativamente, você pode usar sua API REST ou CLI, que terá um custo. Seu preço é, no entanto, razoável e escala com o tamanho do negócio.
cópulas
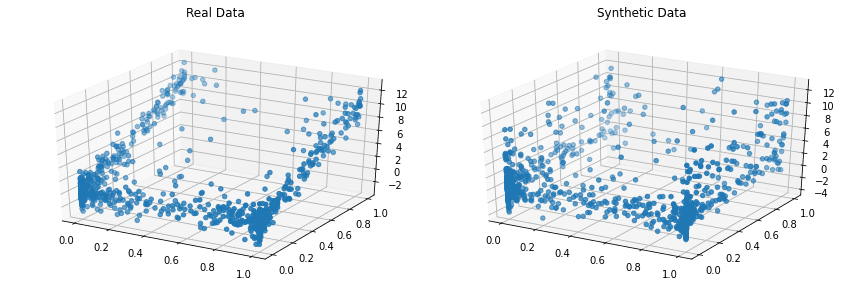
Copulas é uma biblioteca Python de código aberto para modelar distribuições multivariadas usando funções de cópula e gerando dados sintéticos que seguem as mesmas propriedades estatísticas.
O projeto começou em 2018 no MIT como parte do Synthetic Data Vault Project.
CTGAN
O CTGAN consiste em geradores que são capazes de aprender com dados reais de uma única tabela e gerar dados sintéticos a partir dos padrões identificados.
Ele é implementado como uma biblioteca Python de código aberto. A CTGAN, junto com a Copulas, faz parte do Projeto Cofre de Dados Sintéticos.
Sósia
DoppelGANger é uma implementação de código aberto de Generative Adversarial Networks para gerar dados sintéticos.
O DoppelGANger é útil para gerar dados de séries temporais e é usado por empresas como a Gretel AI. A biblioteca Python está disponível gratuitamente e é de código aberto.
sintetizador

Synth é um gerador de dados de código aberto que ajuda você a criar dados realistas de acordo com suas especificações, ocultar informações de identificação pessoal e desenvolver dados de teste para seus aplicativos.
Você pode usar o Synth para gerar séries em tempo real e dados relacionais para suas necessidades de aprendizado de máquina. Synth também é independente de banco de dados, para que você possa usá-lo com seus bancos de dados SQL e NoSQL.
SDV.dev
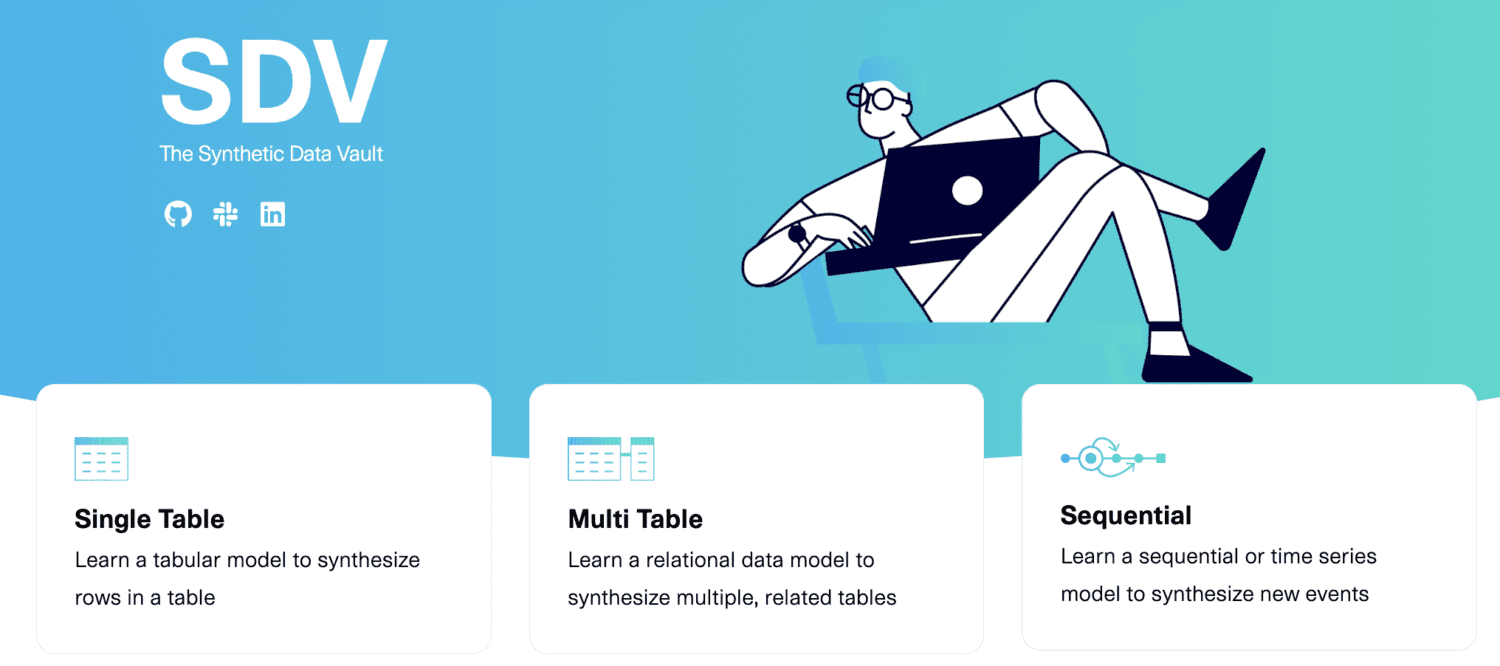
SDV significa Cofre de Dados Sintéticos. SDV.dev é um projeto de software que começou no MIT em 2016 e criou diferentes ferramentas para gerar dados sintéticos.
Essas ferramentas incluem Copulas, CTGAN, DeepEcho e RDT. Essas ferramentas são implementadas como bibliotecas Python de código aberto que você pode usar facilmente.
tofu
Tofu é uma biblioteca Python de código aberto para gerar dados sintéticos com base em dados de biobancos do Reino Unido. Ao contrário das ferramentas mencionadas anteriormente que o ajudarão a gerar qualquer tipo de dados com base em seu conjunto de dados existente, o Tofu gera dados que se assemelham apenas aos do biobanco.
O UK Biobank é um estudo sobre as características fenotípicas e genotípicas de 500.000 adultos de meia-idade do Reino Unido.
Twinify
Twinify é um pacote de software usado como uma biblioteca ou ferramenta de linha de comando para dados confidenciais gêmeos, produzindo dados sintéticos com distribuições estatísticas idênticas.

Para usar o Twinify, você fornece os dados reais como um arquivo CSV e aprende com os dados para produzir um modelo que pode ser usado para gerar dados sintéticos. É totalmente gratuito para usar.
Datanamic
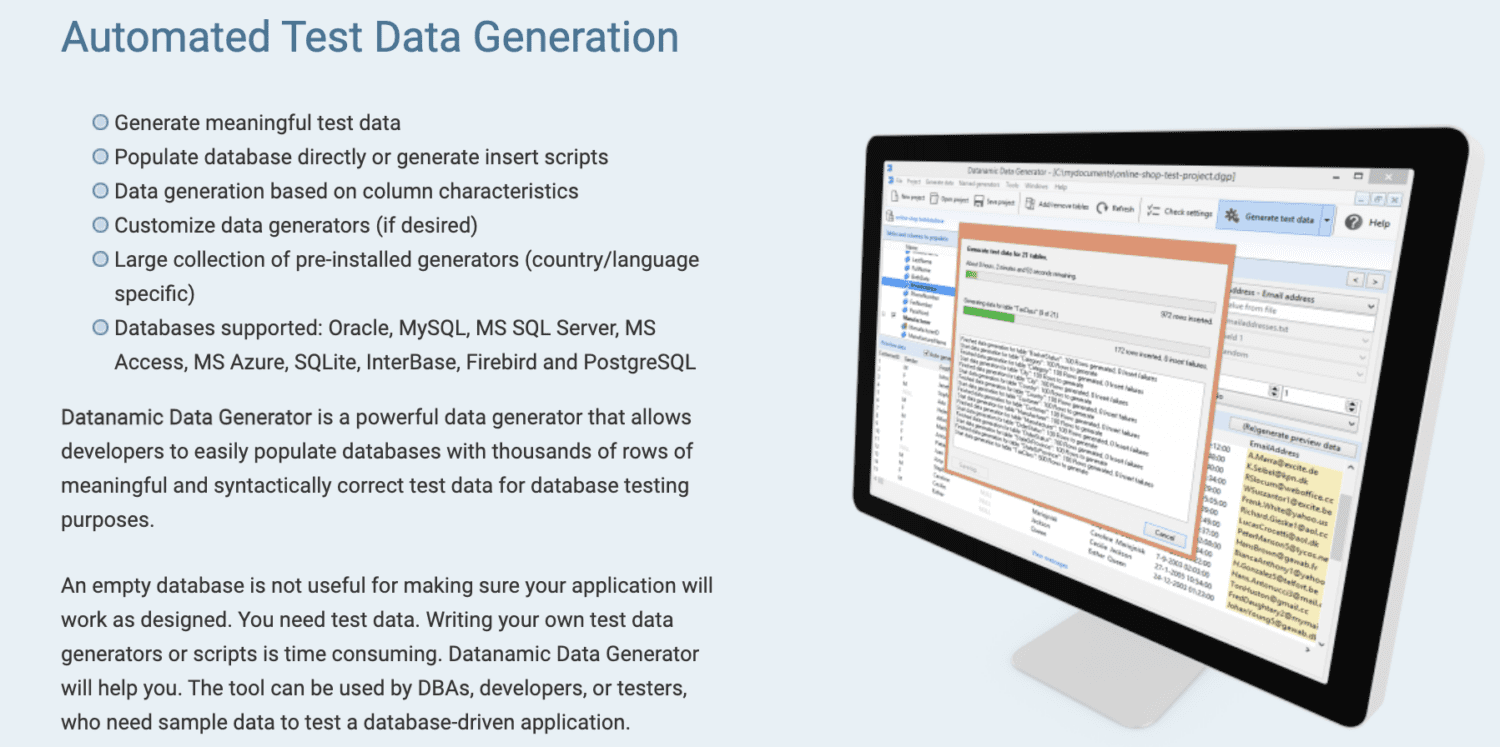
A Datanamic ajuda você a criar dados de teste para aplicativos orientados a dados e de aprendizado de máquina. Ele gera dados com base nas características da coluna, como email, nome e número de telefone.
Os geradores de dados Datanamic são personalizáveis e suportam a maioria dos bancos de dados, como Oracle, MySQL, MySQL Server, MS Access e Postgres. Ele suporta e garante a integridade referencial nos dados gerados.
Benerator
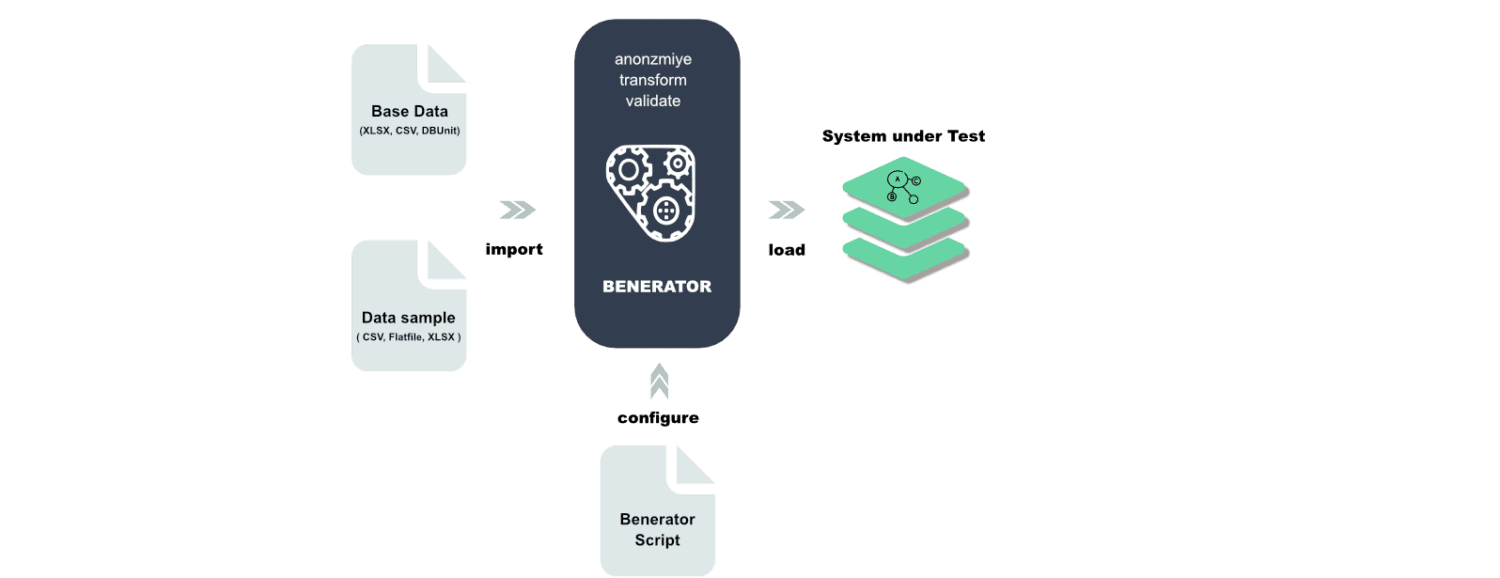
Benerator é um software para ofuscação, geração e migração de dados para fins de teste e treinamento. Usando Benerator, você descreve dados usando XML (Extensible Markup Language) e gera usando a ferramenta de linha de comando.
Ele foi feito para ser usado por não desenvolvedores e, com ele, você pode gerar bilhões de linhas de dados. O Benerator é gratuito e de código aberto.
Palavras Finais
A estimativa do Gartner é que, até 2030, haverá mais dados sintéticos usados para aprendizado de máquina do que dados reais.
Não é difícil entender por que, considerando o custo e as preocupações com a privacidade do uso de dados reais. É, portanto, necessário que as empresas aprendam sobre dados sintéticos e as diferentes ferramentas para ajudá-los a gerá-los.
A seguir, confira as ferramentas de monitoramento sintéticas para o seu negócio online.